首页 > 资源 > 文章详情
从 LLM 到图像生成:利用 AI Hypercomputer 加速推理工作负载

从零售到游戏,从代码生成到客户服务,越来越多的组织正在运行基于 LLM 的应用程序,其中 78% 的组织目前处于开发或生产阶段。随着生成式 AI 应用程序数量与用户规模的不断增长,对高性能、可扩展且易于使用的推理技术的需求也日益增长。在 Google Cloud,我们正通过 AI Hypercomputer 为 AI 快速演进的下一阶段扫清障碍。
在 Google Cloud Next 25 上,我们分享了 AI Hypercomputer 推理功能的众多更新,推出了我们最新的专为推理设计的张量处理单元(TPU)Ironwood,以及一些软件增强功能,例如使用 TPU 上的 vLLM 进行简单而高效的推理,以及最新的 GKE 推理功能 —— GKE Inference Gateway 和 GKE Inference Quickstart。
借助 AI Hypercomputer,我们还将继续通过优化的软件来突破性能极限,并有强大的基准测试支持:
Google 的 JetStream 推理引擎融入了全新的性能优化,集成了 Pathways,可实现超低延迟的多主机、解耦式服务。
MaxDiffusion 是我们潜在扩散模型的参考实现,它在 TPU 上为计算密集型图像生成工作负载提供了卓越的性能,并且现在支持 Flux——迄今为止最大的文本转图像生成模型之一。
MLPerf™ Inference v5.0 的最新性能结果展现了 Google Cloud A3 Ultra(NVIDIA H200)和 A4(NVIDIA HGX B200)虚拟机在推理方面的强大功能和多功能性。
优化 JetStream 的性能:Google 的 JAX 推理引擎
为了最大限度地提高性能并降低推理成本,我们很高兴在 TPU 上提供更多 LLM 服务选择,进一步增强 JetStream 的功能,并为 TPU 引入 vLLM 支持。vLLM 是一个广泛采用的快速高效的 LLM 服务库。通过 vLLM on TPU 和 JetStream,我们能以低延迟、高吞吐量的推理提供卓越的性价比,并通过开源贡献和 Google AI 专家的支持获得社区支持。
