首页 > 资源 > 文章详情
通过 Google Cloud TPU 和 GPU 加速 AI 推理

伴随 AI 领域的飞速发展,对高性能、低成本的 AI 推理(服务)的需求也空前高涨。本周(2024 年 4 月),我们宣布推出两款全新的开源软件产品:JetStream 和 MaxDiffusion。
JetStream 是一款面向 XLA 设备的新型推理引擎,率先支持 Cloud TPU。JetStream 专为大型语言模型(LLM)设计,在性能和成本效益上都实现了显著飞跃,与之前的 Cloud TPU 推理引擎相比多出高达 3 倍的推理能力。JetStream 通过 PyTorch/XLA 支持 PyTorch 模型,并通过 MaxText 支持 JAX 模型——这是我们为 LLM(的推理)提供高度可扩展、高性能的参考实现,客户能够基于它来加速开发。
MaxDiffusion 是 MaxText 在潜在扩散模型方面的对应产品,它使得训练和部署针对 XLA 设备(同样率先支持 Cloud TPU)优化的高性能扩散模型变得更加容易。
此外,我们很自豪地分享 MLPerf™ Inference v4.0 的最新性能结果,这一结果展示了由 NVIDIA H100 GPU 驱动的 Google Cloud A3 虚拟机(VM)的强大和多功能性。
JetStream:高性能、高成本效益的 LLM 推理
大语言模型(LLM)处在 AI 革命的前沿,为自然语言理解、文本生成和语言翻译等众多应用提供支持。为了降低客户的 LLM 推理成本,我们构建了 JetStream,这是一款推理引擎,与之前的 Cloud TPU 推理引擎相比,它能将每美元的推理次数提高多达 3 倍。
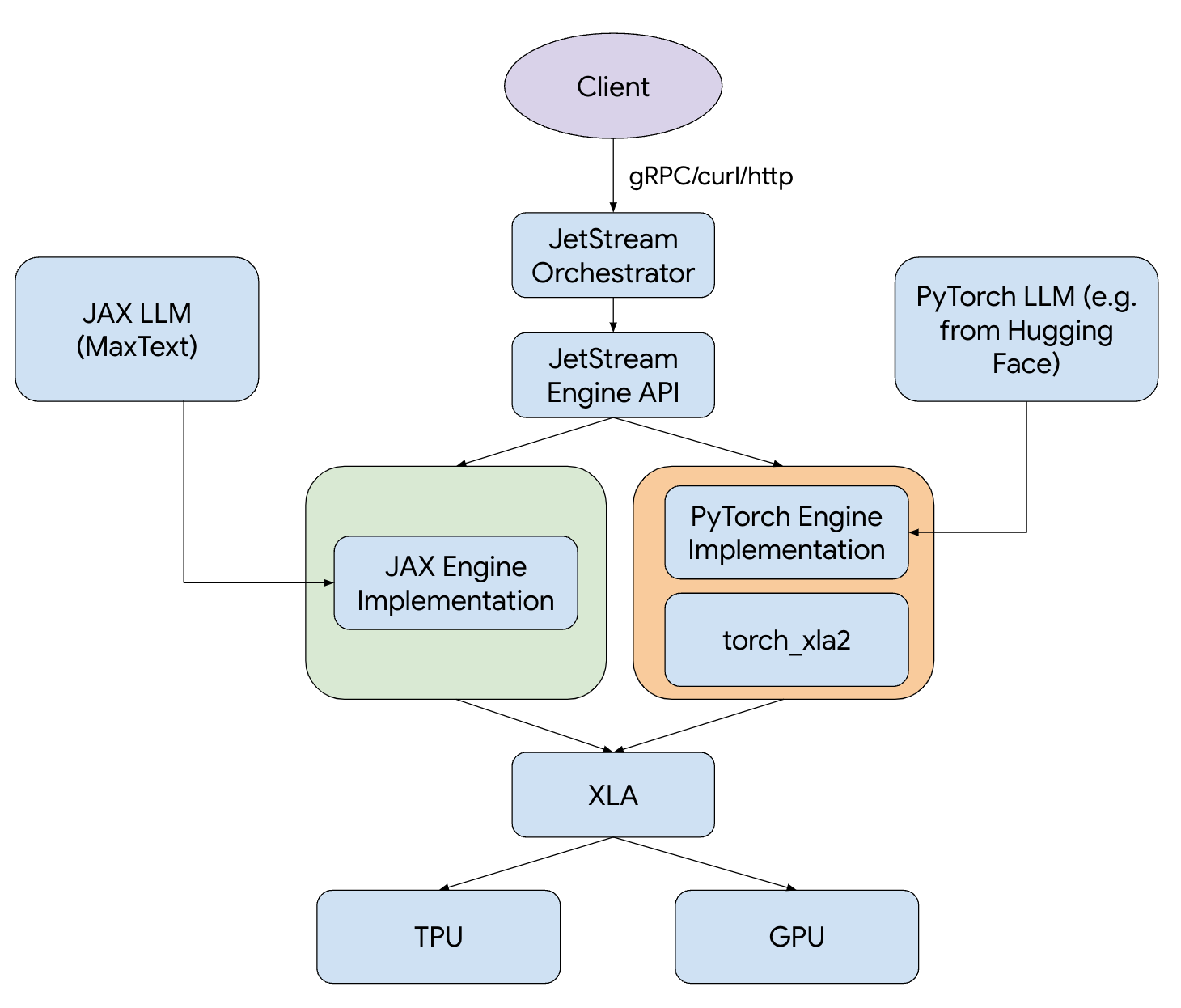
图 1:JetStream 技术栈。
