首页 > 资源 > 文章详情
Ironwood:首款适用于 AI 推理时代的 Google TPU

在 Google Cloud Next 25 大会上,我们隆重推出第 7 代 Tensor Processing Unit(TPU)— Ironwood。这不仅是我们迄今为止性能最高、扩展性最佳的定制 AI 加速器,更是第一款专为推理而设计的 TPU。十多年来,TPU 一直为 Google 最严苛的 AI 训练与执行工作负载提供支持,并助力我们的云端客户实现相同目标。Ironwood 是我们至今最强大、功能最全面且能效最高的 TPU,专为大规模驱动思考型(thinking)、推理型(inferential)的 AI 模型而打造。
Ironwood 的问世,代表着 AI 发展及其底层基础架构演进的重大转变。从为人们提供实时信息以供解读的响应式 AI(responsive AI)模型,转向能够主动生成洞察和解读的模型。这就是我们所说的「推理时代」(age of inference),在这个时代,AI agent 将主动检索和生成数据,以协同方式提供洞察与解答,而不仅仅是提供数据。
Ironwood 的构建旨在支持生成式 AI 的下一个发展阶段及其庞大的计算和通信需求。Ironwood 可以扩展到高达 9,216 颗液冷芯片(liquid cooled chips),这些芯片通过突破性的芯片间互连(Inter-Chip Interconnect, ICI)网络相连。它是 Google Cloud AI Hypercomputer 架构的多项新组件之一,该架构旨在整合优化硬件与软件层面,以应对最严苛的 AI 工作负载。通过 Ironwood,开发者还能利用 Google 自家的 Pathways 软件堆栈,可靠且轻松地利用数万个 Ironwood TPU 的组合计算能力。
