首页 > 资源 > 文章详情
利用智能体与 AI 原生基础架构重新定义企业数据
世界不仅在变化,更被数据和 AI 实时重塑。我们与数据交互的方式正在经历一场根本性的变革,从人类主导的分析转向与智能体的协作伙伴关系。这就是 “智能体转变”(agentic shift),一个全新的时代,专业的 AI 智能体能够自主协作,以前所未有的规模和速度解锁洞察。在 Google Cloud,我们不仅仅是这场变革的参与者,我们还在构建驱动这场变革的核心智能、互联生态系统以及 AI 原生数据平台。
为了让这种智能体愿景成为现实,您需要一个不同类型的数据平台——不是一堆孤立工具的集合,而是一个单一、统一、AI 原生的云平台。这就是 Google Data Cloud。其核心是我们统一的分析和运营引擎,它们正在消除业务事务数据和战略分析之间的历史性鸿沟。Google Data Cloud 为智能体提供对业务的完整、实时的理解,将其从一堆流程转变为一个具有自我意识、自我调整且可靠的组织。
今天,我们正在三个关键领域实现重大创新,以实现这一愿景:
1、一套新的数据智能体:专门的 AI 智能体,旨在充当每个数据用户的专家合作伙伴,从数据科学家和工程师到业务分析师。