JetStream 包含高级性能优化,例如连续批处理、滑动窗口注意机制以及针对权重、激活函数和键值(KV)缓存的 int8 量化。无论您使用 JAX 还是 PyTorch,JetStream 都支持您偏爱的框架。为了进一步简化您的 LLM 推理工作流程,我们提供了 Gemma 和 Llama 等热门开源模型的 MaxText 和 PyTorch/XLA 实现,并针对最佳成本效益和性能进行了优化。
在 Cloud TPU v5e-8 上,JetStream 为开源模型(包括 MaxText 中的 Gemma 和 PyTorch/XLA 中的 Llama 2)提供高达每秒 4783 个 token 的处理速度:
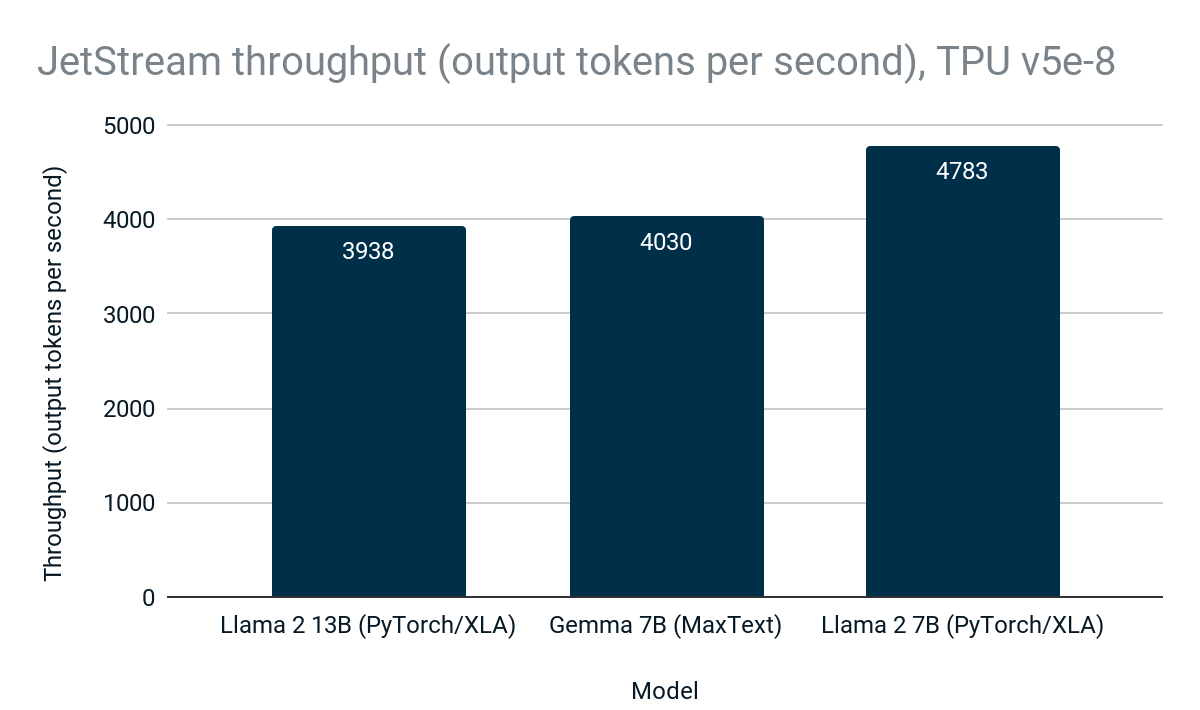
图 2:JetStream 吞吐量(每秒输出 token 数)。Google 内部数据。使用 Cloud TPU v5e-8 上的 Gemma 7B (MaxText)、Llama 2 7B (PyTorch/XLA) 和 Llama 2 13B (PyTorch/XLA) 进行测量。最大输入长度:1024,最大输出长度:1024。连续批处理,权重、激活函数和键值缓存采用 int8 量化。PyTorch/XLA 使用滑动窗口注意力机制。数据截至 2024 年 4 月。
JetStream 的高性能和高效率意味着可以降低 Google Cloud 客户的推理成本,从而使 LLM 推理更易于访问且更加经济实惠:
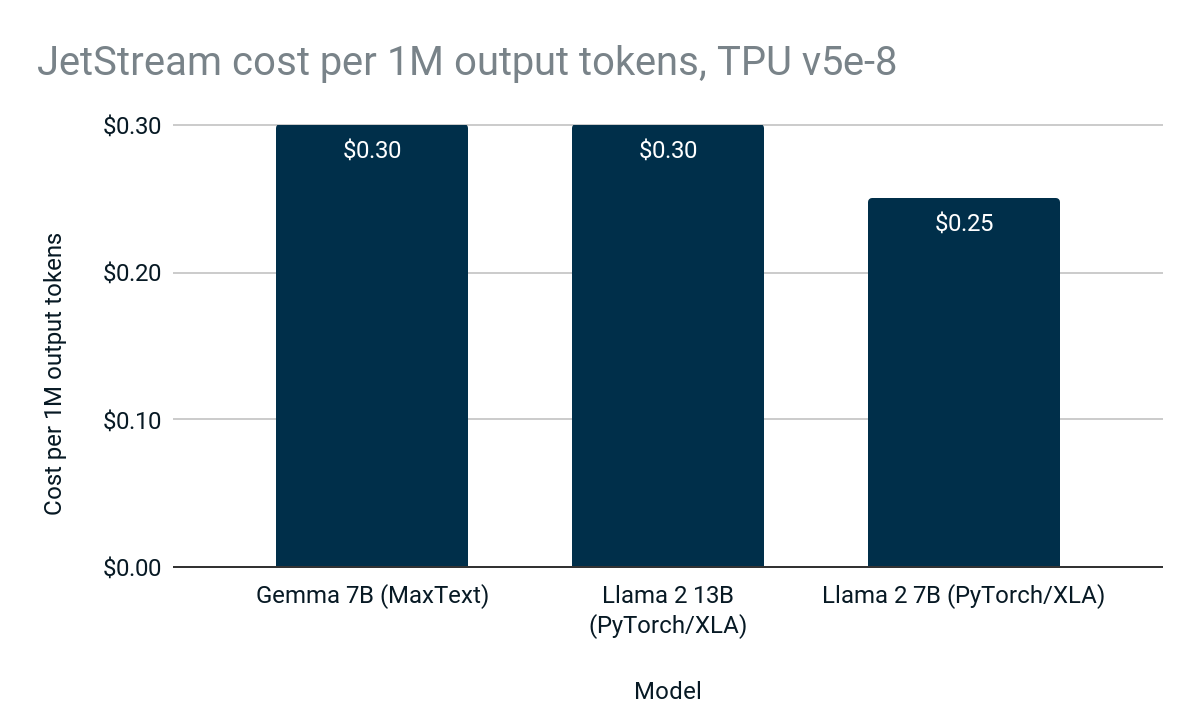
图 3:JetStream 生成 100 万个输出 token 的成本。Google 内部数据。使用 Cloud TPU v5e-8 上的 Gemma 7B (MaxText)、Llama 2 7B (PyTorch/XLA) 和 Llama 2 13B (PyTorch/XLA) 进行测量。最大输入长度:1024,最大输出长度:1024。连续批处理,权重、激活和键值缓存的 int8 量化。PyTorch/XLA 使用滑动窗口注意力机制。