首页 > 资源 > 文章详情
Google Cloud 网络深度解析:Protective ReRoute 如何提升网络韧性
可靠性是云基础设施的基石。然而,即便是最顶尖的全球网络也可能遭受一个关键问题的困扰:从路由中断中恢复缓慢或恢复失败。在 Google 这样超大规模的网络中,路由器故障或隐蔽的复杂状况可能会阻止传统路由协议快速恢复服务,有时甚至完全无法恢复。这些短暂但代价高昂的中断——我们称之为收敛缓慢 (slow convergence) 或收敛失败 (convergence failure)——会严重扰乱对丢包容忍度极低的实时应用。对于当今大规模、敏感的 AI/ML 训练作业而言,即使是短暂的网络抖动也可能浪费数百万美元的计算时间。
为了解决这个问题,我们创新发明了 Protective ReRoute (PRR)。这是一项根本性的转变,将快速故障恢复的任务从中心化的网络核心转移到了分布式的端点本身。自五年前投入生产环境以来,这种基于主机的机制显著提高了 Google 网络的韧性。事实证明,它能有效恢复高达 84%[1] 由收敛缓慢事件引起的数据中心间网络中断。拥有对丢包敏感工作负载的 Google Cloud 客户也可以在其环境中启用此功能——请继续阅读以了解更多信息。
网内 (In-network) 恢复的局限性
传统路由协议对网络运行至关重要,但它们往往不够快,无法满足现代实时工作负载的需求。当路由器或链路发生故障时,网络必须重新计算所有受影响的路由,这一过程称为重收敛 (reconvergence)。在 Google 这种规模的网络中,该过程可能会因拓扑规模而变得复杂,导致从数秒到数分钟不等的延迟。对于具有广泛扇出 (fan-out) 通信模式的分布式 AI 训练作业,即使是几秒钟的丢包也可能导致应用程序失败和昂贵的重启。这是一个规模问题:随着网络规模的扩大,这些复杂故障场景发生的可能性也随之增加。
Protective ReRoute:一种基于主机的解决方案
Protective ReRoute 是一个简单而有效的概念:赋予通信端点(主机)检测故障并将流量智能地重新引导至健康的并行路径的能力。PRR 不等待全局网络更新,而是利用我们网络中内置的丰富路径多样性。主机检测其当前路径上的丢包或高延迟,然后通过修改精心选择的数据包头字段立即发起路径变更,告知网络使用另一条预先存在的路径。
这种架构代表了网络可靠性思维的根本转变。传统网络依赖于并行和串联可靠性的结合。组件的串联往往会降低系统的可靠性;在具有多个转发阶段 (forwarding stages) 的大直径规模网络中,可靠性随着网络直径的增加而降低。换句话说,每个转发阶段都会影响整个系统。即使网络阶段设计了并行可靠性,在并行阶段重收敛期间,它也会对整个网络产生串联影响。通过在边缘添加 PRR,我们将网络视为一个表现为单阶段的高度并行路径系统,其中整体可靠性随着可用路径数量的指数增长而增加,从而有效地规避了大直径网络中缓慢网络收敛的串联效应。下图对比了启用 PRR 的网络与传统网络的系统可靠性模型。传统网络的可靠性与转发阶段的数量成反比;而使用 PRR,同一网络的可靠性与复合路径的数量成正比,这与网络直径成指数比例关系。
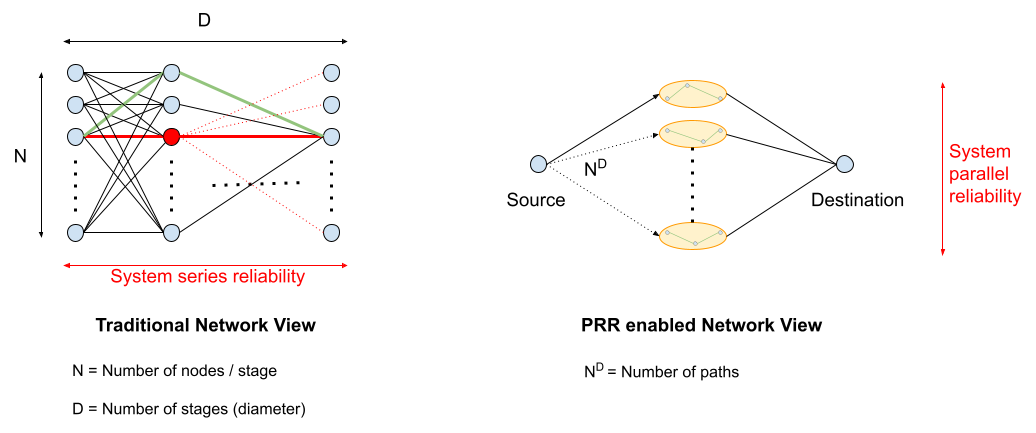
Protective ReRoute 的工作原理
PRR 机制包含三个核心功能组件:
端到端故障检测: 通信主机持续监控路径健康状况。在 Linux 系统上,标准机制使用 TCP 重传超时 (RTO) 来发出潜在故障信号。检测故障的时间通常是网络往返时间 (RTT) 的个位数倍。还有其他具有不同速度和成本的端到端故障检测方法。