2、用于智能体协作的互连网络:一套 API、工具和协议,允许开发人员将 Google 智能体与他们自己的智能体和 AI 举措集成在一起,从而创建一个单一、智能的生态系统。
3、统一的 AI 原生基础架构:一个通过统一数据、提供持久记忆和嵌入 AI 驱动的推理能力来赋能智能体的平台。
作为专家伙伴的专业数据智能体
智能体时代始于一支由专业 AI 智能体组成的新队伍,他们提供 AI 原生界面,将意图转化为行动。
面向数据工程师:我们在 BigQuery 中推出了数据工程智能体(Data Engineering Agent)预览版,旨在简化和自动化复杂的数据管道。现在,您可以使用自然语言提示来简化整个工作流程,从 Google Cloud Storage 等来源提取数据,到执行转换并维护数据质量。只需描述您的需求——“创建一个管道来加载 CSV 文件,清理这些列,并将其与另一个表连接起来”——智能体就会生成并协调整个工作流程。

图 1 - 用于复杂数据管道自动化的数据工程智能体
面向数据科学家:我们正在重新构想 BigQuery 和 Vertex AI 中 AI 优先的 Colab Enterprise Notebook 体验,并推出全新的数据科学智能体(Data Science Agent)预览版。该数据科学智能体由 Gemini 提供支持,可触发完整的自主分析工作流程,包括探索性数据分析 (EDA)、数据清理、特征工程、机器学习预测等等。它可以创建计划、执行代码、推理结果并呈现其发现,同时允许您提供反馈并同步协作。
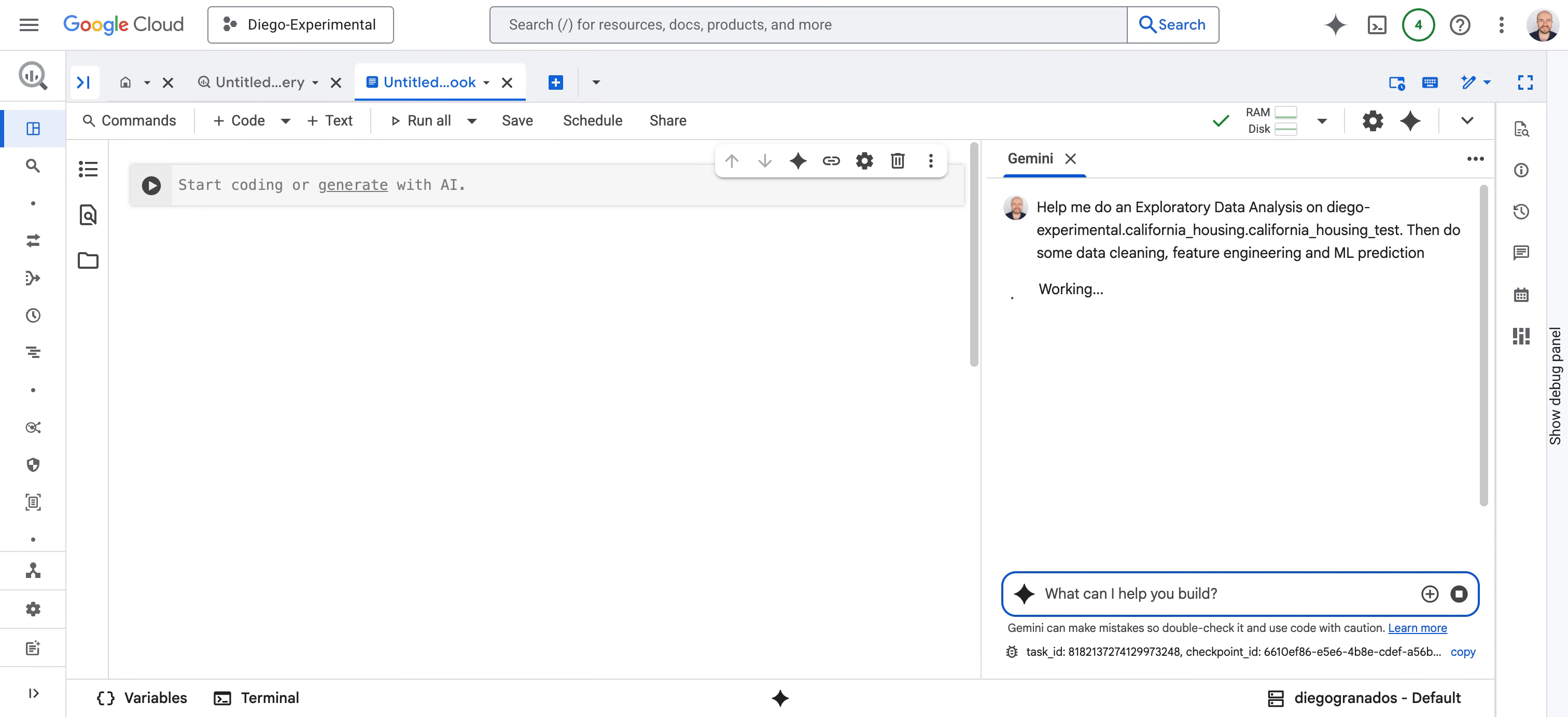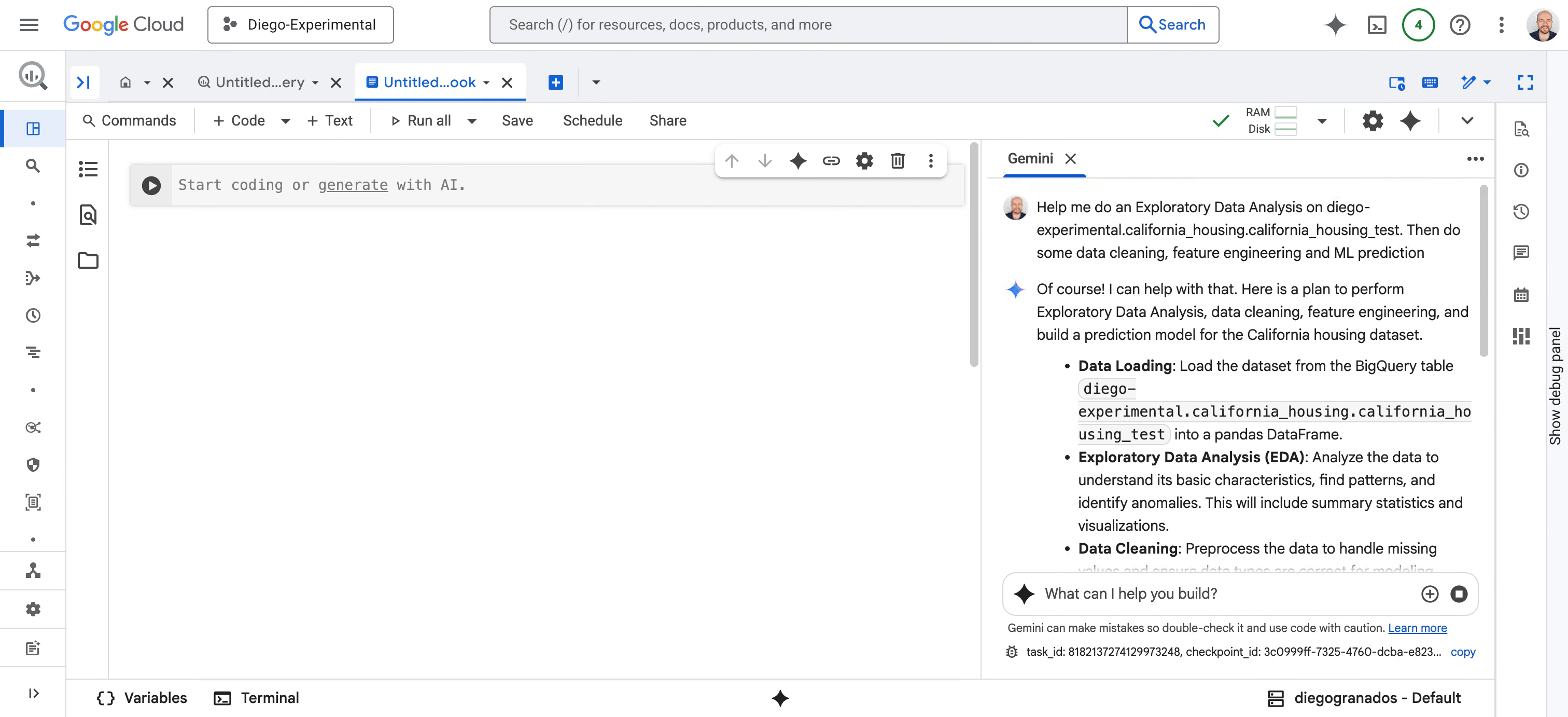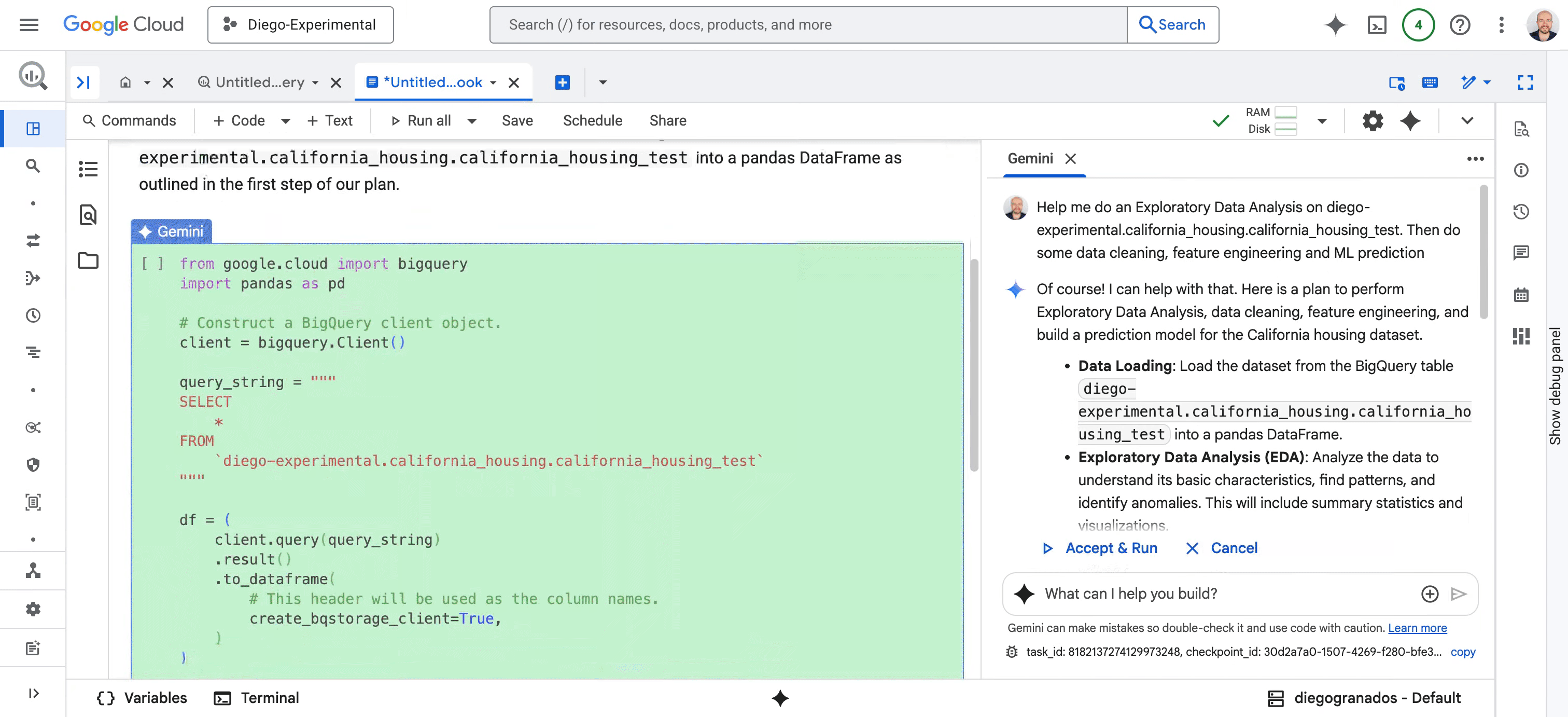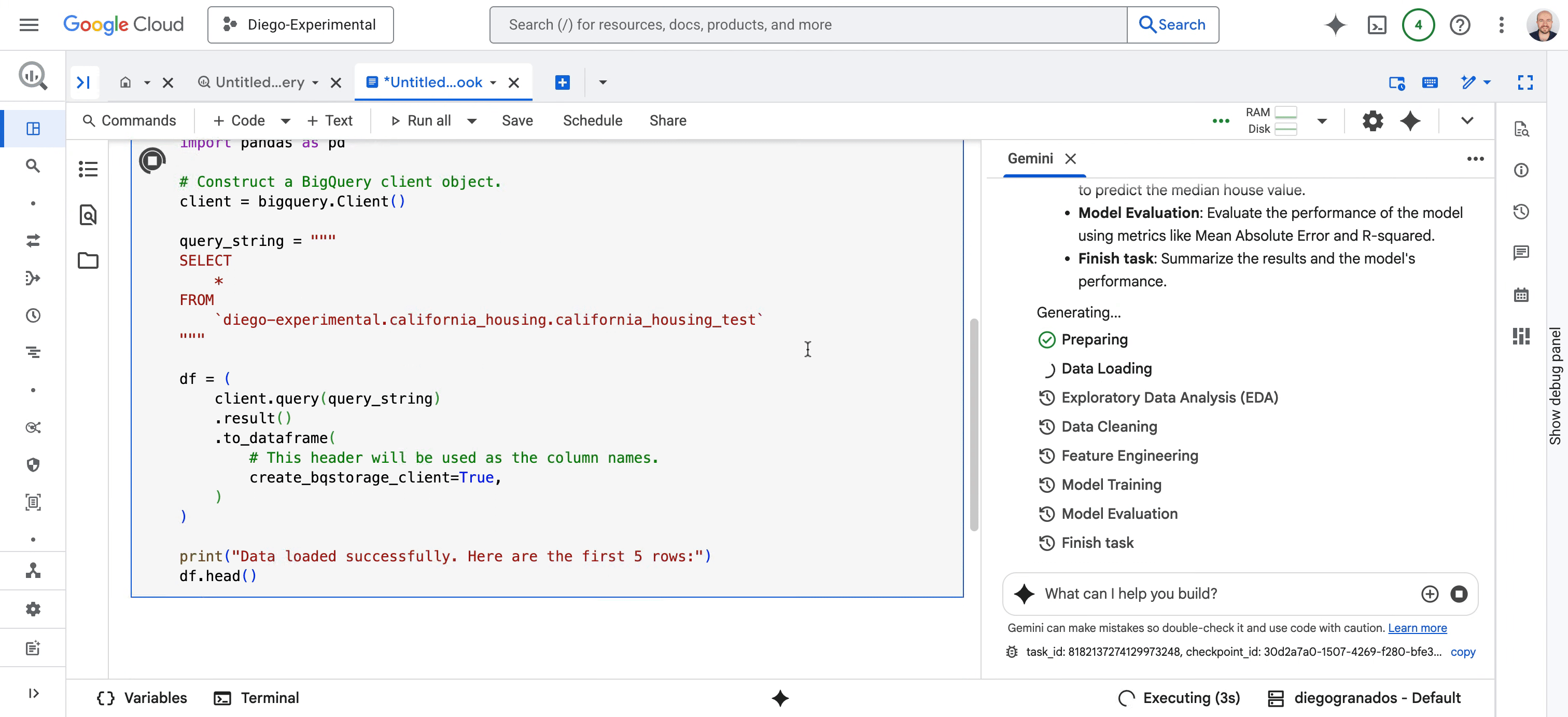
图 2 - 数据科学智能体转换数据科学任务的每个阶段
面向业务用户和分析师:去年,我们推出了对话式分析智能体 (Conversational Analytics Agent),使用户能够使用自然语言从数据中获取答案。今天,我们通过代码解释器(Code Interpreter)预览版将该智能体提升到新的水平。这项增强功能支持许多关键业务问题,这些问题超出了简单的 SQL 所能解答的范围——例如,“执行客户分群分析,将客户划分为不同的群组?”