JetStream(每 100 万个 token 0.30 美元)在 Gemma 7B 上每美元推理次数比之前的 Cloud TPU LLM 推理堆栈(每 100 万个 token 1.10 美元)高出 3 倍。成本基于美国 Cloud TPU v5e-8 的 3 年 CUD 价格。数据截至 2024 年 4 月。
Osmos 等客户正在使用 JetStream 来加速其 LLM 推理工作负载:
“在 Osmos,我们开发了一款由 AI 驱动的数据转换引擎,旨在帮助企业通过数据处理自动化来扩展业务关系。来自客户和业务合作伙伴的数据通常杂乱无章且不够规范,需要对每一行数据都进行智能处理,以将其映射、验证并转换为优质可用的数据。为此,我们需要高性能、可扩展且高成本效益的 AI 基础架构来进行训练、微调和推理。正因如此,我们选择了 Cloud TPU v5e,并结合 MaxText、JAX 和 JetStream 来实现端到端 AI 工作流。在 Google Cloud 的帮助下,我们能够使用 MaxText 快速轻松地在数十亿个 token 上对 Google 最新的 Gemma 开放模型进行微调,并使用 JetStream 将其部署到 Cloud TPU v5e 上进行推理。Google 优化的 AI 硬件和软件堆栈使我们能够在数小时内(而非数天)获得结果。”
——Osmos 首席执行官 Kirat Pandya
通过为研究人员和开发者提供强大、高成本效益的 LLM 推理开源基础,我们正在赋能下一代 AI 应用。无论您是经验丰富的 AI 从业者,还是刚刚入门 LLM 的新手,JetStream 都能助您加速学习旅程,释放自然语言处理领域的全新可能。
立即体验 JetStream 带来的 LLM 推理未来。访问我们的 GitHub 代码库,了解更多关于 JetStream 的信息,并开启您的下一个 LLM 项目。我们致力于在 GitHub 和 Google Cloud 客户服务平台上长期开发和支持 JetStream。我们诚邀社区与我们共同构建,贡献改进,以进一步推动技术的进步。