以下我们将深入探讨这些创新如何协同运作,以无与伦比的性能、成本和能效来处理最严苛的训练与执行工作负载。
以 Ironwood 驱动推理时代
Ironwood 的设计旨在从容应对「思考模型」的复杂计算和通信需求,这类模型涵盖了大语言模型(LLMs)、专家混和模型(Mixture of Experts, MoEs)和进阶推理任务。这些模型需要大规模并行处理能力和高效的内存访问。特别的是,Ironwood 的设计着重于在执行大量的张量运算的同时,最大限度地降低芯片上的数据移动和延迟。在前沿应用方面,思考模型的计算需求远远超出任何单一芯片的处理容量。我们为 Ironwood TPU 设计了低延迟、高带宽的 ICI 网络,以支持在整个 TPU Pod 规模下进行协调且同步的通信。
针对 Google Cloud 客户,Ironwood 根据 AI 工作负载的需求提供两种规模配置:256 颗芯片配置和 9,216 颗芯片配置。
当扩展到每个 Pod 达 9,216 颗芯片时,总运算能力可达 42.5 百亿亿次浮点运算每秒(42.5 Exaflops),是世界上最大的超级计算机 El Capitan 的 24 倍以上,后者每个 Pod 仅提供 1.7 百亿亿次浮点运算每秒(1.7 Exaflops)。Ironwood 提供的大规模并行处理能力,能够支持最严苛的 AI 工作负载,例如用于训练和推理、具备思考能力的超大型密集 LLM 或 MoE 模型。每颗独立芯片的峰值计算能力高达 4,614 万亿次浮点运算每秒(4,614 TFLOPs),代表着 AI 能力的巨大飞跃。此外,Ironwood 的内存和网络架构确保了在如此庞大的规模下,始终能够提供正确的数据可支持峰值性能。
Ironwood 还配备了增强版的 SpaceCore,这是一种专门用于处理高级排名和推荐系统工作负载中常见的超大规模嵌入(embeddings)的加速器。Ironwood 对 SpaceCore 的支持扩大,使其能加速更广泛的工作负载,甚至跨越传统 AI 领域,进入金融和科学等领域。
