首页 > 资源 > 文章详情
Ironwood TPU 与 AI Hypercomputer 的创新

今天的创新并非诞生于实验室或绘图板上,而是建立在 AI 基础设施的基石之上。AI 工作负载有着全新且独特的需求——满足这些需求需要硬件和软件的精妙结合,以实现大规模的性能和效率,并提供易用性和灵活性,从而按需访问这些基础设施。在 Google Cloud,我们通过 AI Hypercomputer 来实现这一点。
AI Hypercomputer 是一款集成式超级计算系统,凝聚了 Google 十余年 AI 领域的专业知识。AI Hypercomputer 几乎支撑着 Google Cloud 上运行的所有 AI 工作负载;当您使用 Vertex AI 时,它会在后台运行;您也可以通过直接访问 AI Hypercomputer 性能优化硬件、开放软件和灵活的消费模型,对基础架构进行精细控制——所有这些旨在以始终如一的低价格为 AI 工作负载的训练和服务提供更智能的计算能力。这种集成式系统方法在市场上独树一帜,这也是 Gemini Flash 2.0 每美元智能量比 GPT-4o 高出 24 倍、比 DeepSeek-R11 高出 5 倍的原因之一。
我们将在 AI Hypercomputer 技术栈中引入新的创新,这些创新旨在为 AI 工作负载提供最佳的单位成本智能化。
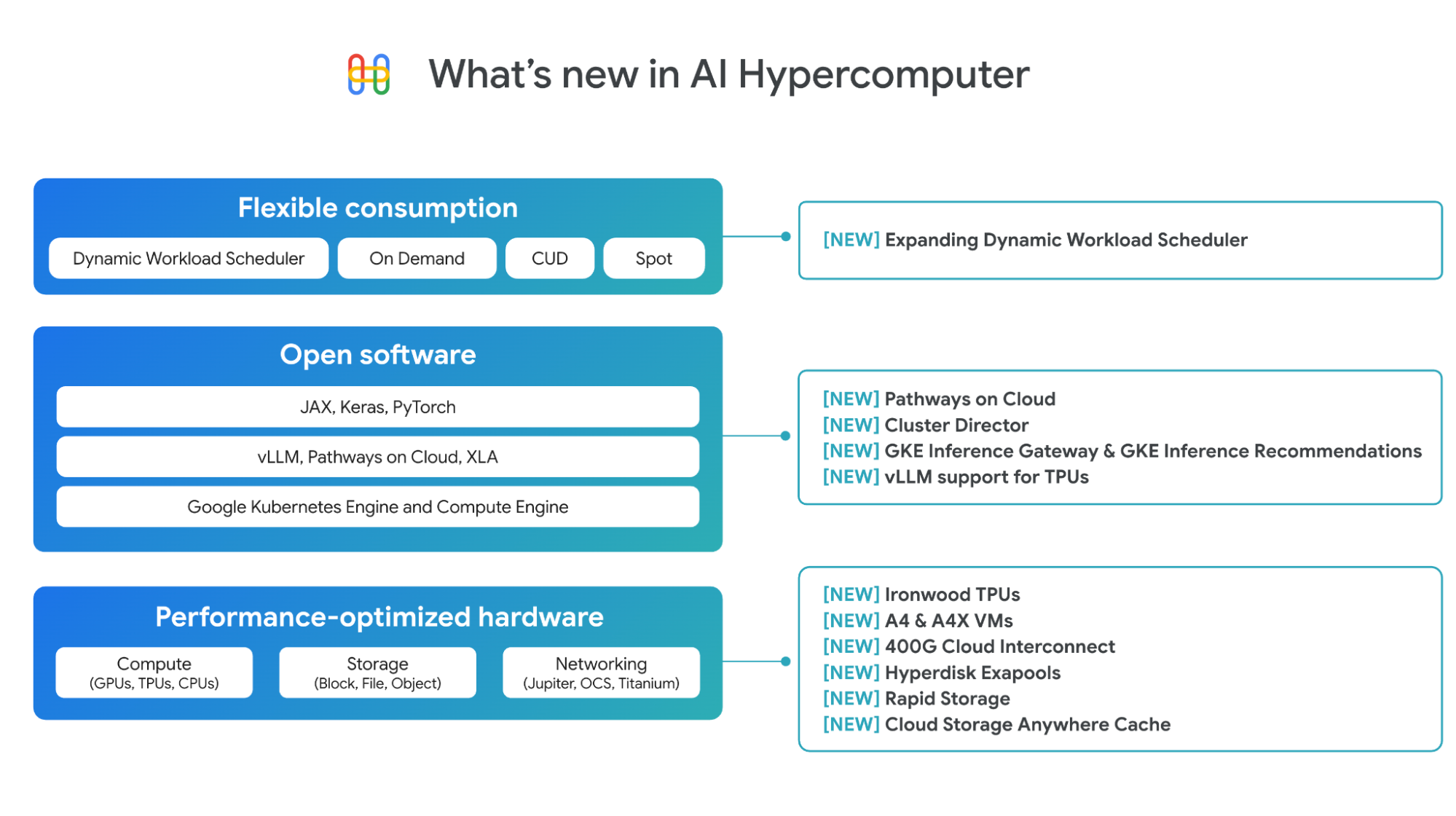
性能优化硬件的进展
我们持续扩展性能优化硬件的产品组合,为计算、网络和存储提供更加广泛的选择。
Ironwood,我们的第七代 TPU:Ironwood 专为推理而打造,与上一代 Trillium 相比,其峰值计算能力提升了 5 倍,高带宽内存(HBM)容量提升了 6 倍。Ironwood 提供两种配置:256 芯片或 9,216 芯片,每种配置均可作为单个扩展 Pod 使用,其中更大的 Pod 可提供惊人的 42.5 exaFLOPS 计算能力。Ironwood 在实现这一切的同时,还比 Trillium 节能 2 倍,显著提升了单位功耗价值。开发者可以通过我们优化的技术栈(包括 PyTorch 和 JAX)访问 Ironwood。点击此处了解更多关于 Ironwood 的信息。
A4 和 A4X 虚拟机:Google Cloud 是首家同时提供 NVIDIA B200 和 GB200 NVL72 GPU (分别对应 A4 和 A4X 机型)的超大规模云服务提供商。我们已于上个月在 NVIDIA GTC 大会上宣布了 A4 虚拟机(NVIDIA B200)的全面上市,A4X 虚拟机(NVIDIA GB200)现已推出预览版。点击此处了解更多关于 A4 和 A4X 的信息。
增强型网络:为了支持 AI 工作负载所需的超低延迟,我们新的 400G Cloud Interconnect 和 Cross-Cloud Interconnect 提供比 100G Cloud Interconnect 和 Cross-Cloud Interconnect 高达 4 倍的带宽,从而实现从本地或其他云环境到 Google Cloud 的连接。点击此处阅读的网络博客,了解更多信息。
Hyperdisk Exapools:块存储,为每个 AI 集群提供所有超大规模云服务商中最高的性能和容量,因此您可以在单个精简配置的池中配置高达 EB 的块存储容量和每秒数 TB 的吞吐量。