JetStream 作为 Google 专为 TPU 打造的开源、吞吐量和内存优化推理引擎,基于与 Gemini 模型相同的推理堆栈。自去年 4 月发布 JetStream 以来,我们投入大量资源,进一步提升了其在众多开源模型上的性能。使用 JetStream 后,我们的第六代 Trillium TPU 的吞吐量性能现已超越 TPU v5e(使用我们的参考实现 MaxText),Llama 2 70B 的吞吐量性能提升了 2.9 倍,Mixtral 8x7B 的吞吐量性能提升了 2.8 倍。
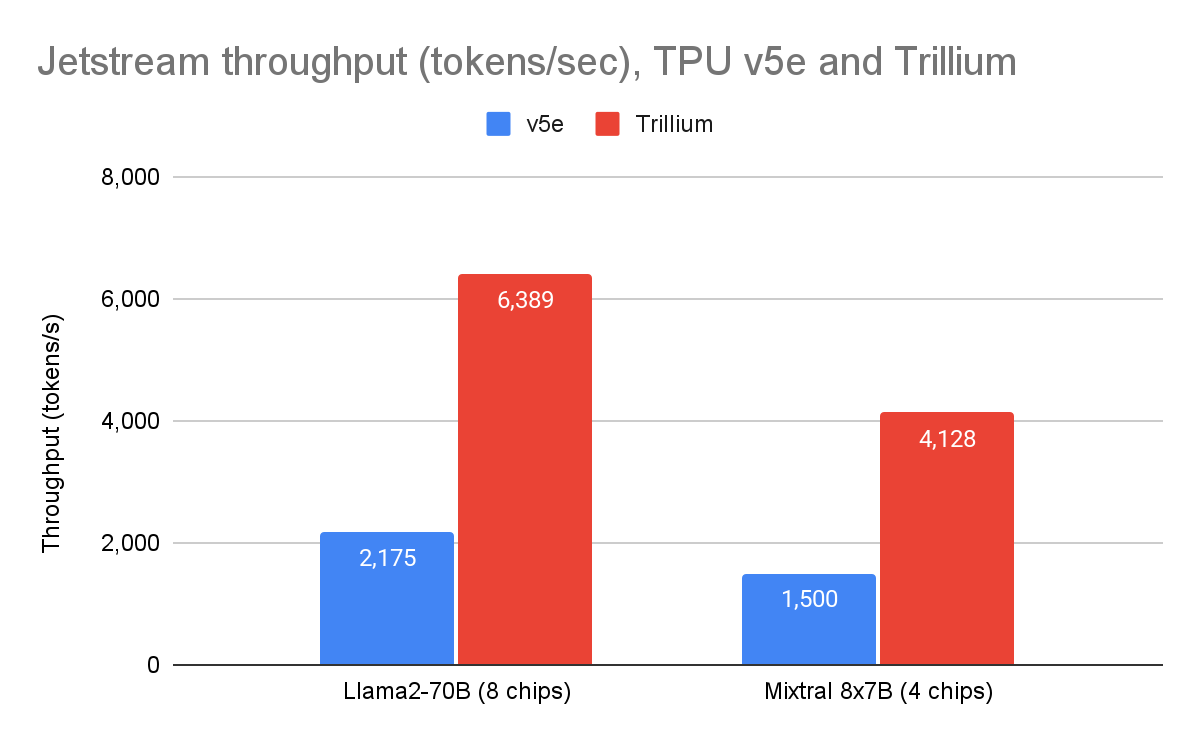
图 1:JetStream 吞吐量(每秒输出 token 数)。Google 内部数据。使用 Cloud TPU v5e-8 和 Trillium 8 芯片上的 Llama2-70B(MaxText)以及 Cloud TPU v5e-4 和 Trillium 4 芯片上的 Mixtral 8x7B(MaxText)测量。最大输入长度:1024,最大输出长度:1024。数据截至 2025 年 4 月。
Google Pathways 运行时首次面向 Google Cloud 客户推出,现已集成到 JetStream 中,支持多主机推理和解耦服务——这两个功能对于模型尺寸呈指数增长和生成 AI 需求发展的重要性日益凸显。
使用 Pathways 的多主机推理功能可在服务时将模型分布到多个加速器主机上。这使得无法在单个主机上进行大型模型的推理成为可能。借助多主机推理,JetStream 在 Trillium 上的 Llama 3.1 405B 处理器上实现了每秒 1703 个 token 的速度。这意味着与 TPU v5e 相比,每美元可获得的推理次数提高了三倍。