MaxDiffusion:高性能扩散模型推理
正如大语言模型(LLM)彻底改变了自然语言处理一样,扩散模型也正在改变计算机视觉领域。为了降低客户部署这些模型的成本,我们创建了 MaxDiffusion,它是一个开源扩散模型参考实现合集。这些实现采用 JAX 编写,具有性能卓越、可扩展且可定制的特点——堪比计算机视觉领域的 MaxText。
MaxDiffusion 提供扩散模型核心组件的高性能实现,例如交叉注意力机制、卷积和高吞吐量图像数据加载。MaxDiffusion 的设计旨在实现高度适应性和可定制化:无论您是致力于突破图像生成限制的研究人员,还是寻求将尖端的生成式 AI 功能集成到应用程序中的开发者,MaxDiffusion 都能为您提供成功所需的基础。
MaxDiffusion 对新型 SDXL-Lightning 模型的实现在 Cloud TPU v5e-4 上可达到每秒 6 张图像,并且吞吐量可线性扩展至 Cloud TPU v5e-8 上的每秒 12 张图像,充分利用了 Cloud TPU 的高性能和可扩展性。
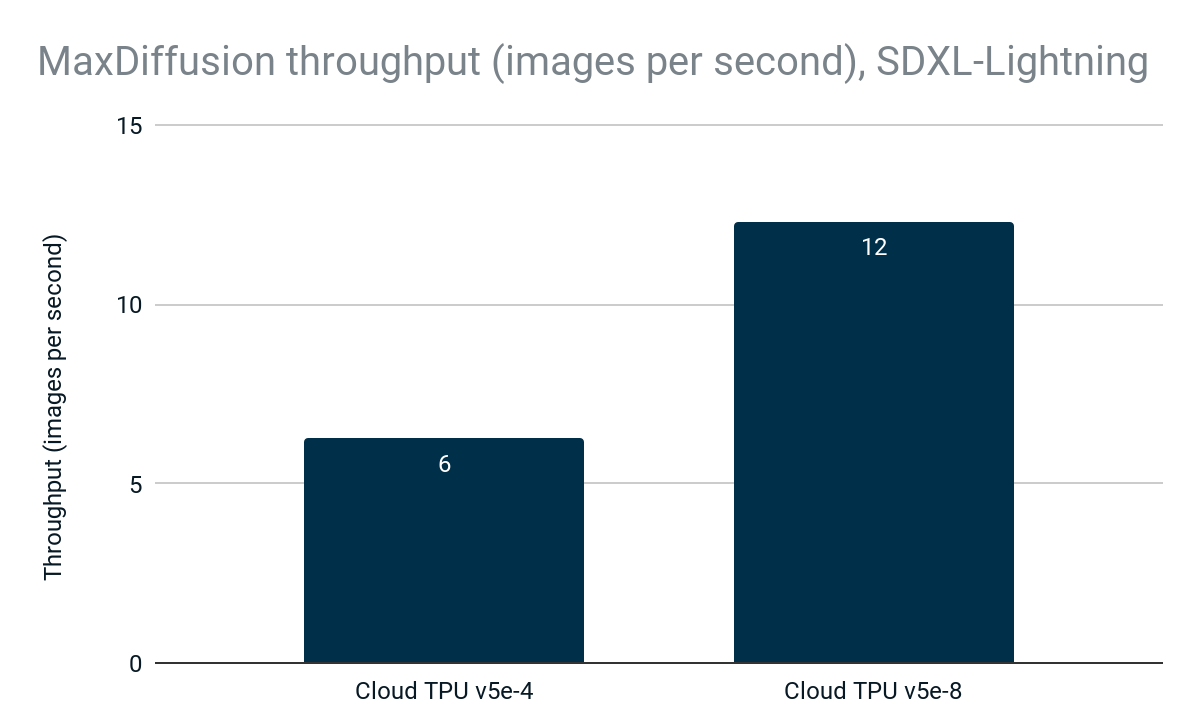
图 4:MaxDiffusion 吞吐量(每秒图像数)。Google 内部数据。使用 Cloud TPU v5e-4 和 Cloud TPU v5e-8 上的 SDXL-Lightning 模型测量。分辨率:1024x1024,每台设备的批次大小:2,解码步骤:4。数据截至 2024 年 4 月。
与 MaxText 和 JetStream 一样,MaxDiffusion 也同样具有成本效益:在 Cloud TPU v5e-4 或 Cloud TPU v5e-8 上生成 1000 张图像仅需 0.10 美元。
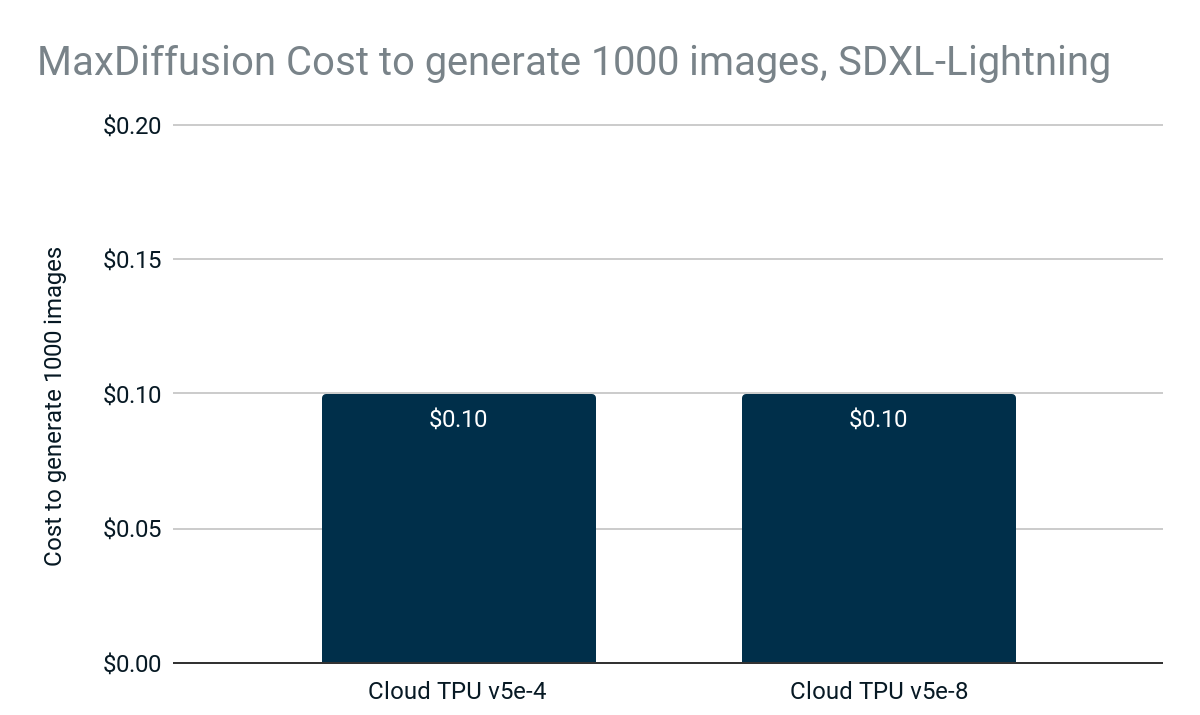
