首页 > 资源 > 文章详情
Vertex AI 中的 Gemini Live API 开发者指南

只需单一的 WebSocket 连接,即可为您的 AI 应用和智能体打造一种宛如真人的自然交互界面。
最近,我们宣布 Gemini Live API 正式上线 Vertex AI,该 API 基于最新的 Gemini 2.5 Flash Native Audio 模型。这远非一次简单的模型升级,而是代表着一个根本性的转变,即从僵硬的多阶段语音系统转变为统一、实时且懂情感的多模态对话架构。
我们怀着激动的心情,向开发者深入阐述这种转变对于构建新一代多模态 AI 应用的重大意义。在这篇博文中,我们将介绍两个模板和三个参考演示应用,助您掌握 Gemini Live API 的最佳使用方法。
Gemini Live API:您的全新语音基石
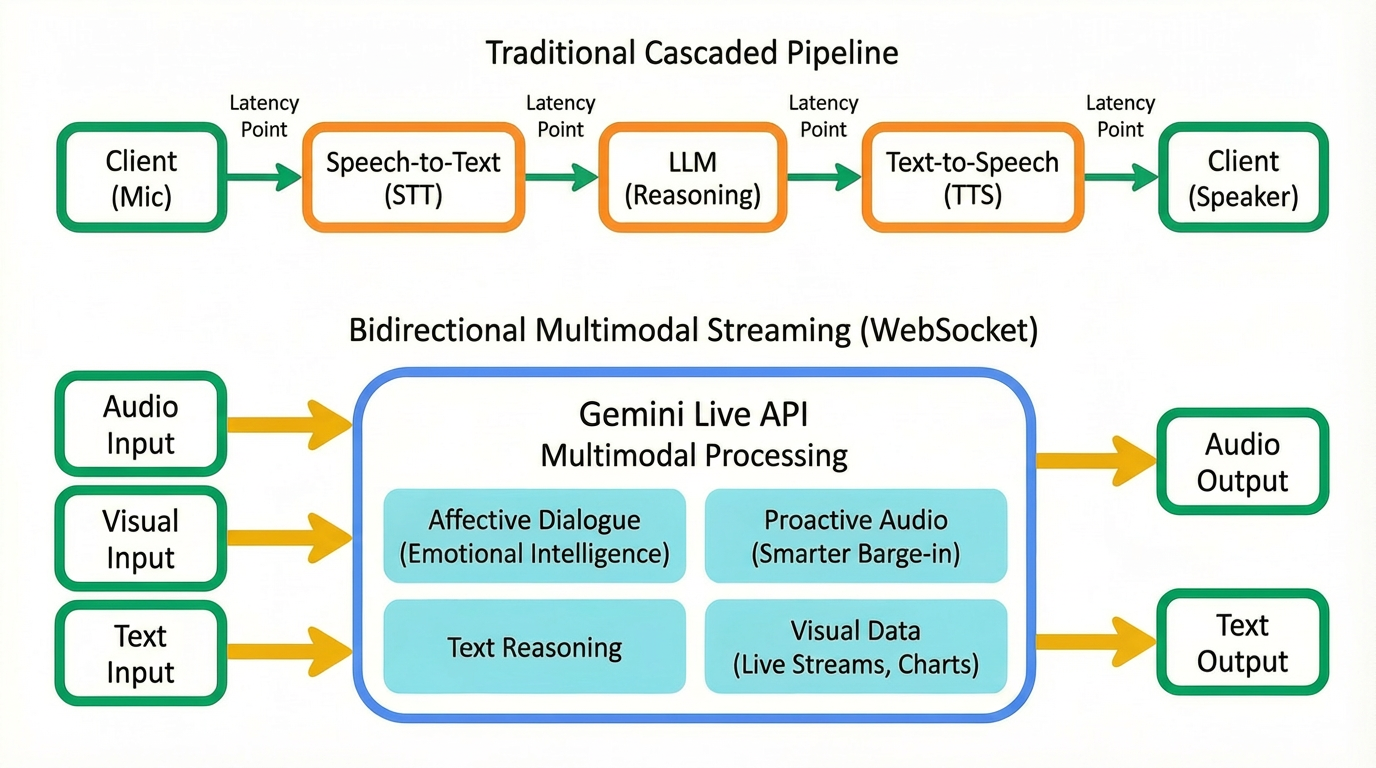
多年来,构建对话式 AI 意味着将语音转文字 (STT)、大语言模型 (LLM) 和文字转语音 (TTS) 拼接成一个高延迟的流水线。这种顺序处理方式导致机械的轮流发言和尴尬的延迟现象,总让人感觉对话不自然。
Gemini Live API 则采用统一的低延迟原生音频架构,从根本上改变了工程方法。
原生音频处理:Gemini 2.5 Flash Native Audio 模型通过单一低延迟模型对原始音频进行原生式处理。这种统一性是核心的技术创新,能极大减少延迟。
实时多模态:该 API 旨在实现对音频、文本和视觉模态的统一处理。您的智能体可以在聆听语音输入的同时,依据实时的视觉数据流(例如用户分享的图表或实时视频信息流),围绕相关主题进行对话。
新一代对话功能
Gemini Live API 提供了一套可直接在生产环境中使用的功能,树立了 AI 智能体的新标杆:
共情对话(高情商):通过对原始音频进行原生式处理,该模型可以解读语气、情绪和语速等微妙的声音细节差异。因此,智能体能够自动缓和紧张的客服通话气氛,或采用适当的共情语气予以回应。