此外,借助 Pathways,解耦服务功能允许工作负载动态地独立扩展 LLM 推理的解码和预填充阶段。这可以更好地利用资源,并提升性能和效率,尤其对于大型模型而言。在 Trillium 平台上,对于 Llama2-70B 而言,与在同一台服务器上对 LLM 请求处理的预填充和解码阶段交错执行相比,使用多主机进行解耦服务的在预填充操作(首 token 生成时间,TTFT)的性能提高了七倍,在解码阶段 token 生成(每 token 生成时间,TPOT)的性能提升了近三倍。
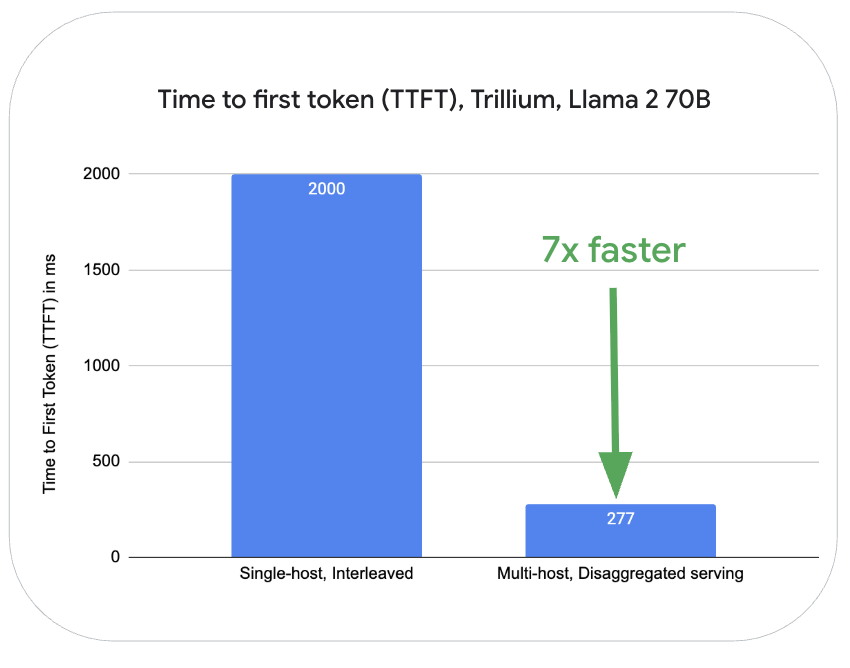
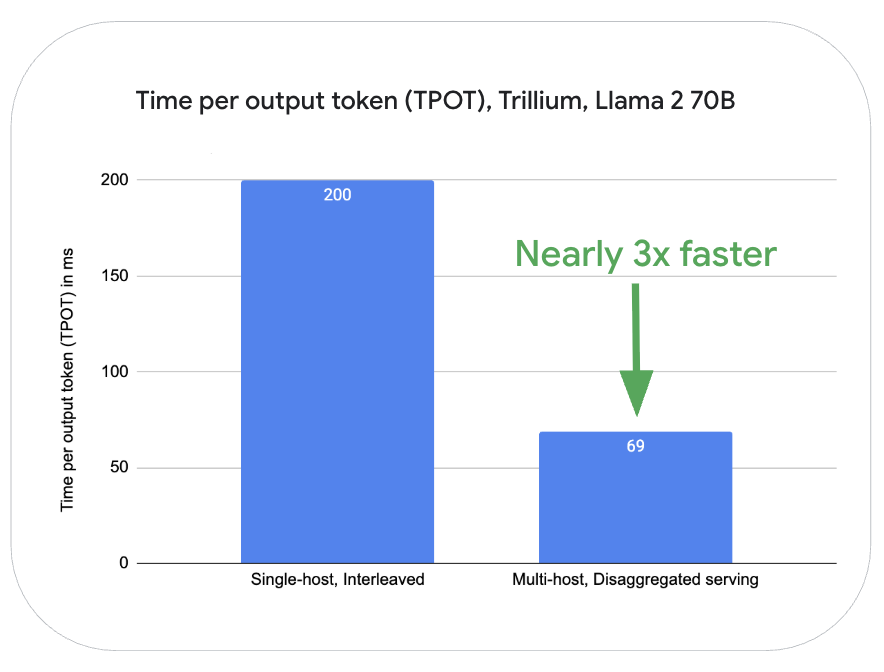
图 2:在 Cloud TPU Trillium 16 芯片(8 芯片用于预填充服务,8 芯片用于解码服务)上使用 Llama2-70B(MaxText)测量。使用 OpenOrca 数据集测量。最大输入长度:1024,最大输出长度:1024。数据截至 2025 年 4 月。
像 Osmos 这样的客户正在使用 TPU 来最大限度地提高大规模推理的成本效益:“Osmos 正在打造全球首款 AI 数据工程师。这要求我们部署当今最先进的 AI 技术。我们很高兴能够继续以 Google TPU 作为我们的训练和推理 AI 基础架构。我们在 Trillium 上已规模化生产部署了 vLLM 和 JetStream,并且能够以超过 3500 个 token/秒的速度为每个 v6e 节点实现业界领先的性能,为 70B 类模型进行长序列推理。这为我们带来了业界领先的 token/秒的成本效益,不仅可与其他硬件基础架构相媲美,而且可以与完全托管的推理服务相媲美。TPU 的可用性以及在 AI Hypercomputer 上轻松部署的特性,让我们能够满怀信心地构建企业软件产品。”
——Osmos 首席执行官 Kirat Pandya
MaxDiffusion:高性能扩散模型推理
除了 LLM 之外,Trillium 在图像生成等计算密集型工作负载上也展现出卓越的性能。MaxDiffusion 提供了一系列各种潜在扩散模型的参考实现。除了 Stable Diffusion 推理之外,我们还扩展了 MaxDiffusion,使其现在支持 Flux;Flux 拥有 120 亿个参数,是迄今为止最大的开源文生图模型之一。