图 5:MaxDiffusion 生成 1000 张图片的成本。Google 内部数据。使用 Cloud TPU v5e-4 和 Cloud TPU v5e-8 上的 SDXL-Lightning 模型测量。分辨率:1024x1024,每台设备的批次大小:2,解码步骤:4。成本基于美国 Cloud TPU v5e-4 和 Cloud TPU v5e-8 的 3 年 CUD 价格。数据截至 2024 年 4 月。
Codeway 等客户正在使用 Google Cloud,以最大限度地提高大规模扩散模型推理的成本效益:
“在 Codeway,我们创造了全球 160 个国家超过 1.15 亿人使用的畅销应用和游戏。例如,‘Wonder’是一款 AI 驱动的应用,能够将文字转化为数字艺术作品,而‘Facedance’则通过多种有趣的动画让面部表情能够翩翩起舞。将 AI 交到数百万用户的手中需要依赖一个高度可扩展且具有成本效益的推理基础设施。借助 Cloud TPU v5e,我们实现了在提供扩散模型服务时比其他推理解决方案快 45% 的服务时间,并且每小时可以处理 3.6 倍的请求。以我们的规模来说,这意味着显著节省了基础设施成本,并使我们能够以更具成本效益的方式将 AI 驱动的应用程序带给更多用户。”
—— Codeway DevOps 负责人 Uğur Arpacı
MaxDiffusion 为图像生成提供了高性能、可扩展且灵活的基础。无论您是经验丰富的计算机视觉专家,还是初涉图像生成领域的新手,MaxDiffusion 都能为您提供支持。
访问我们的 GitHub 存储库以了解有关 MaxDiffusion 的更多信息并立即开始构建您的下一个创意项目。
A3 虚拟机:在 MLPerf™ 4.0 推理中表现出色
2023 年 8 月,我们宣布 A3 VM 正式发布。A3 VM 搭载 8 个 NVIDIA H100 张量核心 GPU,专为训练和服务高要求的生成式 AI 工作负载和 LLM 而打造。搭载 NVIDIA H100 GPU 的 A3 Mega 将于下个月正式发布(即2024年5月已发布),其 GPU 间网络带宽是 A3 的两倍。