主动式音频(智能打断):该功能超越了简单的语音活动检测 (VAD)。正如现场演示中所示,您可以配置智能体,让它智能判断何时回应以及何时保持沉默并积极聆听。这样可以避免在需要被动聆听时唐突打断对话,带来真正自然的互动体验。
使用工具:开发者可以将函数调用和依托 Google 搜索进行接地等工具无缝集成到这些实时对话中,让智能体能够根据语音和视觉输入立即提取实时世界知识并执行复杂操作。
连续记忆:智能体能够维持很长而且连续的覆盖所有模态的上下文。
企业级稳定性:正式版发布后,您的生产工作负载将享受高可用性保障,包括多区域支持,以确保您的智能体为全球用户提供积极且可靠的响应。
开发者快速入门:初学指南
开发者要想体验低延迟、实时音频的强大魅力,最快的方法是了解数据流。REST API 需要您在发出请求后等待,而 Gemini Live API 则与之不同,它需要管理双向流。
Gemini Live API 流程
在深入探究代码之前,必须先让您直观了解生产架构。虽然在原型设计阶段可以直接连接,但大多数企业应用都需要安全的代理流程:面向用户的应用 -> 您的后端服务器 -> Gemini Live API(Google 后端)。
在此架构中,您的前端捕获媒体(麦克风/摄像头)并将其流式传输到安全后端,然后由后端管理与 Vertex AI 中的 Gemini Live API 的持久 WebSocket 连接。这样可以确保敏感凭证永远不离开您的服务器,并允许您在数据流向 Google 之前注入业务逻辑、保持对话状态或管理访问权限控制。

为了帮助您快速入门,我们发布了两个不同的快速入门模板 - 一个有助于您理解原始协议,另一个则支持您基于现代组件进行开发。
选项 A:Vanilla JS 模板(零依赖)
最佳适用场景:了解原始的 WebSocket 实现和媒体处理方式,而没有任何框架开销。
此模板负责 WebSocket 握手和媒体流式传输,为您提供纯净的环境来构建自己的逻辑。