正如 MLPerf 5.0 所展示的,与其上一代 TPU v5e 的上一轮性能测试相比,Trillium 在 Stable Diffusion XL(SDXL)上的每秒查询吞吐量提升了 3.5 倍。自 MLPerf 4.1 提交以来,吞吐量进一步提升了 12%。
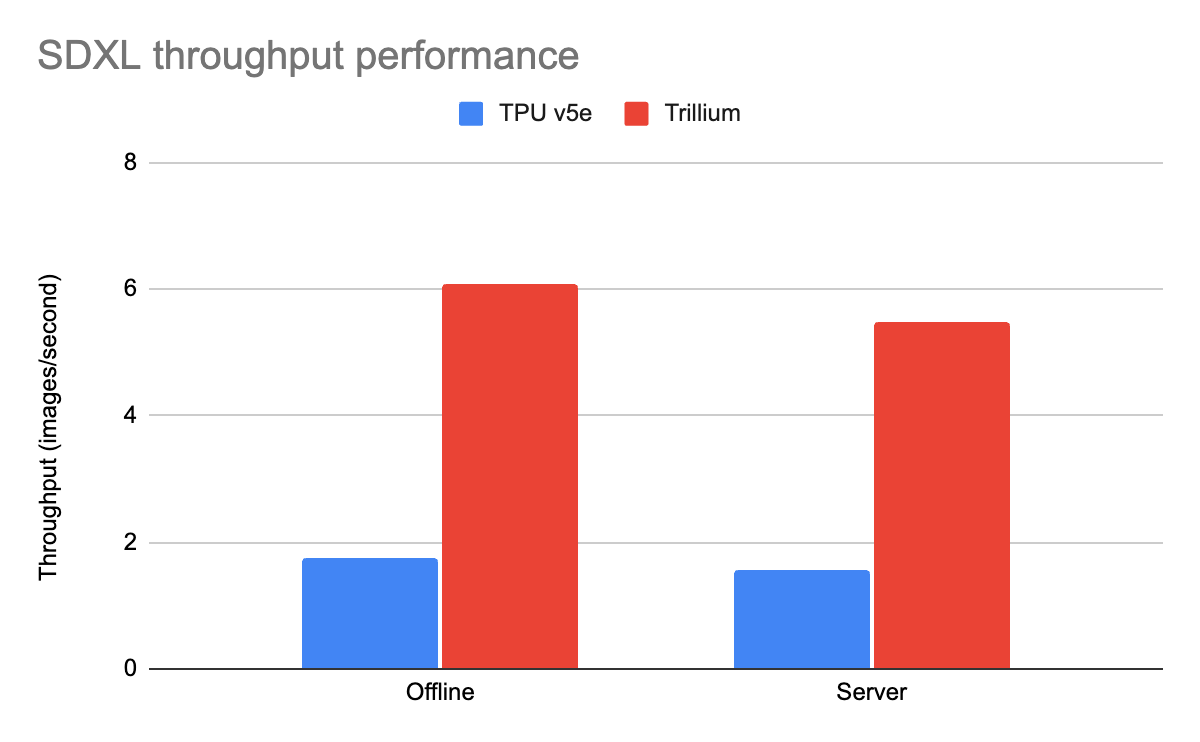
图 3:MaxDiffusion 吞吐量(每秒图像数)。Google 内部数据。使用 Cloud TPU v5e-4 和 Trillium 4 芯片上的 SDXL 模型测量。分辨率:1024x1024,每设备的批次大小:16,解码步骤:20。数据截至 2025 年 4 月。
凭借如此高的吞吐量,MaxDiffusion 提供了一种高成本效益的解决方案。在 Trillium 上生成 1000 张图片的成本低至 22 美分,与 TPU v5e 相比能够节省 35%。
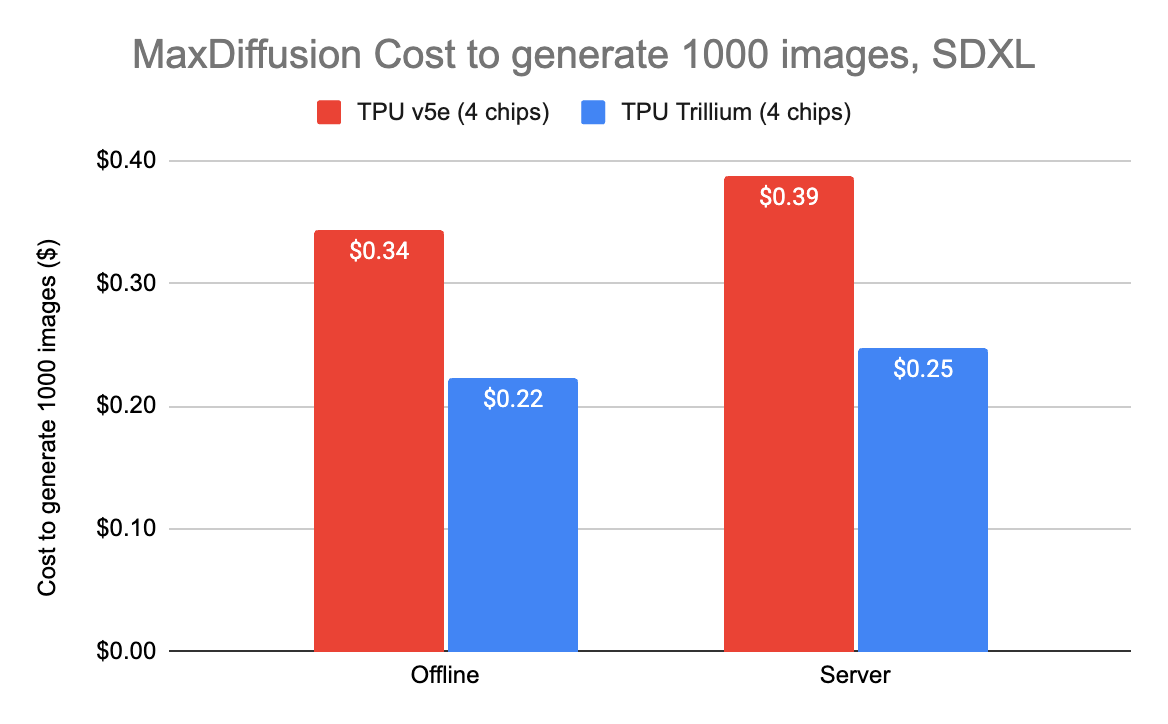
图 4:生成 1000 张图像的扩散成本。Google 内部数据。使用 Cloud TPU v5e-4 和 Cloud TPU Trillium 4 芯片上的 SDXL 模型测量。分辨率:1024x1024,每设备的批次大小:2,解码步骤:4。成本基于美国 Cloud TPU v5e-4 和 Cloud TPU Trillium 4 芯片的 3 年 CUD 价格。数据截至 2025 年 4 月。
A3 Ultra 和 A4 VM MLPerf 5.0 推理结果
对于 MLPerf™ Inference v5.0,我们提交了 15 份结果,其中包括首次使用 A3 Ultra(NVIDIA H200)和 A4(NVIDIA HGX B200)虚拟机提交的结果。