Google DeepMind 开发的机器学习运行时架构 Pathways,能在多个 TPU 芯片间实现高效的分布式计算。Google Cloud 上的 Pathways 让使用者能轻易超越单个 Ironwood Pod 的限制,将数十万颗 Ironwood 芯片组合在一起,以快速推进生成式 AI 计算的前沿发展。
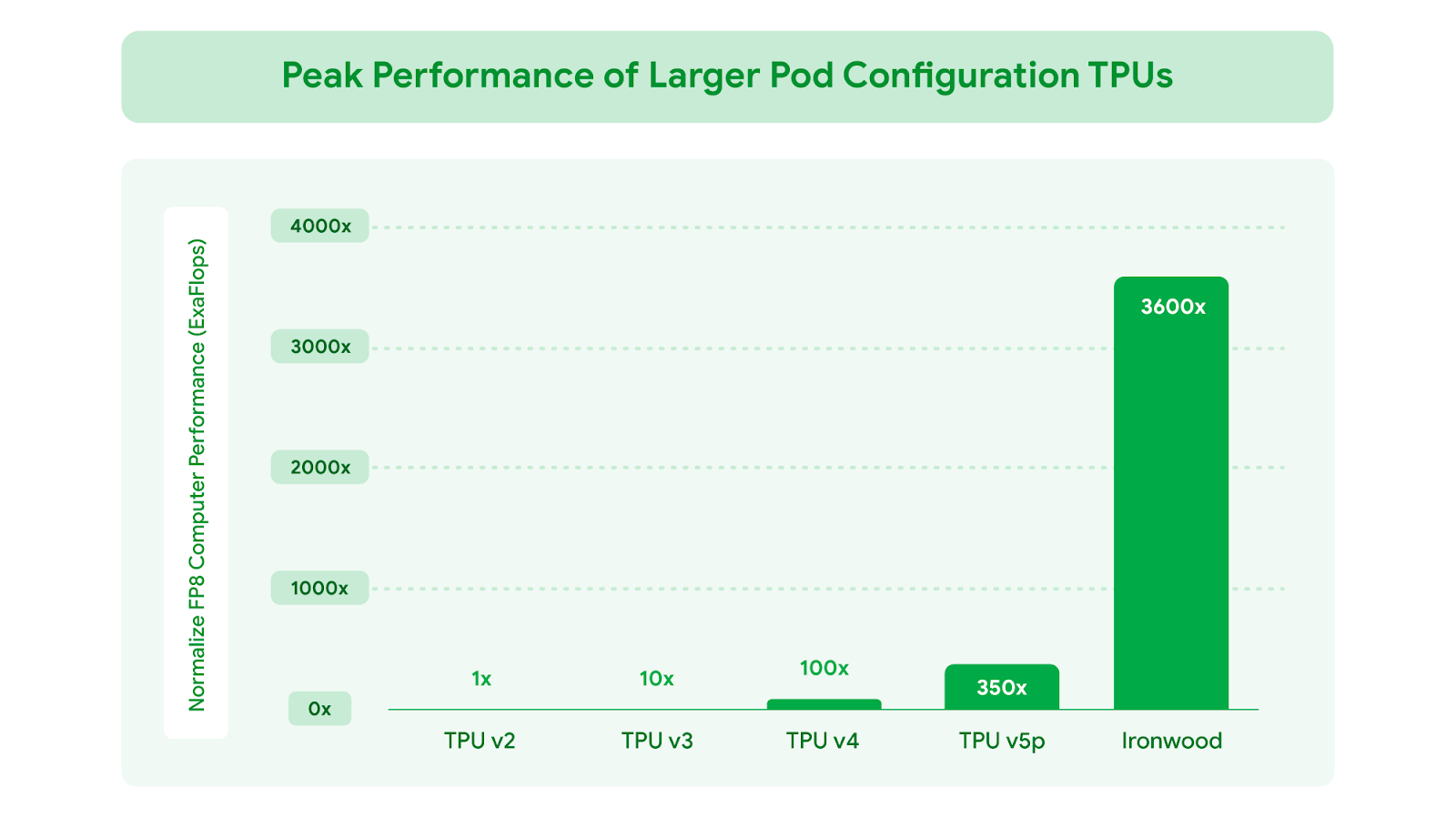
图一:相较于 Google 首款对外提供的 Cloud TPU v2,FP8 总峰值浮点运算性能提升幅度。
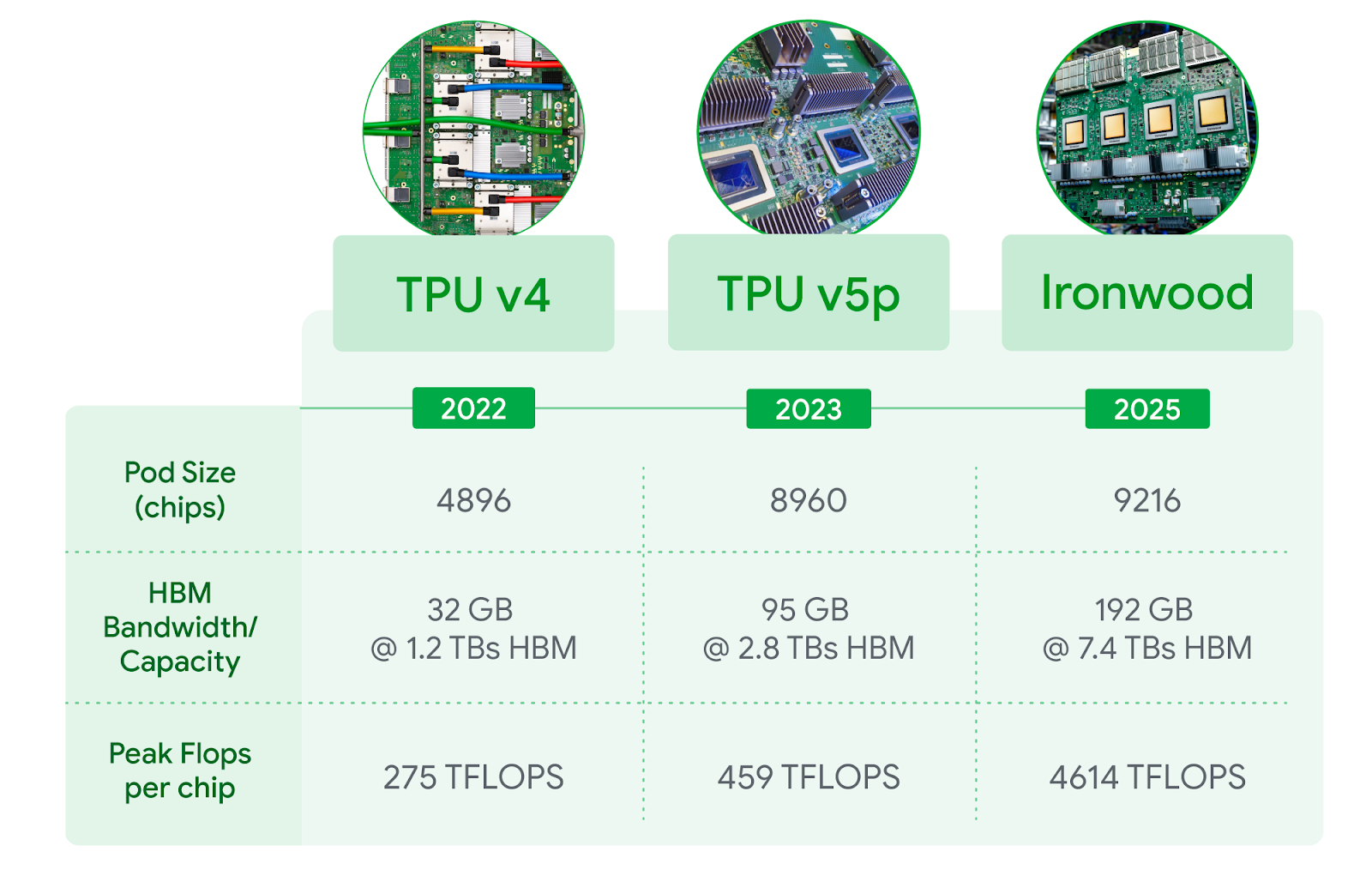
图二:包括最新一代 Ironwood 在内的 Cloud TPU 产品(3D 环形拓扑结构, 3D torus version)技术规格并列比较。FP8 峰值 TFlops 在 v4 与 v5p 上为模拟值,Ironwood 则提供原生支持。
Ironwood 的主要功能
Google Cloud 是唯一一家拥有超过十年提供 AI 计算经验的超大规模云提供商,不仅支持尖端研究,更将这些技术无缝整合到全球规模等级的服务中,每天为数十亿使用者提供 Gmail、Google 搜索等服务。这些专业知识正是 Ironwood 性能的核心所在。主要功能包括:
在性能大幅提升的同时也注重能效,使 AI 工作负载能够以更符合成本效益的方式运行。Ironwood 的性能功耗比是 2024 年推出的第 6 代 TPU Trillium 的 2 倍。在当前可用电力成为 AI 发展限制因素之一的时代,我们为客户的工作负载提供了每瓦更多的计算能力。我们先进的液冷解决方案和优化的芯片设计,即使面对持续繁重的 AI 工作负载,也能可靠地维持高达标准风冷两倍的性能。事实上,Ironwood 的能效较我们 2018 年推出的首款 Cloud TPU 提升近 30 倍。