项目结构:
/ ├── server.py # WebSocket proxy + HTTP server └── frontend/ ├── geminilive.js # Gemini API client wrapper ├── mediaUtils.js # Audio/video streaming logic └── script.js # App logic |
核心实现:您通过有状态 WebSocket 连接与 gemini-live-2.5-flash-native-audio 模型进行交互。
const client = new GeminiLiveAPI(proxyUrl, projectId, model); // Connect using the access token handled by the proxy client.connect(accessToken); // Stream audio from the user's microphone client.sendAudioMessage(base64AudioChunk); |
运行 Vanilla JS 演示:
pip3 install -r requirements.txt gcloud auth application-default login python3 server.py # Open http://localhost:8000 |
请遵循分步视频演示进行操作。
专业提示:调试原始音频 PCM 原始音频流的处理可能很棘手。如果您需要验证音频块或测试 Base64 字符串,请使用代码库中提供的 PCM 音频调试器。
选项 B:React 演示(模块化和现代化)
最佳适用场景:构建具有复杂界面而且可用于生产用途的可伸缩应用。
如果您要构建稳健的企业应用,我们的 React 入门模板提供了一种模块化架构,它使用 AudioWorklets 完成高性能、低延迟的音频处理。
特性:
实时流式传输:利用 React 状态管理将音频和视频流式传输到 Gemini。
AudioWorklets:使用 capture.worklet.js 和 playback.worklet.js 运行专用音频处理线程。
安全代理:Python 后端负责 Google Cloud 身份验证。
项目结构:
/ ├── server.py # WebSocket proxy & auth handler ├── src/ │ ├── components/ │ │ └── LiveAPIDemo.jsx # Main UI logic │ └── utils/ │ │ ├── gemini-api.js # Gemini WebSocket client │ │ └── media-utils.js # Audio/Video processing └── public/ └── audio-processors/ # Audio worklets |
运行 React 演示:
# Terminal 1: Start the Backend pip install -r requirements.txt gcloud auth application-default login python server.py # Terminal 2: Start the Frontend npm install npm run dev # Open http://localhost:5173 |
请遵循分步视频演示进行操作。
合作伙伴集成
我们已完成与 Daily、Twilio、LiveKit 和 Voximplant 等第三方合作伙伴的集成,以简化特定电话或 WebRTC 环境中的开发流程。这些平台已通过 WebRTC 协议集成了 Gemini Live API,您可以直接将这些功能嵌入到现有的语音和视频工作流中,而不必亲自管理网络栈。
Gemini Live API:可在生产环境中运行的三个演示应用