快速存储:全新的 Cloud Storage 可用区级(zonal)存储桶,可让您将主存储与 TPU 或 GPU 共置,以实现最佳利用率。与 Cloud Storage 区域级(regional)存储桶相比,它的随机读取数据加载速度最高可提高 20 倍。
Cloud Storage Anywhere Cache:一种全新的、强一致性读取缓存,与现有的区域级存储桶配合使用,可在选定可用区内缓存数据。Anywhere Cache 通过将数据保存在靠近加速器的位置,实现快速响应和实时推理交互,从而将延迟降低 70%。点击此处了解更多关于存储创新博客的信息。
用于训练与推理的开放软件能力
硬件的真正价值是通过协同设计的软件来释放的。AI Hypercomputer 的软件层通过 PyTorch、JAX、vLLM 和 Keras 等开放且流行 ML 框架和库,帮助 AI 从业者和工程师更快地工作。对于基础设施团队来说,这意味着更快的交付时间和更高效的资源利用。我们在 AI 训练和推理软件方面取得了重大进展。
Pathways on Cloud:Pathways 由 Google DeepMind 开发,是 Google 内部大规模训练和推理基础架构的分布式运行时,现已首次在 Google Cloud 上线。在推理方面,它包含解耦服务等功能,允许在单独的计算单元上动态扩展推理工作负载的预填充和解码阶段,每个计算单元均可独立扩展,以提供超低延迟和高吞吐量。客户可以通过我们的高吞吐量和低延迟推理库 JetStream 来使用它。Pathways 还支持弹性训练,允许您的训练工作负载在故障时自动缩减,在恢复时自动扩展,同时确保连续性。要了解更多关于 Pathways on Cloud 的信息,包括 Pathways 架构的其他用例,请阅读文档。
训练高性能和高可靠性的模型
训练工作负载是高度同步的任务,运行在数千个节点上。单个节点性能下降都可能会导致整个任务中断,从而导致更长的上市时间和更高的成本。为了快速配置集群,您需要对特定模型架构进行调优,且部署位置应彼此邻近。您还需要能够快速预测和排除节点故障,并确保在发生故障时工作负载的连续性。
Cluster Director for GKE 和 Cluster Director for Slurm。Cluster Director(前身 Hypercompute Cluster)支持您将一组加速器作为一个单元进行部署和管理,这些加速器具有物理上共置的虚拟机、精准的工作负载分配、高级集群维护控制以及拓扑感知调度功能。近期,我们宣布 Cluster Director 将于今年晚些时候推出全新更新:
Cluster Director for Slurm,一款完全托管的 Slurm 产品,具有简化的 UI 和 API,用于配置和操作 Slurm 集群,包括使用预配置软件的常见工作负载蓝图,使部署可靠且可重复。
360° 可观察性功能,包括用于查看集群利用率、运行状况和性能的仪表板,以及 AI 健康预测器和落后者检测等高级功能,可主动检测和修复直至单个节点的故障。
作业连续性功能,例如端到端自动化健康检查,可持续监控集群并主动替换不健康的节点。即使在性能下降的集群中也能实现不间断训练,并通过多层检查点加快保存和检索速度。