A3 Ultra 虚拟机搭载八块 NVIDIA H200 Tensor Core GPU,提供 3.2 Tbps 的 GPU 到 GPU 无阻塞网络带宽,并且相比搭载 NVIDIA H100 GPU 的 A3 Mega,其高带宽内存(HBM)是后者的两倍。Google Cloud 的 A3 Ultra 展现了极具竞争力的性能,在 LLM、MoE、图像和推荐模型方面取得了与 NVIDIA 峰值 GPU 提交结果相当的成绩。
Google Cloud 是唯一一家提交 NVIDIA HGX B200 GPU 测试结果的云服务提供商,展现了 A4 VM 在服务 Llama 3.1 405B(MLPerf 5.0 中引入的新基准)等 LLM 方面的卓越性能。A3 Ultra 和 A4 VM 均提供强大的推理性能,这证明了我们与 NVIDIA 的深度合作,旨在为最苛刻的 AI 工作负载提供基础架构。
JetBrains 等客户正在使用 Google Cloud GPU 实例来加速其推理工作负载:
“我们一直在 Google Cloud 上使用搭载 NVIDIA H100 Tensor Core GPU 的 A3 Mega VM,在多个区域运行 LLM 推理。现在,我们很高兴开始使用搭载 NVIDIA HGX B200 GPU 的 A4 VM,我们预计这将进一步降低延迟并增强 JetBrains IDE 中 AI 的响应速度。”
—— JetBrains AI 总监 Vladislav Tankov
AI Hypercomputer 正在推动 AI 推理时代
Google 在 AI 推理领域的创新,包括 Google Cloud TPU 和 NVIDIA GPU 的硬件改进,以及 JetStream、MaxText 和 MaxDiffusion 等软件创新,正通过集成的软件框架和硬件加速器推动 AI 的突破。了解更多关于使用 AI Hypercomputer 进行推理的信息。之后,您可以参考 JetStream 和 MaxDiffusion 的秘诀,立即开始使用。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们