使用任一模板奠定基础后,如何继续扩展为产品?我们构建了三个演示应用,以展现 Gemini Live API 的独特“超能力”。
1. 实时主动式顾问智能体
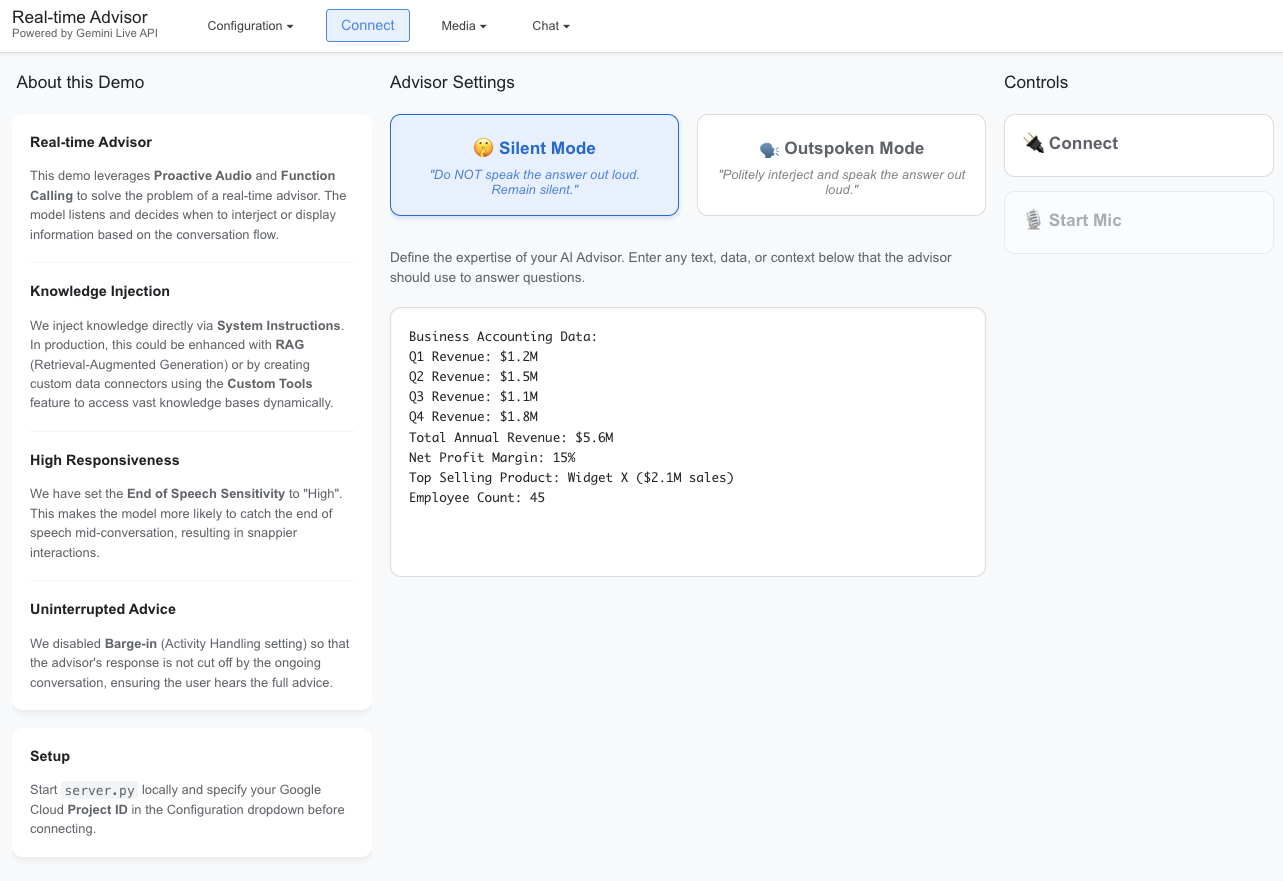
要构建真正自然的对话式 AI,核心在于打造一个合作伙伴,而不只是一个聊天机器人。这个专业应用演示了如何构建一个业务顾问,它会倾听对话并根据提供的知识库给出相关的分析洞见。
该顾问展现了专业智能体的两项关键能力:动态知识注入和双重交互模式。
场景:一个顾问参加商务会议。它有权访问用户在界面中定义的特定注入数据(收入统计数据、员工人数)。
双重模式:
○ 静默模式:顾问会认真倾听,并通过 show_modal 工具一言不发地“推送”视觉信息。如果您想要数据,而不被打断,则适合选择这种模式,它能够默默无闻地为您提供帮助。
○ 直言模式:顾问会礼貌地插话以给出建议,在语音回复的同时提供视觉数据。
打断控制:该演示应用使用 activity_handling 配置在必要时防止用户意外打断顾问发言,确保顾问完整表述复杂的建议。
使用工具:使用自定义的 show_modal 工具向用户显示结构化信息。
如需查看实现实时顾问智能体的完整源代码,请访问我们的 GitHub 代码库。
2. 多模态客户服务智能体
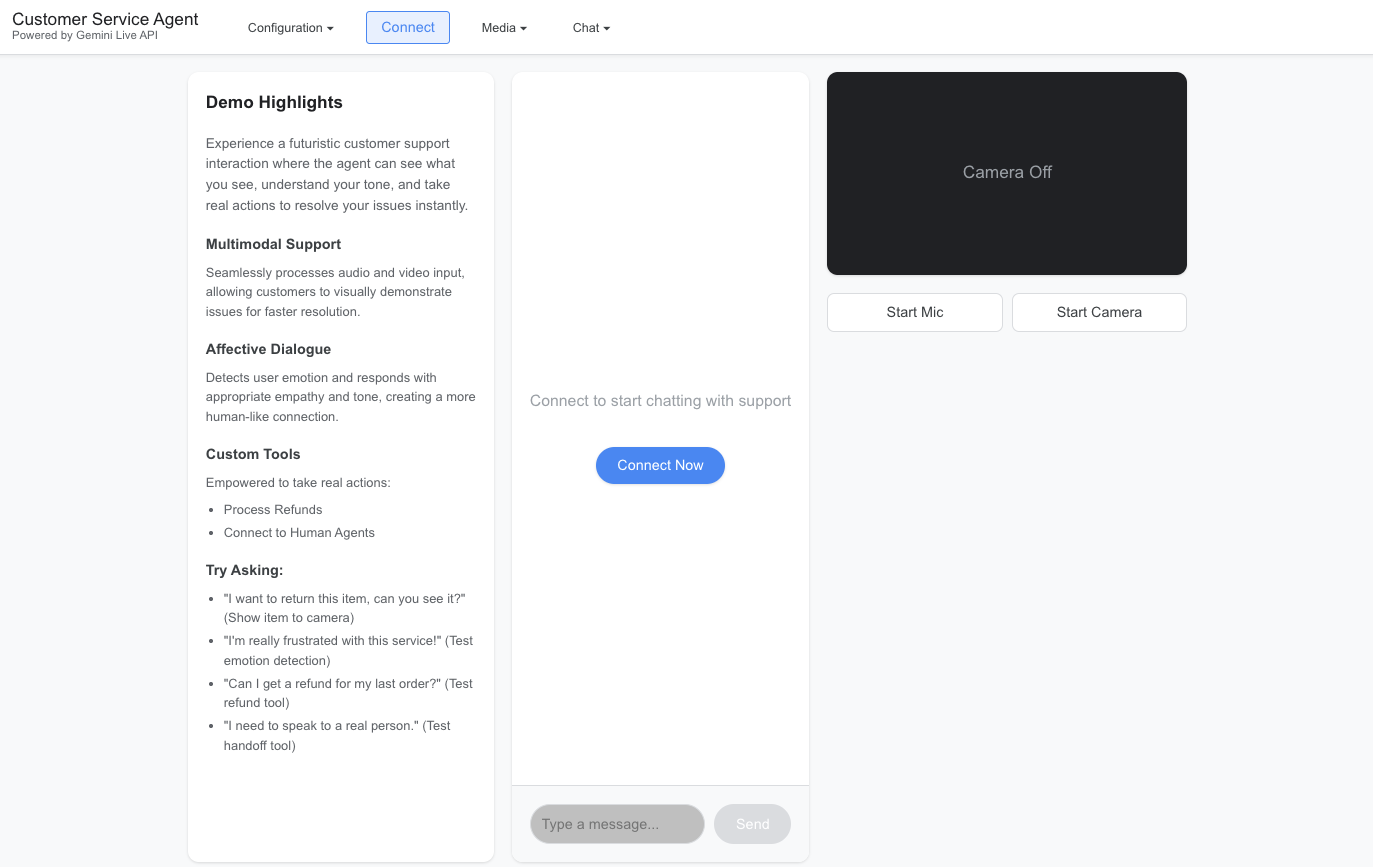
客户服务智能体必须能够依据自己的所见所闻提供服务。此演示应用在语音流中叠加了关联操作和共情对话,创造了一个可以即时解决问题的客服智能体。
此应用模拟了未来的客户服务互动场景,其中智能体能够看到您的所见、理解您的语气并采取实际行动即刻解决您的问题。用户无需描述要退回的商品,只需在摄像头前展示它即可。智能体会结合视觉输入与情感理解能力,从而推进实际的行动:
多模态理解:智能体在听取客户请求的同时,对客户展示的商品进行视觉检查(例如,验证待退回商品)。
