编者按:Jina AI Reader 是一款专业工具,可将网页 URL 或本地文件的原始内容转化为简洁、结构化且适配 LLM 的格式。本文中,肖涵详细解析了 Cloud Run 如何助力 Jina AI 构建安全可靠、经济高效且可以大规模扩展的网络内容基准化应用。文章深入探讨了 Jina Reader 背后的协同创新、技术攻坚与突破性成果——目前这套网内容定位系统日均处理量已达千亿 token。
2024 年 4 月 Jina Reader 一经推出便呈现爆发式增长——每日处理超 1,000 万次请求和 1,000 亿 Token, 充分印证了市场对可靠且适配 LLM 的网页内容存在着巨大需求。Jina Reader 并非普通的网页抓取工具,而是将原始且杂乱的网页转化为整洁、结构化的 Markdown 格式,开创了 AI 系统获取网页内容的全新范式。
任何处理网页数据的 AI 系统面临的核心挑战都是“网络内容基准化应用”。现代网站充斥着内容、广告、追踪脚本和动态 JavaScript 代码的混乱组合,导致信噪比严重失衡。传统爬虫工具难以应对这种复杂性,在处理动态单页应用时常常失灵,或者为 LLM 生成无法使用、缺乏基准的数据。Jina Reader 的突破性解决方案 ReaderLM-v2 是一个专为智能提取内容而构建的 15 亿参数语言模型,它经过数百万份文档的训练,能够理解超越简单规则的网页结构。
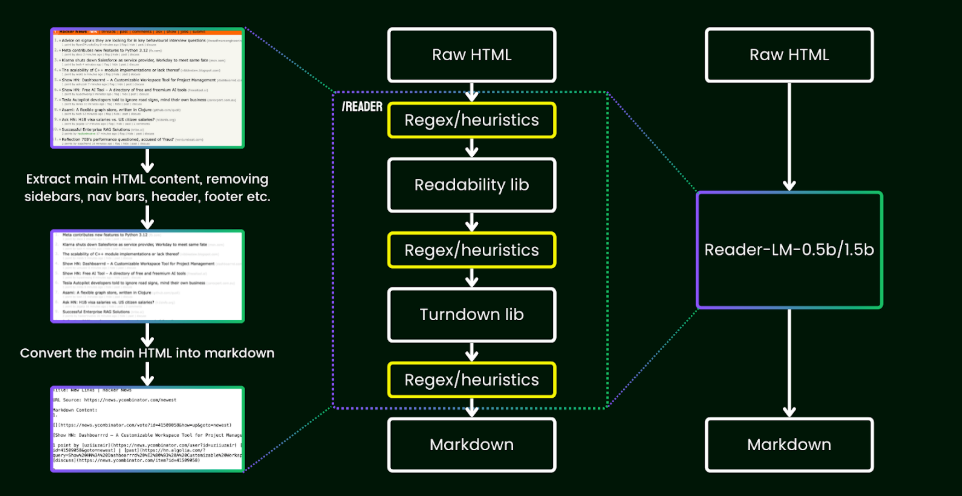
图1:Jina Reader:先进的浏览器自动化系统
Cloud Run:Jina Reader 规模化背后的引擎
Jina Reader 面临着网页爬取工作负载固有的突发性和不可预测性挑战。传统的虚拟机设置要么导致昂贵的资源过度预配,要么在负载压力下出现严重故障。Google Cloud Run 成为了关键的解决方案,助力 Jina Reader 构建安全、可靠、经济高效且可以大规模扩展的网页抓取系统。
网络内容基准化应用(即用于抓取和清理网页内容的浏览器自动化系统)部署在 Cloud Run(CPU)上,运行完整的 Chrome 浏览器实例。
ReaderLM-v2 是一款拥有 15 亿参数的语言模型,专门用来将原始 HTML 转换为 Markdown,在支持无服务器 GPU 的 Cloud Run 之上运行。
Cloud Run 直接解决了多个关键难题:
性能优化:Jina Reader 与 Google Cloud 工程团队的深度协作至关重要。我们共同优化了浏览器自动化场景的容器生命周期管理——通过预热机制、图像优化和智能资源分配,将启动时间从 10 秒以上缩短至 2 秒以内。针对 ReaderLM-v2 模型,Google 团队协助创建了自定义容器配置,实现在 Cloud Run GPU 上高效运行 15 亿参数的大模型。Cloud Run GPU 的按需扩展与快速启动能力,对我们实现日均千亿 token 处理量的性能优化起到了决定性作用。
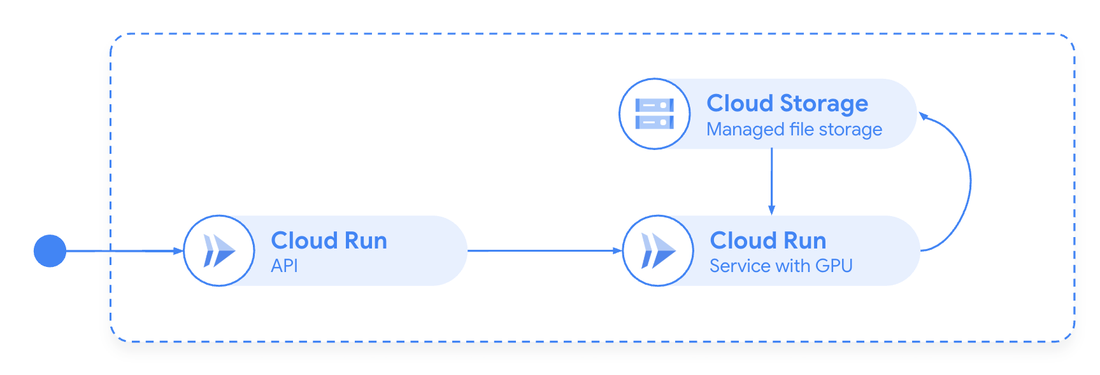
图2:Cloud Run GPU 助力实现按需 AI 推理(托管 ReaderLM-v2 模型)
真正的零服务器无缝扩缩:Cloud Run 通过运行完整 Chrome 浏览器实例,实现了经济高效的运营。每个请求都会生成配备独立无头 Chrome 的隔离容器,而且最为关键的是,请求完成后容器就会消失。这种瞬时特性对于处理不受信任的网页内容至关重要,可降低安全风险和内存泄漏。
全球多区域部署:Cloud Run 的全球覆盖确保请求可在靠近用户和目标网站的地理位置进行处理。这一特性显著降低了延迟并提高了成功率,甚至能应对受地理位置限制的内容。
大规模自动扩缩:在流量高峰期,该平台无需人工干预,即可实现从少量容器实例到超过 1,000 个实例的无缝扩展,从容应对网页抓取工作中不可预测的流量变化
经济可行性:得益于 Cloud Run 的按需付费模式,Jina Reader 既能为终端用户提供大额免费额度,又能在月均高负载场景下保持盈利。这种灵活的定价模式正是 Jina Reader 得以大规模普及的根本原因。
弹性和卓越运营:在近期的一次持续性分布式拒绝服务攻击(DDoS)中,Cloud Run 无服务器架构展现出不可替代的防御价值。其扩缩机制成功抵御了每分钟超 10 万次请求的海量负载,结合智能速率限制技术精准过滤恶意流量。尤为关键的是,其按需扩缩至零的能力,攻击结束后系统成本即刻回归正常水平。该系统始终保持 99.9% 以上的正常运行时间。
结论
基于 Google Cloud Run 构建 Jina Reader 的实践充分证明,AI 能力与云原生架构能够相辅相成。Cloud Run 凭借无服务器 GPU、容器隔离、全球部署以及零扩缩的经济效益,使得这一架构得以实现。我们双方的紧密合作表明,以 AI 为核心的系统与现代云基础架构的深度融合,能够打造出以往不可能实现的功能,也筑成了我们每天处理 1000 亿个 Token 的技术基石。
您可以在我们的产品页面了解更多关于 Cloud Run GPU 的信息;如欲了解如何在 Cloud Run 上托管大语言模型,请观看此视频。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们