Cluster Director for GKE 将原生支持即将推出的全新 Cluster Director 功能。Cluster Director for Slurm 将在未来几个月内推出,并支持 GPU 和 TPU。立即注册获取抢先体验。
高效运行任意规模的推理工作负载
在过去的一年里,AI 推理发展迅速。更长且高度可变的上下文窗口带来了更复杂的交互;逻辑推理和多步推断正在将计算的增量需求(及成本)从训练阶段向推理阶段(即测试时扩展)迁移。为了给最终用户提供实用的 AI 应用,您需要能够高效服务于当前和未来交互的软件。
GKE 中的 AI 推理新功能:推理网关和 Inference Quickstart。
GKE 推理网关提供智能扩展和负载平衡功能,帮助您使用生成式 AI 模型感知扩展和负载平衡技术处理请求调度和路由。
借助 GKE Inference Quickstart,您可以选择 AI 模型和所需的性能,GKE 将自动配置正确的基础架构、加速器和 Kubernetes 资源。
这两项功能现已推出预览版,与其他托管和开源 Kubernetes 产品相比,它们可将服务成本降低 30% 以上,尾部延迟降低 60%,并将吞吐量提高高达 40%。
vLLM 支持 TPU:vLLM 以其快速高效的推理库而闻名。您只需进行少量配置更改,即可轻松地使用 vLLM 在 TPU 上运行推理,并享受其卓越的性价比优势,而无需更改现有软件栈。Compute Engine、GKE、Vertex AI 和 Dataflow 均支持 vLLM。借助 GKE 自定义计算类,您可以在同一个 vLLM 部署中同时使用 TPU 和 GPU。
更灵活的资源使用模式
动态工作负载调度器(DWS)是一个资源管理和作业调度平台,可帮助更轻松、更经济地获取和使用加速器。近期,我们宣布 DWS 扩展了对加速器的支持,包括 TPU v5e、Trillium、A3 Ultra (NVIDIA H200) 和 A4 (NVIDIA B200) 虚拟机。这些新增支持将通过 Flex Start 模式提供预览版,而 TPU 的日历模式 (Calendar mode) 支持也将在本月晚些时候推出。此外,Flex Start 模式现在支持一种新的资源调配方法,可以即时调配资源并进行动态扩展,使其适用于长时间运行的推理工作负载和更广泛的训练工作负载。这是对 Flex Start 模式中需要同时调配所有节点的排队调配方法的补充。
1. arXiv (LMArena),Chatbot Arena:一个根据人类偏好评估 LLM 的开放平台,作者:Wei-Lin Chiang、Lianmin Zheng、Ying Sheng、Anastasios 1 Nikolas Angelopoulos、Tianle Li、Dacheng Li、Hao Zhang、Banghua Zhu、Michael Jordan、Joseph E. Gonzalez、Ion Stoica,2024 年。准确数据截至 2025 年 3 月 19 日。该基准比较模型输出质量(由人类评审员判断)与生成输出所需的每百万 token 价格,从而创建效率比较。我们将“智能”定义为人类对模型输出质量的感知。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们