共情式回应:智能体使用共情对话功能检测用户的情绪状态(沮丧、困惑),据此调整回应的语气,表现出适当的同理心。
采取行动和使用工具:它不仅能聊天,还能使用自定义工具(如处理交易 ID 的 process_refund 或移交复杂问题的 connect_to_human)来解决实际问题。
实时交互:通过 WebSocket 连接,使用 Gemini Live API 进行低延迟语音交互。
如需查看实现多模态客户服务智能体的完整源代码,请访问我们的 GitHub 代码库。
3. 电子游戏实时助手
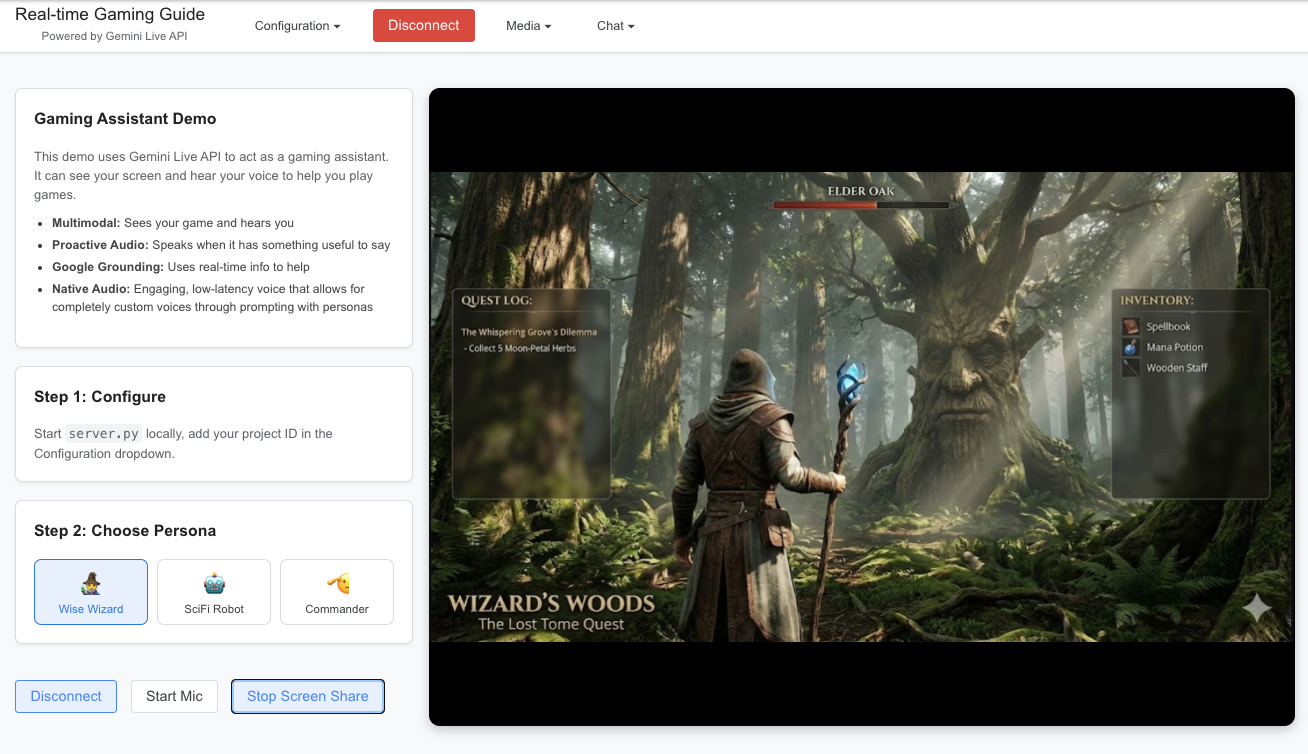
玩伴在旁,打游戏才更有趣。本演示应用中打造了一个实时游戏向导。它不仅限于简单的聊天,还能全程观战并根据您的风格自我调整,是一个真正的游戏玩伴。
此 React 应用将屏幕截图和麦克风音频同步传输到模型,使得智能体能够立即掌握游戏状态。它展现了三种高阶能力:
多模态感知:该智能体就像是第二双眼睛,通过分析屏幕画面发现您可能没看到的敌人、战利品或谜题线索。
角色切换:您可以动态切换智能体的角色,比如从提供隐晦指引的“睿智巫师”,切换到发布战术指令的“科幻机器人”或“指挥官”。由此可展现出系统指令如何立即改变助手的语气和风格。
Google 搜索接地:智能体通过提取实时信息,为您提供最新的攻略和技巧,确保您顺利通过新关卡。
如需查看实现电子游戏实时助手的完整源代码,请访问我们的 GitHub 代码库。
立即开始使用
立即试用:前往 Vertex AI Studio 体验 Gemini Live API
开始构建:即刻访问 Vertex AI 上的 Gemini Live API,别再局限于简单的聊天机器人,而是打造真正智能、响应迅速且富有同理心的用户体验。
获取代码:在我们的官方 GitHub 代码库中可以找到所有演示和快速入门资源。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们