代码解释器由 Gemini 的高级推理功能提供支持,并与 Google DeepMind 合作开发,能够将复杂的自然语言问题翻译成可执行的 Python 代码。它提供完整的分析流程——生成代码、提供清晰的自然语言解释以及创建交互式可视化——所有这些都在 Google Data Cloud 受管控且安全的环境中完成。
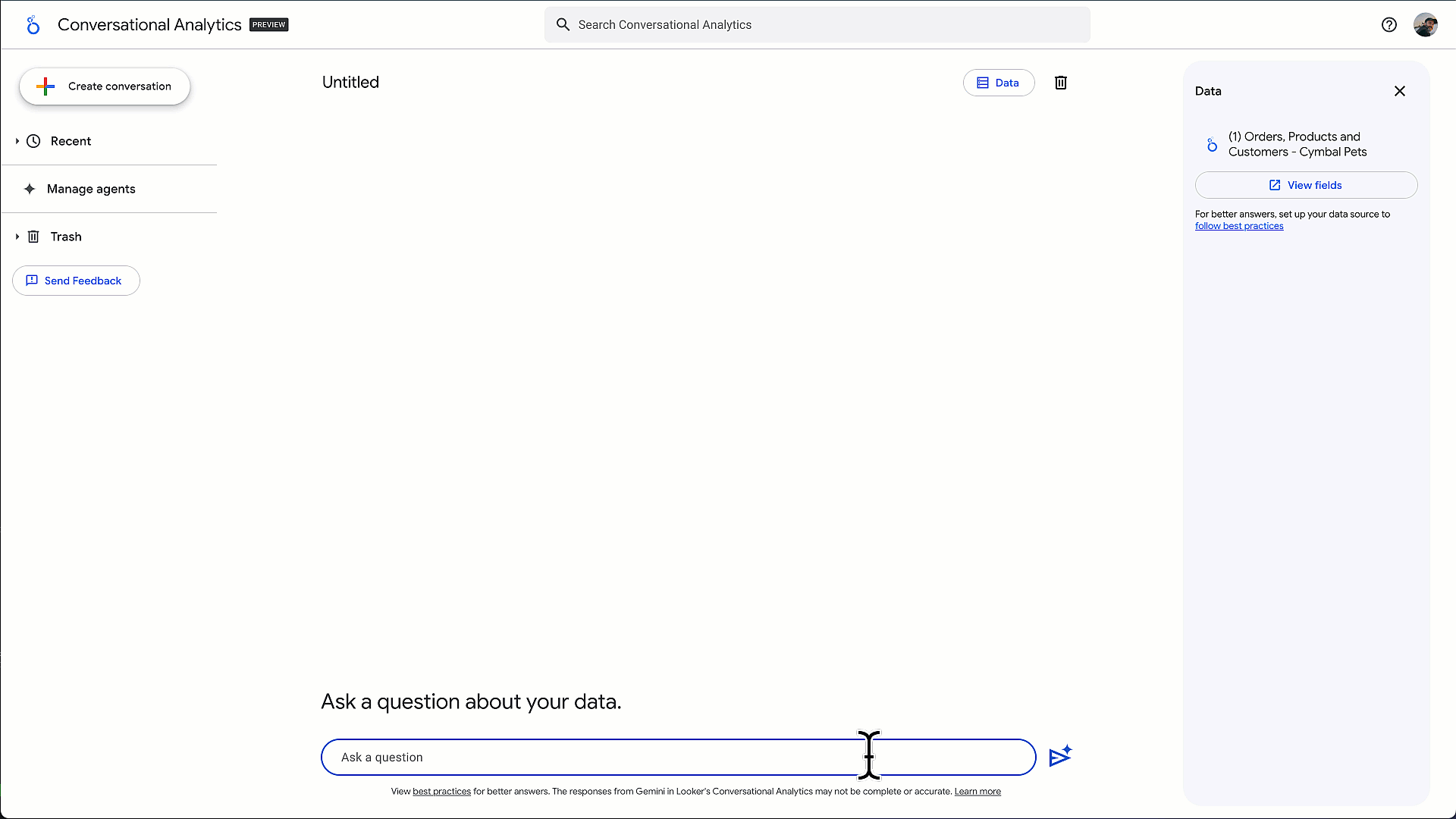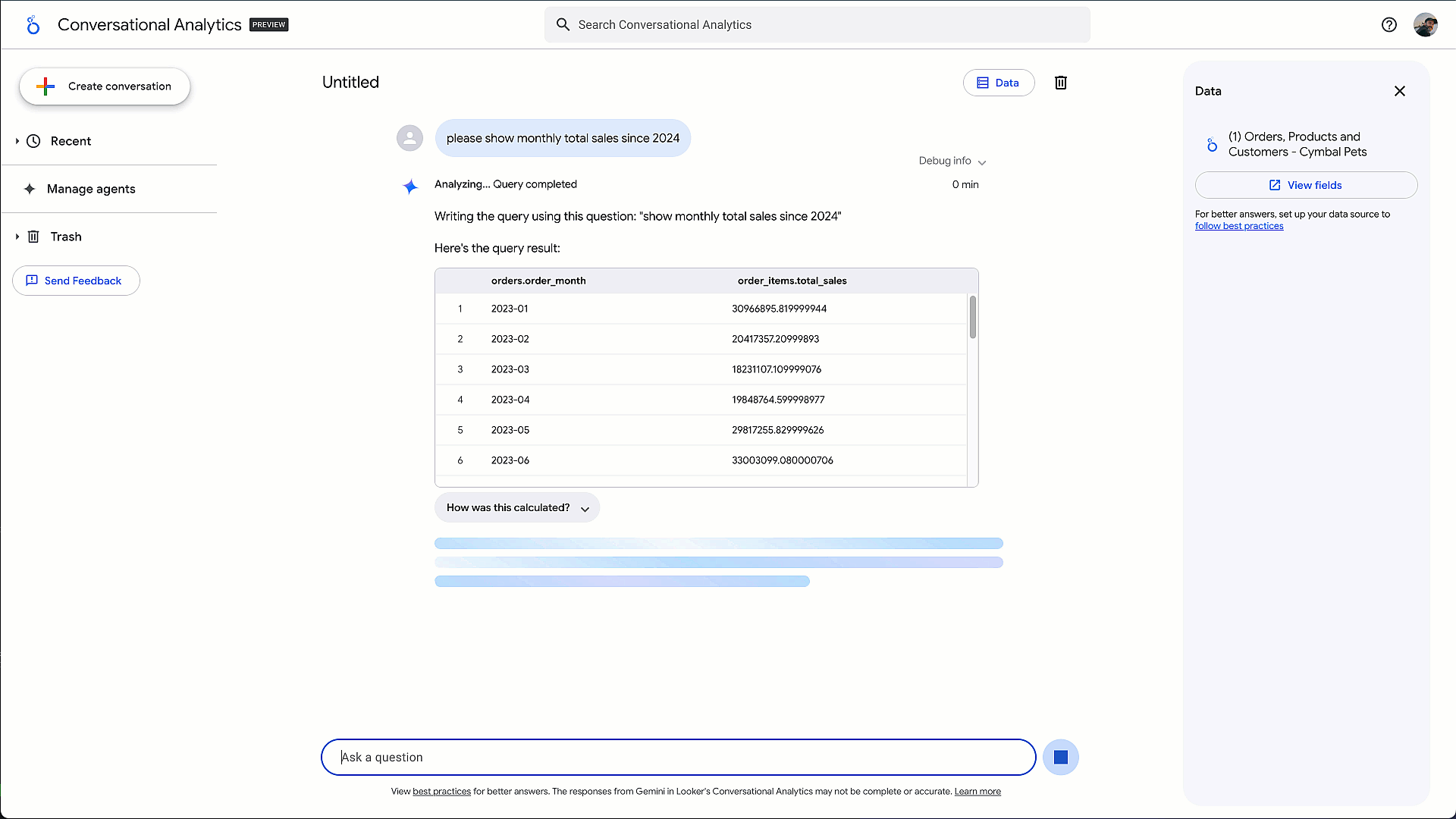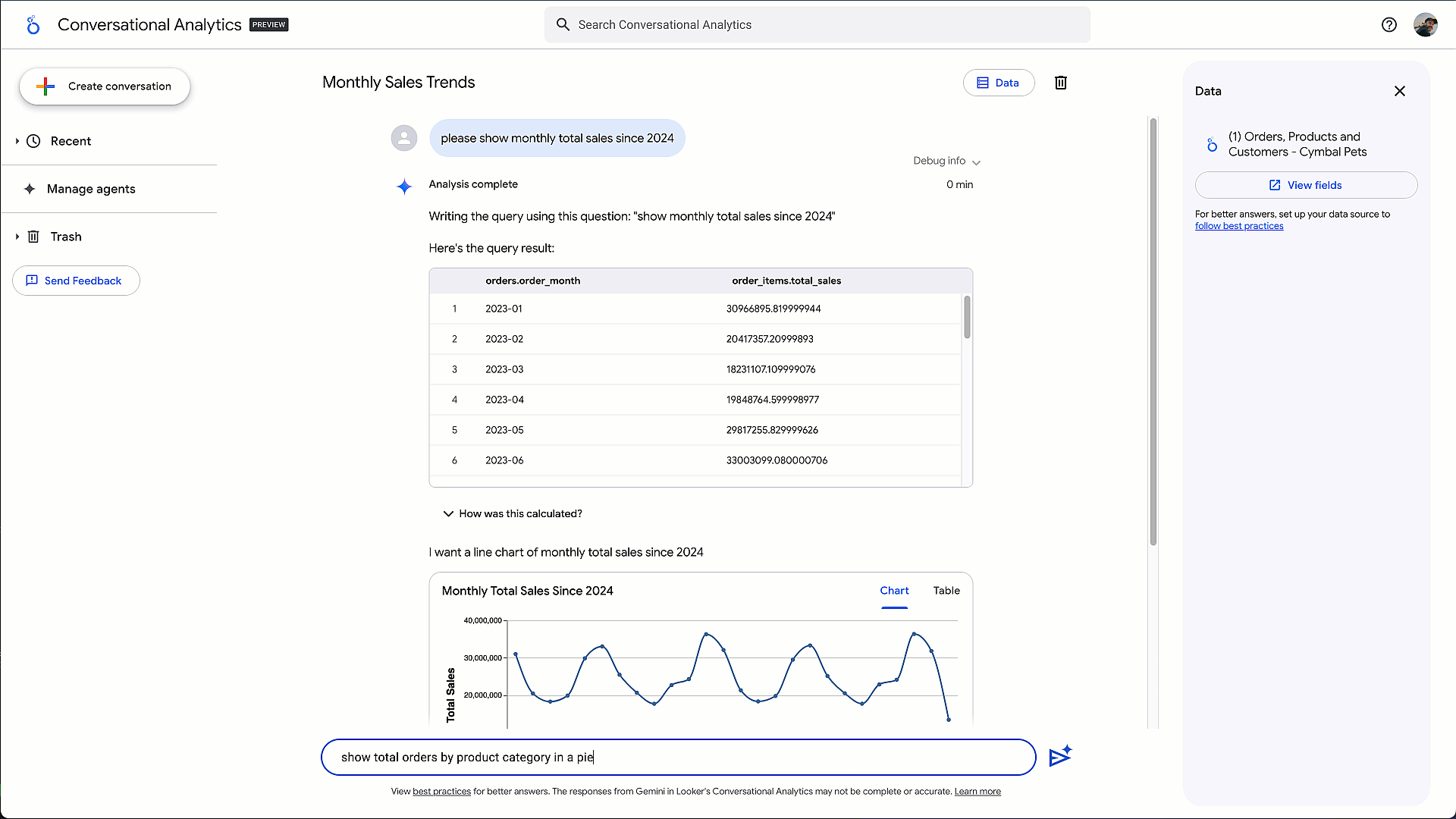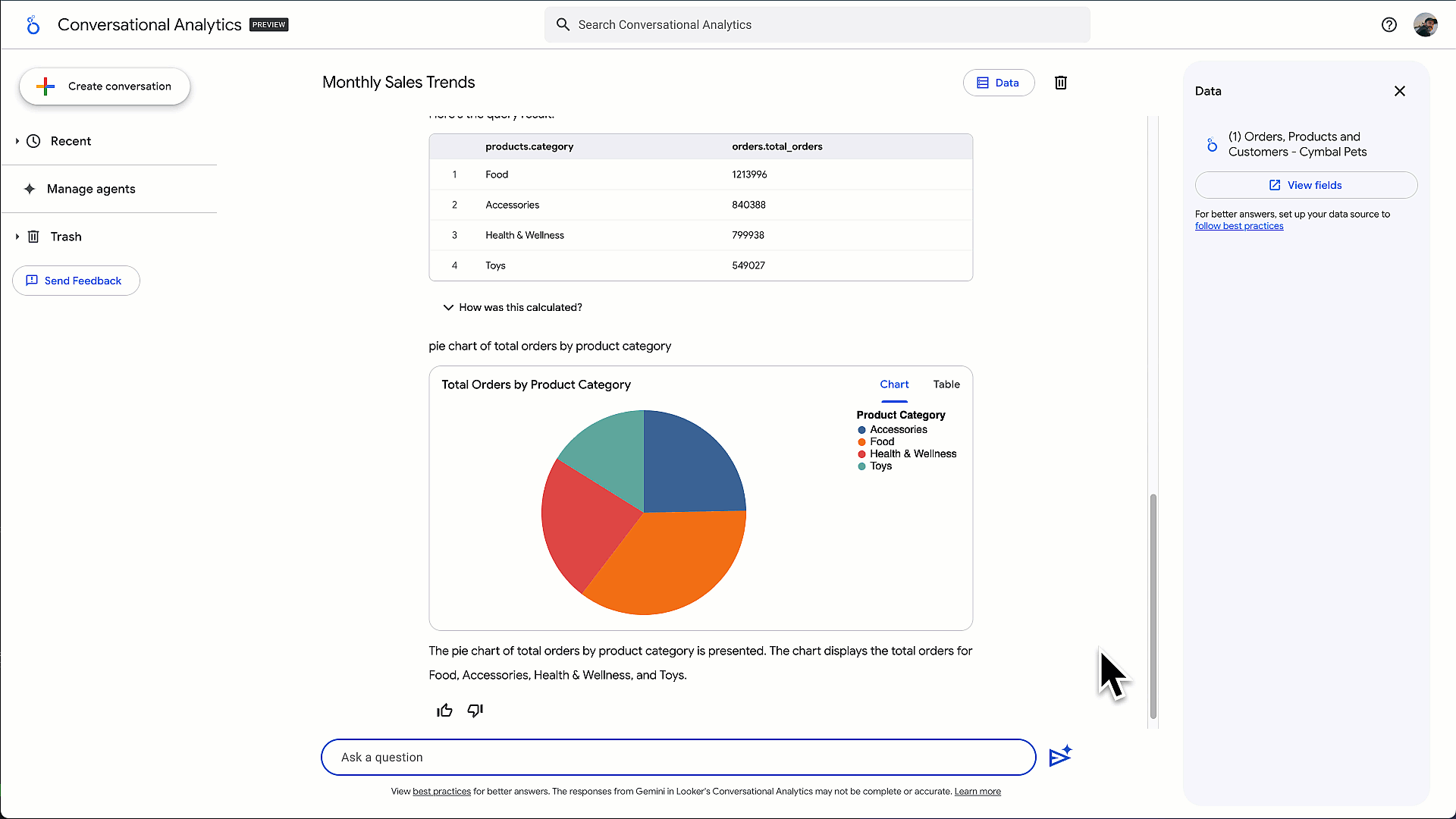
图 3 - 使用代码解释器进行高级分析的会话分析
构建互联的智能体生态系统
智能体生态系统并非闭环,而是一个面向开发者的开放平台。当开发者不仅使用现有智能体,还能将其扩展并连接到自己的智能系统,从而构建更广阔的网络时,智能体转型的真正潜力才能得以实现。我们的一方智能体提供强大的开箱即用功能以及基础构建块(包括 API、工具和协议),用于构建自定义智能体、将对话智能集成到现有应用程序中,以及协调复杂的多智能体工作流以解决独特的业务问题。