在 MLPerf™ Inference v4.0 基准测试中,Google 使用 A3 VM 提交了 7 个模型的 20 个结果,包括新的 Stable Diffusion XL 和 Llama 2 (70B) 基准:
RetinaNet (服务器与离线)
3D U-Net:准确率为 99% 和 99.9%(离线)
BERT:准确率为 99 和 99%(服务器与离线)
DLRM v2:准确率为 99.9%(服务器与离线)
GPT-J:99% and 99% accuracy(服务器与离线)
Stable Diffusion XL(服务器与离线)
Llama 2:准确率为 99% 和 99%(服务器与离线)
所有结果均与 NVIDIA 提交的峰值性能相差 0-5%。这些结果证明了 Google Cloud 与 NVIDIA 的紧密合作,旨在为 LLM 和生成式 AI 构建工作负载优化的端到端解决方案。
借助 Google Cloud TPU 和 NVIDIA GPU 推动 AI 的未来
Google 致力于 AI 推理方面的创新,通过 Google Cloud TPU 和 NVIDIA GPU 的硬件进步,以及 JetStream、MaxText 和 MaxDiffusion 等软件创新,为我们的客户在构建和扩展AI应用程序的过程中提供赋能。利用 JetStream,开发人员可以在 LLM 推理中实现新的性能和成本效率,释放自然语言处理应用的新机遇。MaxDiffusion 提供了一个基础,帮助研究人员和开发人员探索扩散模型的全部潜力,加速图像的生成。我们在由 NVIDIA H100 张量核心 GPU 驱动的 A3 虚拟机上的强大 MLPerf™ 4.0 推理结果展示了 Cloud GPU 的力量和灵活性。
请访问我们的网站了解更多信息并开始使用 Google Cloud TPU 和 GPU 推理。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们