首页 > 资源 > 文章详情
打造您的专属轻量级 AI | Gemma 3 270M 设备端微调指南
Gemma 是一系列先进的轻量级开放模型,其技术底蕴与我们的 Gemini 模型一脉相承。它提供多种规模版本,任何人都可以在自己的基础设施上进行适配并运行。这种性能与可访问性的结合已带来超过 2.5 亿次下载量,衍生出面向各类任务和领域的 85,000 种社区变体。
无需昂贵的硬件,亦可打造高度专业化的自定义模型。Gemma 3 270M 体积小巧,可助您快速针对新用例进行微调,然后部署到设备上。既赋予您模型开发的灵活性,又使您可以轻松掌控这一强大工具。
为展示这一过程的简易性,本文将通过一个示例,带您训练一个专属模型,将文本翻译成表情符号,并在 Web 应用中进行测试。您甚至可以教会模型使用您在现实生活中特定表情符号使用习惯,从而打造一个专属表情符号生成器。欢迎在实时演示中亲自体验。
我们将引导您在一小时内完成创建特定任务模型的全流程。您将学习到如何:
1、微调模型: 使用自定义数据集训练 Gemma 3 270M,创建专属 "表情符号翻译器"
2、量化和转换模型: 优化模型以实现设备端推理,将其内存占用降低至 300MB 以下
3、在 Web 应用中部署: 使用 MediaPipe 或 Transformers.js 在简单的 Web 应用中运行客户端模型
第 1 步: 通过微调自定义模型行为
开箱即用的大语言模型 (LLM) 通常是 "多面手"。如果您让 Gemma 将文本翻译成表情符号,可能会得到预料之外的内容,比如一些闲聊用语。
提示:
请将以下文本翻译为 3-5 个表情符号的创意组合:"what a fun party (多么有趣的派对)"
模型输出 (示例):
当然!这是您的表情符号: 🥳🎉🎈
对于我们的应用来说,Gemma 仅需要输出表情符号。虽然您可以尝试复杂的 "提示工程",但要遵循特定的输出格式并让模型学习新知识,最可靠的方法是使用示例数据对其进行微调。因此,要让模型学会使用特定的表情符号,需要用包含文本与表情符合示例的数据集来进行训练。
提供的示例越多,模型的学习效果就越好,所以您可以通过让 AI 为同一个表情符号生成不同的文本短语,轻松提升数据集的 "丰富性"。为了增添趣味性,我们用流行歌曲和粉丝群体相关的表情符号进行了此项尝试:
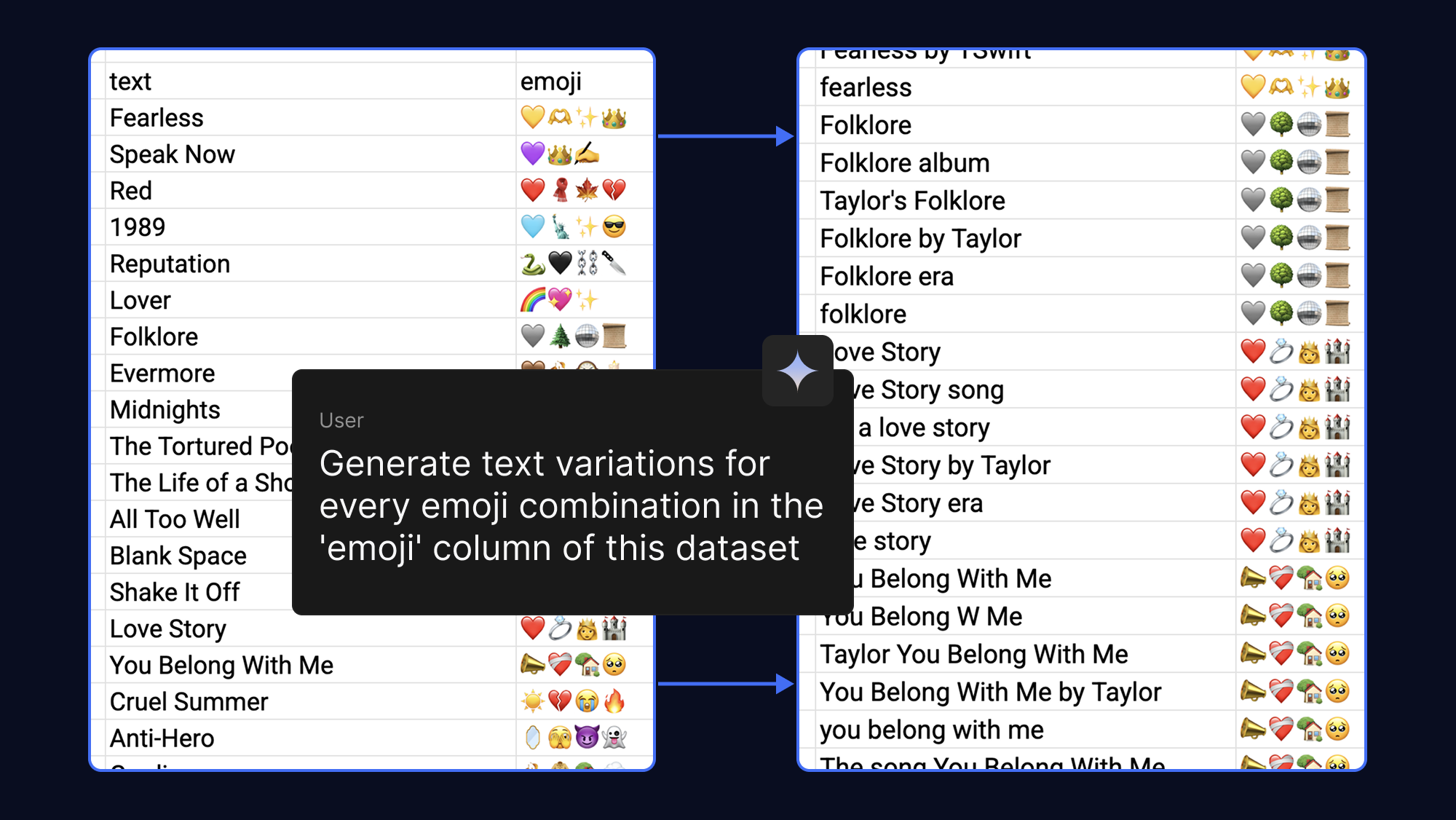
△ 如果您希望模型记住特定的表情符号,请在数据集中提供更多示例
过去,微调模型需要大量的 VRAM。然而,借助量化低秩适配 (QLoRA) 这种参数高效微调 (PEFT) 技术,我们只需更新少量权重。这大大降低了内存需求,使您能够在 Google Colab 上使用免费的 T4 GPU 加速,在几分钟内完成对 Gemma 3 270M 的微调。
您可以从一个示例数据集入手,或使用您自己的表情符号填充模板。然后,您可以运行微调 Notebook 来加载数据集、训练模型,并测试新模型相较于原始模型的性能表现。
第 2 步: 针对 Web 量化并转换模型
得到自定义模型后,您可以用它做什么呢?由于我们经常在移动设备或电脑上使用表情符号,所以我们通常选择将模型部署到设备端的应用中。
原始模型虽然很小,但仍然超过 1GB。为了确保快速加载的用户体验,我们需要压缩模型大小,而量化恰恰可以实现这一点,这是一种将模型权重的精度降低的过程 (例如,从 16 位降为 4 位整数)。这种方法能显著压缩文件大小,同时对模型性能的影响微乎其微。
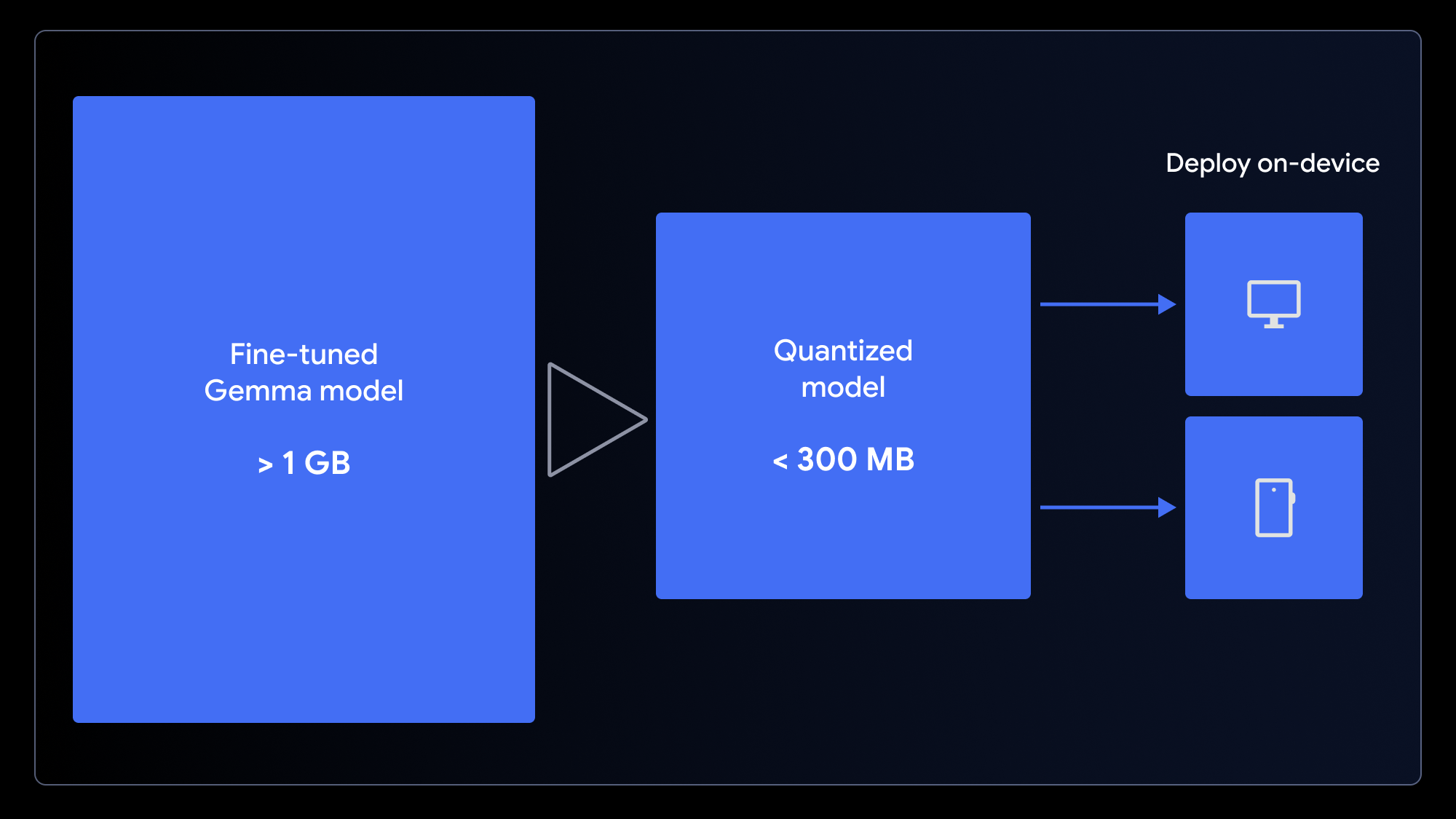
△ 模型越小,应用的加载速度就越快,最终用户的体验就越好
为使模型适配 Web 应用,您可以选择适用于 MediaPipe 的 LiteRT conversion notebook 或适用于 Transformers.js 的 ONNX conversion notebook,一步完成量化和转换。这些框架利用 WebGPU (一种现代 Web API,允许应用访问本地设备的硬件进行计算),支持在浏览器中以客户端方式运行 LLM,省去了复杂的服务器部署和每次调用的推理成本。
第 3 步: 在浏览器中运行模型
现在,您可以直接在浏览器中运行自定义模型!下载我们的示例 Web 应用,然后更改一行代码,便可轻松接入您的新模型。
MediaPipe 和 Transformers.js 都让这个过程变得十分简单。下面是一个在 MediaPipe 工作器中运行推理任务的示例:
// Initialize the MediaPipe Task const genai = await FilesetResolver.forGenAiTasks('https://cdn.jsdelivr.net/npm/@mediapipe/tasks-genai@latest/wasm'); llmInference = await LlmInference.createFromOptions(genai, { baseOptions: { modelAssetPath: 'path/to/yourmodel.task' } }); // Format the prompt and generate a response const prompt = prompt = `Translate this text to emoji: what a fun party!`; const response = await llmInference.generateResponse(prompt); |
模型一旦缓存至用户设备,随后的请求就会以极低的延迟在本地运行,用户数据将保持完全私密,而且即使在离线状态下,应用也能正常运行。
喜欢您的应用吗?那就把它上传到 Hugging Face Spaces 和我们一起分享吧 (就像演示示例一样)。
未来计划
您无需成为 AI 专家或数据科学家即可打造专属的 AI 模型。仅需几分钟,您就可以使用相对较小的数据集来优化 Gemma 模型的性能。
我们希望这些内容能激发您创造专属的模型变体。通过运用这些技术,您可以构建出强大的 AI 应用,不仅能满足个性化需求,还能带来卓越的用户体验——快速、私密,并且让任何人都能随时随地使用。
该项目的完整源代码和资源可以帮助您快速入门:
在 Colab 中使用 QLoRA 高效微调 Gemma
在 Colab 中转换 Gemma 3 270M 以用于 MediaPipe LLM 推理 API
在 Colab 中转换 Gemma 3 270M 以用于 Transformers.js
在 GitHub 上下载演示代码
参阅 Gemma Cookbook 和 chrome.dev,探索更多 Web AI 演示
详细了解 Gemma 3 模型系列及其设备端能力
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们