首页 > 资源 > 文章详情
超越孤岛,赋能智能:Google Cloud AI Lakehouse 如何重塑您的数据未来
在 AI 时代,数据是引擎,但对大多数企业而言,这个引擎正被数据孤岛、复杂的工具链和缓慢的洞察周期所拖累。数据工程师在繁琐的 ETL 中筋疲力尽,数据科学家因数据准备不足而束手无策,业务团队则因报表延迟而错失良机。这使得 AI 计划往往雷声大雨点小,难以规模化。正如一句老话所说,“你无法在一个破碎的数据地基上,构建一个可靠的 AI 未来。”
为了应对这一挑战,Google Cloud 推出了下一代 AI Lakehouse 解决方案。它不仅仅是一个数据仓库或数据湖的简单组合,而是一个专为 AI 时代设计的,集开放性、高性能、统一治理和原生智能于一体的综合数据平台。本文将深入探讨 Google Cloud AI Lakehouse 的核心理念、关键组件及其如何帮助企业将数据雄心转化为业务现实。
核心理念:一个为 AI 而生的开放式数据湖仓 (Open Data Lakehouse)
传统的分析架构往往在数据仓库(用于结构化数据分析)和数据湖(用于存储海量原始数据)之间形成壁垒。这种分离导致了数据冗余、治理复杂和分析效率低下,严重阻碍了 AI 应用的开发。当数据被锁在特定的格式或工具中时,团队协作变得困难,创新也因此受到束缚。
Google Cloud 的 AI Lakehouse 旨在彻底打破这些壁垒,其核心理念根植于三大支柱:
打破数据边界:无论数据存储在 BigQuery 原生存储中,还是以 Apache Iceberg 等开放格式存在于 Google Cloud Storage(GCS)上,都能通过统一的平台进行访问和管理,无需数据迁移或复制。这意味着数据可以“原地”被分析,从而形成一个无摩擦的协作环境和企业级的单一事实来源。
激活数据全部潜力:提供无与伦比的性能,让企业能够无限制地进行分析、运营和创新。这不仅关乎查询速度,更关乎处理海量多模态数据(文本、图片、音视频)并从中实时提取价值的能力,从而驱动更智能的业务决策。
普及 AI 驱动的洞察:将 Gemini 等前沿 AI 模型深度集成到数据生命周期的每个环节,让从数据工程师到业务用户的每个人都能轻松使用 AI。目标是让 AI 像 SQL 一样,成为数据工作者触手可及的基础能力,将他们的工作从“做什么”提升到“为什么做”。
架构概览:统一与开放的完美结合
Google Cloud AI Lakehouse 的架构设计巧妙地将各个功能层协同起来,充分体现了其开放性和统一性。
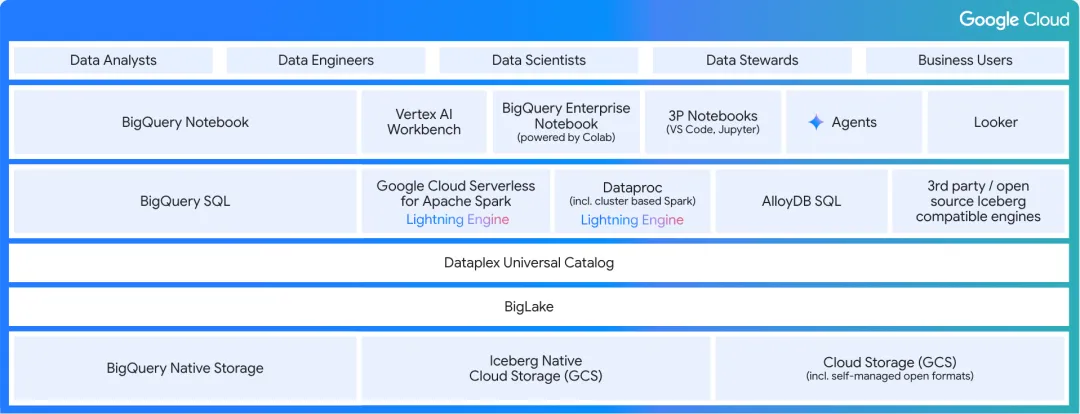
Google Cloud AI Lakehouse 架构图
存储层(Storage):底层由 BigQuery Native Storage 和基于 GCS 的 Iceberg Native Cloud Storage 构成,支持托管和自管理的开放格式,为数据提供了灵活且经济高效的存储选项。
统一管理层(Unified Management):BigLake 是整个架构的核心,它作为一个统一的控制平面,允许用户以一致的方式管理和访问所有数据,无论其物理位置或格式如何。
多引擎处理层(Multi-Engine Processing):平台支持多样化的计算引擎,包括 BigQuery SQL、Google Cloud Serverless for Apache Spark(搭载革命性的 Lightning Engine)、Dataproc 和 AlloyDB SQL,确保用户可以使用最适合其工作负载的工具。
统一治理层(Unified Governance):Dataplex Universal Catalog 为从数据到 AI 模型的整个生命周期提供全面的治理能力,确保数据的可信、安全和合规。
体验层(Experience):面向不同角色提供丰富的工具,包括 BigQuery Notebook、Vertex AI Workbench、Looker 以及创新的 Data Agents,极大地提升了数据团队的生产力。
这些层次的无缝集成,确保了数据在整个平台内能够自由、安全、高效地流动,为上层 AI 应用提供了坚实可靠的保障。
三大核心引擎:解锁极致性能、原生智能与无限开放性
BigLake:数据湖仓的“通用护照”
BigLake 是实现开放式湖仓的关键。您可以把它想象成一本数据的“通用护照”,让数据可以在不同的计算引擎(国家)之间自由穿行,而无需繁琐的数据复制和 ETL(签证)流程。它创建了一个虚拟层,将 BigQuery 强大的企业级功能(如精细的权限控制、高性能查询和 AI/ML 集成)扩展到 GCS 上的开放数据格式(如 Iceberg、Delta Lake、Parquet)。这意味着:
真正的互操作性:数据只需存储一次,就可以被 BigQuery、Spark、Trino 等多种引擎无缝访问和分析。这不仅节省了大量的存储成本,也杜绝了因数据副本不一致而导致的分析错误。
一致的治理:通过与 Dataplex 的集成,所有访问请求都遵循统一的安全和治理策略。无论您使用哪种工具,数据的访问权限和审计日志都集中管理,大大简化了合规工作。
避免厂商锁定:企业可以自由选择最适合的工具,同时保留对数据的完全控制权。您的数据以开放格式存储,未来可以轻松接入任何支持这些格式的新技术,确保了技术栈的灵活性和未来发展的可持续性。
BigQuery:不仅仅是数据仓库,更是 AI 平台
作为 Google Cloud 数据战略的核心,BigQuery 已经进化为一个集分析与 AI 于一体的超级平台。
内置 AI,而非“外挂”:
BigQuery ML:允许用户使用简单的 SQL 语句直接在 BigQuery 中训练和部署预测性和生成式 AI 模型。例如,营销团队无需数据科学家的帮助,仅用几行 SQL 就能构建一个客户流失预测模型。
多模态向量搜索(Vector Search):支持对文本、图像等非结构化数据的向量嵌入进行高效的相似性搜索,是构建高级 RAG(检索增强生成)应用的基础。这使得您可以构建能够理解产品手册、客户评论甚至设计图纸的智能客服或搜索应用。
AI Query Engine(预览版):由 Gemini 驱动,让用户可以在 SQL 查询中使用自然语言来处理和分析多模态数据,例如直接提问“这张广告图片中包含了哪些产品?”或者“总结一下上个季度所有关于‘电池续航’的负面客户评论”。
为性能而生的多引擎架构:
BigQuery Advanced Runtime:通过先进的运行时优化,能够在无需用户干预的情况下,将复杂分析查询的性能提升高达 200 倍。
Serverless Spark with Lightning Engine:Google Cloud 的下一代 Spark 性能引擎 Lightning Engine,通过向量化查询执行和智能缓存,实现了比开源 Apache Spark 快 4.3 倍的惊人性能,同时显著降低了资源消耗。这不仅仅是速度的提升,更意味着过去需要数小时才能完成的复杂分析任务,现在可以在几分钟内完成,从而极大地加速了从数据到决策的周期。
Dataplex:从“数据治理”到“AI 治理”
随着 AI 模型的广泛应用,治理的范畴也从传统的数据表扩展到了 AI 特征、模型和 Notebook。Dataplex Universal Catalog 正是为应对这一“治理危机”而生,它将治理从被动的“规则手册”转变为主动的“智能向导”。
通用性(Universal):自动发现和编目 Google Cloud 内外的所有数据和 AI 资产,包括基于 Iceberg 的开放湖仓,消除治理盲点。
AI 赋能(AI-powered):利用 AI 自动生成元数据(如表和列的描述)、提供自然语言搜索能力(例如,搜索“显示中国地区包含 PII 的客户表”),并主动推荐数据洞察。
智能化(Intelligent):Dataplex 不仅仅是元数据的存储库,它通过构建一个“知识引擎”(Knowledge Engine),分析查询历史、元数据和数据剖析结果,自动推断数据间的关系和业务语义。这为 AI Agent 提供了可靠的上下文,确保其生成的结果既准确又可信。
Agentic AI:开启数据交互的新纪元
为了进一步解放数据团队的生产力,并让数据洞察惠及企业中的每一个人,Google Cloud 引入了“Agentic AI”的理念,推出了一系列 Data Agents。您可以将这些智能体想象成一个为您每个数据角色配备的“智能副驾”或“数字专家团队”。他们不是简单地执行命令,而是能理解您的意图,主动协作并自动化完成整个数据生命周期中的复杂工作。

这些强大 Agent 的背后,是 Dataplex 中一个关键的大脑——知识引擎(Knowledge Engine)。这是 Dataplex Universal Catalog 中的一个核心模块,其根本任务是将静态的元数据记录,转变为一个动态的、具备上下文感知的“知识网络” (living, context-aware knowledge fabric)。
它不再是被动地存储元数据,而是主动地分析和连接来自整个 Google Cloud 数据与 AI 技术栈的信号。它所“消化”的输入包括:
来自 Data Profile 的模式分布和统计数据。
来自 Data Quality 的有效性和新鲜度结果。
来自 Business Glossary 的企业术语定义。
以及数据血缘(Lineage)、查询日志(Usage histories)和元数据注解。
知识引擎将来自 BigQuery、Spanner、AlloyDB、Cloud SQL、Vertex AI 和 Looker 的信息编织在一起,构建了一个覆盖从事务型数据库到分析型仓库,再到 AI 模型的全景图。
最终,它构建出一个动态的企业“知识图谱”。这使 Dataplex 从一个静态的资产注册表(static registry)进化为一个动态的关系构建者(dynamic relationship builder)。这个知识图谱的核心目的,就是为 Agentic AI 提供必要的“锚定”上下文(grounding context)。
知识引擎通过以下方式,将 Data Agents 从“工具”提升为“伙伴”:
提供准确的上下文:当 Agent 接收到一个模糊的请求,如“分析上季度的客户流失情况”时,知识引擎会提供必要的上下文:它知道哪些表是“客户主数据”,哪个字段代表“最后活跃日期”,以及业务上如何定义“流失”。这为 Agent 的行动提供了坚实的基础,有效避免了 AI 模型常见的“幻觉”问题,确保其响应是基于事实的。
实现复杂的推理:基于知识图谱,Agent 能够理解并执行跨领域、多步骤的复杂任务。例如,用户可以提出“找出在最近一次营销活动中,对高利润产品反应最积极的客户群体,并分析他们的共同特征”,Agent 能够自主地关联营销、销售和产品数据,完成这一系列复杂的分析。
确保内置的安全性与合规性:由于知识引擎本身就是 Dataplex 治理框架的一部分,它对所有数据安全策略(如 IAM 策略、PII 标识)都有全面的认知。因此,当一个业务分析师尝试查询包含敏感客户信息的字段时,即使他没有明确意识到,Agent 也会在生成结果前自动应用数据脱敏规则,只展示聚合后的、符合隐私政策的数据。这实现了安全于无形,让数据民主化与合规性并行不悖。
有了知识引擎的加持,Data Agents 才能真正发挥其潜力:
Data Engineering Agent:过去,数据工程师可能需要几天时间编写和调试复杂的 Spark 作业。现在,他们只需告诉 Agent:“将 Salesforce 的客户数据和 SAP 的订单数据进行合并,按季度聚合销售额,并将结果加载到 BigQuery 的‘quarterly_sales’表中”,Agent 就能自动生成、优化并执行整个数据管道。
Data Science Agent:数据科学家不再需要手动进行繁琐的探索性数据分析(EDA)和特征工程。他们可以指示 Agent:“针对这份客户数据,进行 EDA 分析,找出与客户流失最相关的特征,并构建一个初步的预测模型”,Agent 将自动完成数据可视化、特征选择和模型训练,并返回一份详尽的报告。
Conversational Analytics Agent:业务用户能以对话的方式探索数据、获取洞察、进行根本原因分析甚至预测未来趋势,真正实现数据的全民化。例如,销售总监可以直接在聊天界面中提问:“对比上个季度,我们哪个产品的销售额增长最快?根本原因是什么?”Agent 会自动查询数据、分析趋势并给出基于数据的合理解释。
这些植根于可信知识的 Agent,标志着人与数据交互方式的一次革命性飞跃。
结论:构建面向未来的数据战略
Google Cloud AI Lakehouse 提供了一个清晰的蓝图,帮助企业应对 AI 时代的复杂数据挑战。它通过一个统一、开放、智能和 Agentic 的平台,不仅解决了当前的数据孤岛和治理难题,更为未来的创新奠定了坚实的基础。
在这个 AI 决定未来的时代,您的数据战略就是您的 AI 战略。选择正确的平台,将不再是让数据服务于工具,而是让智能服务于业务的每一个角落。选择 Google Cloud AI Lakehouse,意味着您选择的不仅是一个解决当下数据问题的平台,更是一个能够与您的 AI 雄心共同成长、不断进化的智能基础。它将帮助您在 AI 时代,始终领先一步。与其让数据复杂性定义您的业务边界,不如让 Google Cloud AI Lakehouse 成为您创新的起点。是时候打破壁垒,拥抱智能,与我们一起构建您的 AI 未来。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们