为了实现这一点,我们推出了 Gemini Data Agents API,首先是全新的对话分析 API (Conversational Analytics API) 预览版。该 API 提供了构建模块,可将 Looker 强大的自然语言处理和代码解释器功能直接集成到您自己的应用程序、产品和工作流程中。这使您能够创建独特、引人入胜且易于访问的数据体验,以满足您特定的业务需求。
除了对话式体验之外,我们还提供从头开始创建自定义智能体的工具。我们全新的数据智能体 API 和智能体开发套件 (Agent Development Kit, ADK) 让您能够根据自身独特的业务流程构建专用智能体。所有这些安全交互的基础是我们对模型上下文协议 (Model Context Protocol, MCP) 的投入,包括数据库 MCP 工具箱以及新增的 Looker MCP 服务器 (Looker MCP Server) 预览版。
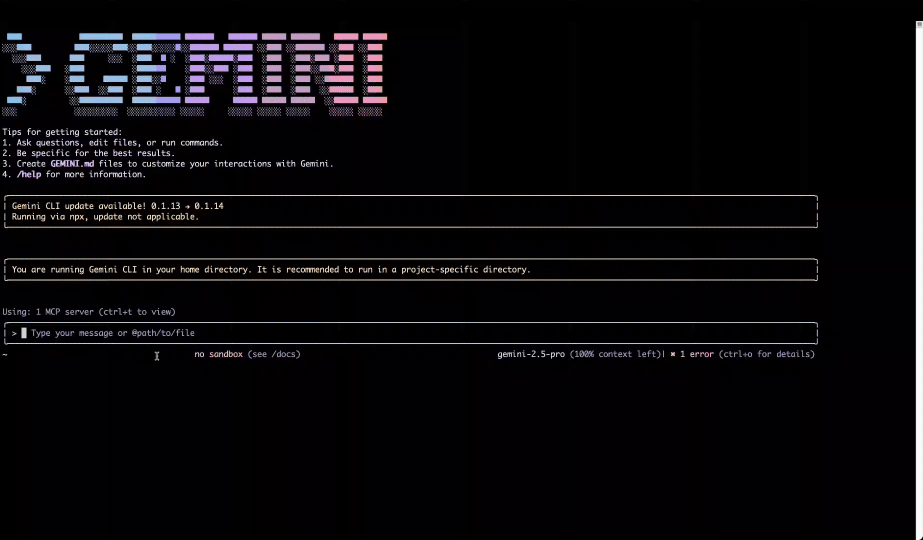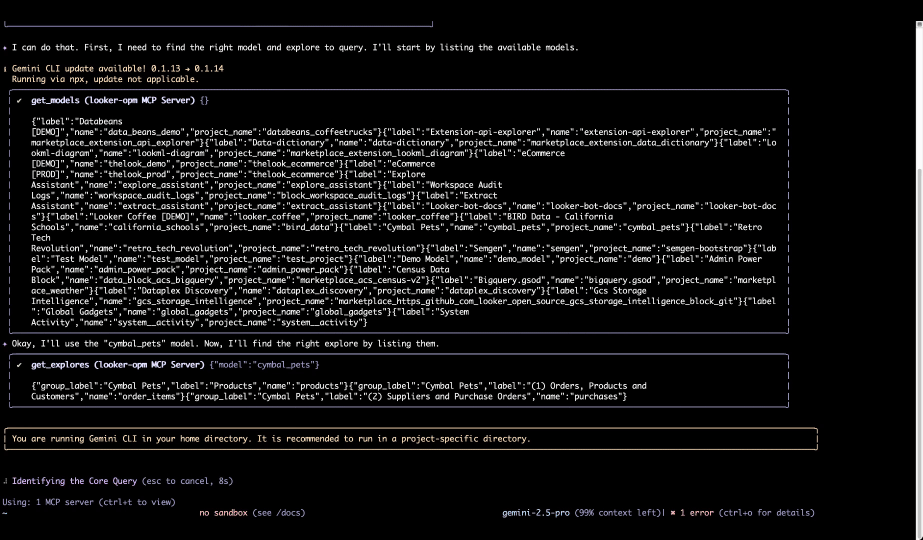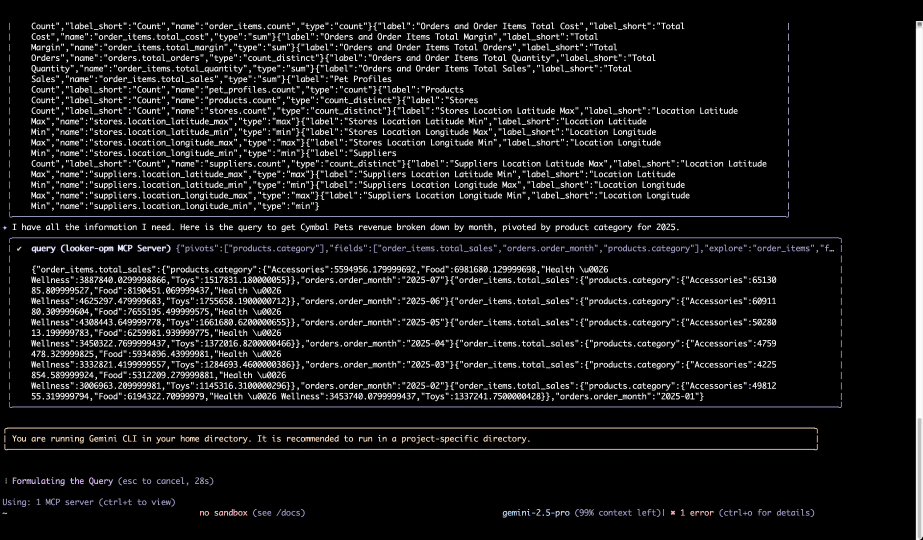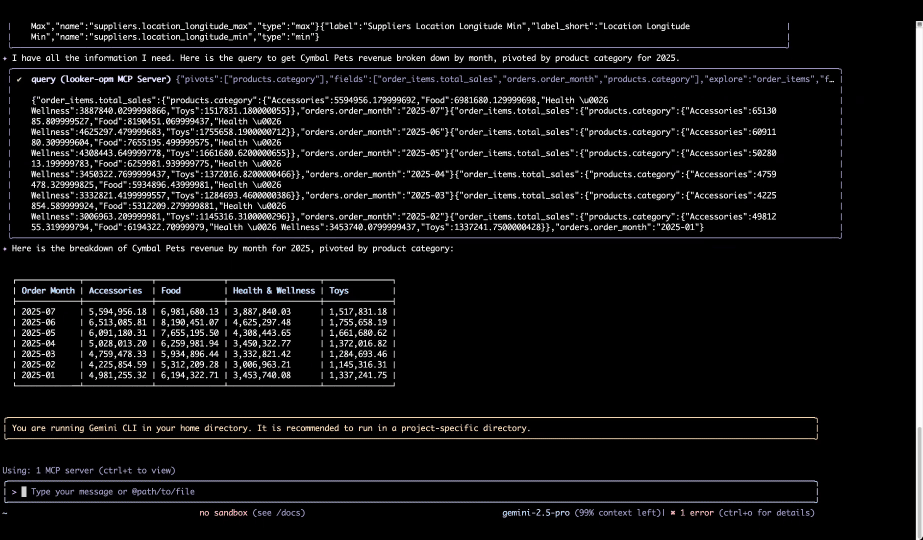