主机端的数据包头修改:一旦检测到故障,发送主机将修改数据包头字段以影响转发路径。为了实现这一目标,Google 开创并贡献了在 Linux 内核(4.20+ 版本)中修改 IPv6 流标签 (flow-label) 的机制。至关重要的是,Google 软件定义网络 (SDN) 层通过在网络覆盖层 (overlay) 的外部头部执行检测和重新路径选择,也为 IPv4 流量和非 Linux 主机提供了保护。
PRR 感知转发:多路径网络中的路由器和交换机遵循此头部修改,并将数据包转发到另一条可用的、绕过故障组件的路径上。
影响验证
PRR 并非理论;它是一个持续部署的 7x24 小时系统,保护着全球的生产流量。其影响令人信服:PRR 已被证明可以将由收敛缓慢和收敛失败引起的网络停机时间减少高达前文提到的 84%。这意味着,原本由路由器故障或缓慢的网络级恢复引起的每 10 次网络中断中,有多达 8 次现在可以通过主机避免。此外,主机发起的恢复速度极快,通常在 RTT 的个位数倍时间内解决问题,这比传统的网络重收敛时间快得多。
超高可靠性网络的关键用例
受现代应用需求的驱动,对 PRR 的需求正在增长:
AI/ML 训练和推理:大规模工作负载,特别是那些分布在许多加速器 (GPU/TPU) 上的工作负载,对网络可靠性极其敏感。PRR 提供了必要的超高可靠数据分发,以保持这些高价值计算作业不间断运行。
数据完整性和存储:大量丢包不仅会导致吞吐量降低,还可能导致数据损坏和数据丢失。通过减少中断窗口,PRR 提高了应用程序性能并有助于保证数据完整性。
实时应用:游戏等应用以及视频会议和语音通话等服务无法容忍哪怕是短暂的连接中断。PRR 缩短了网络故障的恢复时间,以满足这些严格的实时要求。
频繁的短连接:依赖大量非常频繁的短连接的应用程序在网络即使短时间不可用时也可能会失败。通过缩短预期中断窗口,PRR 帮助这些应用程序可靠地完成其所需的连接。
为您的应用激活 Protective ReRoute
向基于主机的可靠性的架构转变对于 Google Cloud 客户来说是一项可获取的技术。核心机制是开放的,并且是主线 Linux 内核(4.20 及更高版本)的一部分。
您可以通过两种主要方式受益于 PRR:
Hypervisor (虚拟机管理程序) 模式:PRR 自动保护在 Google 数据中心之间运行的流量,无需更改任何客户机操作系统 (Guest OS)。Hypervisor 模式可以在个位数秒内为网络特定区域中具有中等扇出的流量提供恢复。
Guest (访客) 模式:对于具有高扇出且位于网络任何部分的关健、性能敏感型应用程序,您可以选择启用 Guest 模式 PRR,这能实现尽可能最快的恢复时间和最大的控制权。这是对要求苛刻的关键任务应用程序、AI/ML 作业和其他延迟敏感型服务的最佳设置。
要为关键应用程序激活 Guest 模式 PRR,请遵循文档中的指导,并准备好确何以下几点:
您的虚拟机运行现代 Linux 内核 (4.20+)。
您的应用程序使用 TCP。
应用程序流量使用 IPv6。对于 IPv4 保护,应用程序需要使用 gVNIC 驱动程序。
开始使用
Protective ReRoute 的可用性对各种 Google 和 Google Cloud 用户具有深远的影响。
对于拥有关键工作负载的云客户:评估并为对丢包敏感且需要最快恢复时间的应用程序(例如大规模 AI/ML 作业或实时服务)启用 Guest 模式 PRR。
对于网络架构师:重新评估您的网络可靠性架构。考虑设计丰富路径多样性的好处,并赋予端点智能绕过故障的能力,将您的模型从串联可靠性转变为并行可靠性。
对于开源社区:认识到主机级网络创新的力量。在所有主要操作系统中贡献并倡导类似的可靠性功能,从而为每个人创建一个更具韧性的互联网。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们