大幅增加高带宽内存(HBM)容量。Ironwood 每颗芯片提供 192 GB 容量,是 Trillium 的 6 倍,能处理更大的模型和数据集计算,减少频繁的数据传输需求,进而提升整体性能。
HBM 带宽大幅提升,单颗芯片可达 7.2 Tbps,是 Trillium 的 4.5 倍。这种高带宽能确保数据快速访问,这对于现代 AI 中常见的内存密集型工作负载至关重要。
增强芯片间互连(ICI)带宽。双向传输已提高到 1.2 Tbps,是 Trillium 的 1.5 倍,能加速芯片间的通信,有助于提升大规模分布式训练和推理的效率。
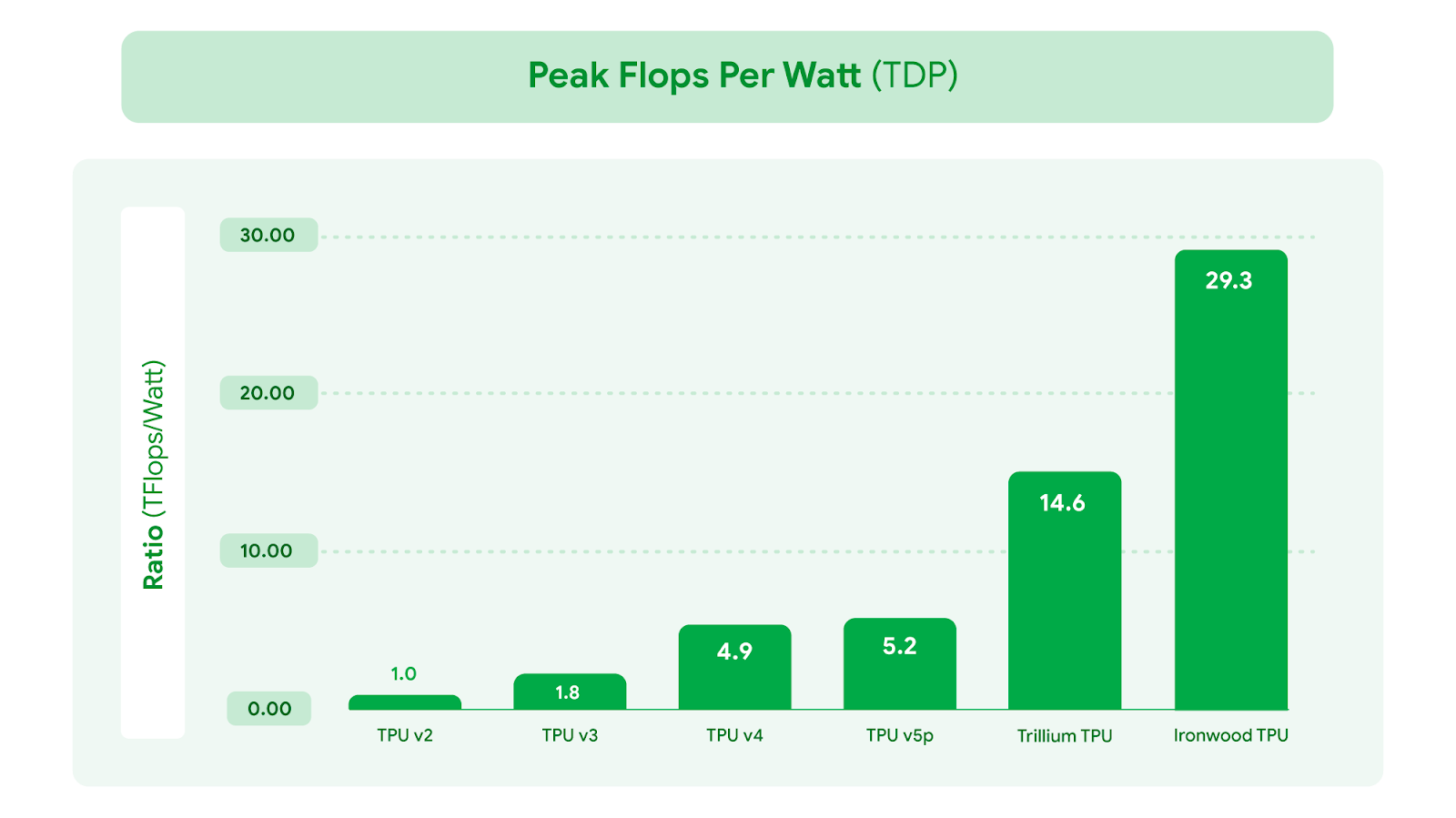
图三:相较于最早的 Cloud TPU v2,Google TPU 的能效有显著提升。此数据是以每颗芯片封装在热设计功耗(TDP)下所能达到的 FP8 峰值运算性能(flops per watt)进行衡量。
Ironwood 满足了未来 AI 的需求
Ironwood 凭借其全面提升的计算能力、内存容量、芯片互连技术进展与可靠性,代表推理时代的一项独特关键突破。这些突破,加上近 2 倍的能效提升,意味着我们需求最高的客户能以最高的性能与最低的延迟来处理训练与推理执行工作负载,同时满足暴增的计算需求。当前尖端 AI 模型如 Gemini 2.5 和荣获诺贝尔奖的 AlphaFold,如今都在 TPU 上运行。我们迫不及待地想看到我们自己的开发人员和 Google Cloud 客户在 Ironwood 今年晚些时候推出后,会激发出哪些 AI 领域的突破。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们