图 4 - Gemini CLI 从 Looker MCP 服务器查询语义层
统一的 AI 原生数据基础
智能体及其构成的网络无法在传统的数据堆栈上运行。它们需要一个认知基础,将企业各处的数据统一起来,并提供理解意义的新能力,同时提供一个持久的记忆以进行推理。
这一 AI 原生基础架构的核心要求在于,它必须能够统一存储在 OLTP(联机事务处理)和 OLAP(联机分析处理)系统中的实时事务性数据与历史分析性数据。我们最初是为 AlloyDB 开发了列式引擎,旨在为 PostgreSQL 的工作负载提供强劲的分析加速能力。如今,我们通过推出全新的 Spanner 列式引擎(Spanner columnar engine)预览版,将这一性能承诺扩展到我们的旗舰级横向扩展数据库 Spanner。在该引擎上运行分析查询时,其性能比在 SSD 层的 Spanner 行式存储上最高可提升 200 倍——而这一切都直接在您的事务数据上完成,无需移动。作为我们统一数据云的一部分,这项创新将通过 Data Boost 直接惠及我们的分析引擎 BigQuery。BigQuery 利用 Spanner 列式引擎缩小事务工作负载和分析工作负载之间的差距,使其能够更快地分析实时运营数据。
有了这个统一的数据平面,接下来的需求就是为智能体提供基于公司事实数据的全面记忆。为了确保智能体的可信度并防止出现幻觉,它们必须使用一种名为检索增强生成 (Retrieval-Augmented Generation, RAG) 的技术。有效的 RAG 的基础是向量搜索,它涵盖实时运营数据和深度历史分析数据。因此,我们将向量搜索和生成功能直接嵌入到数据基础中,使智能体能够访问事务性记忆和分析性记忆。
然而,优化向量搜索非常复杂,常常迫使开发者在性能、质量和运营开销之间做出艰难的权衡。AlloyDB AI 中的自适应过滤 (adaptive filtering) 预览版等新功能解决了事务内存的这一问题,自动维护向量索引并优化实时运营数据的快速查询。为了提供深度分析内存,我们还为 BigQuery 引入了自主向量嵌入和生成功能。现在,BigQuery 可以自动准备和索引用于向量搜索的多模态数据,这是为您的智能体构建丰富的长期语义内存的关键一步。
最后,在这些统一且可访问的数据之上,我们将 AI 推理能力直接嵌入到我们的查询引擎中。借助 BigQuery 中新增的 AI 查询引擎 (AI Query Engine) 预览版,所有数据从业者都可以在 BigQuery 内部对结构化和非结构化数据执行 AI 驱动的计算,快速轻松地获得诸如“这些客户评论中哪一个听起来最令人沮丧?”之类的主观问题的答案。
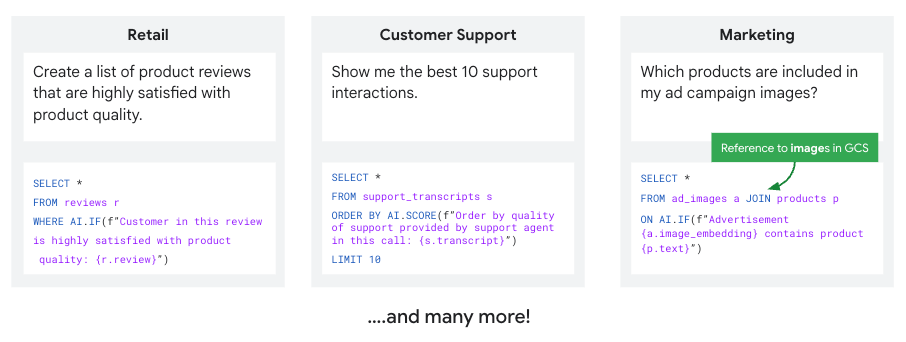
AI 查询引擎将 LLM 的强大功能直接引入 SQL
智能体时代已来
今天发布的内容——从为每位用户打造的专属智能体,到为其提供支持的 AI 原生基础架构——其意义远不止一份路线图,它们是构建一个全新的“智能体企业 (agentic enterprise)”的基石。通过汇聚一支全新的智能体队伍,使他们能够在开放互联的网络中协作,并将它们置于统一的数据云中,从而消除运营和分析领域之间的界限。我们所提供的平台,旨在让您成为一名创新者,而不仅仅是集成者。这将彻底改变您的组织与数据交互的方式,从过去由人类主导的复杂分析,转向您的团队与智能体之间形成的强大协作关系。智能体时代已经到来。我们无比期待您将创造出怎样的精彩,并诚邀您加入这段旅程,与我们共同重新定义数据的无限可能。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们