首页 > 资源 > 文章详情
节省 GPU 成本:更智能地自动扩缩您的 GKE 推理工作负载

虽然 LLM 为越来越多的用例提供了巨大的价值,但运行 LLM 推理工作负载的成本可能会非常的高。如果您正在利用最新的开放模型和基础设施,自动扩缩可以帮助您优化成本,在确保您满足可以客户需求的同时,只需支付所需的 AI 加速器支付费用。
作为一项托管的容器编排服务,Google Kubernetes Engine(GKE)让您可以轻松部署、管理和扩缩 LLM 推理工作负载。在 GKE 上设置推理工作负载时,请考虑使用 Pod 横向自动扩缩(HPA),这是一种高效而简单的方法,可确保您的模型服务器根据负载进行适当的扩缩。通过微调 HPA 设置,您可以将预配的硬件成本与传入流量需求相匹配,以实现所需的推理服务器性能目标。
为 LLM 推理工作负载配置自动扩缩也具有一定的挑战性,因此我们利用 ai-on-gke/benchmarks 比较了 GPU 上的自动扩缩的多个指标,来为您提供最佳实践。此设置使用文本生成推理(TGI)模型服务器和 HPA。请注意,这些实验适用于实现类似指标的其他推理服务器,例如 vLLM。
选择正确的指标
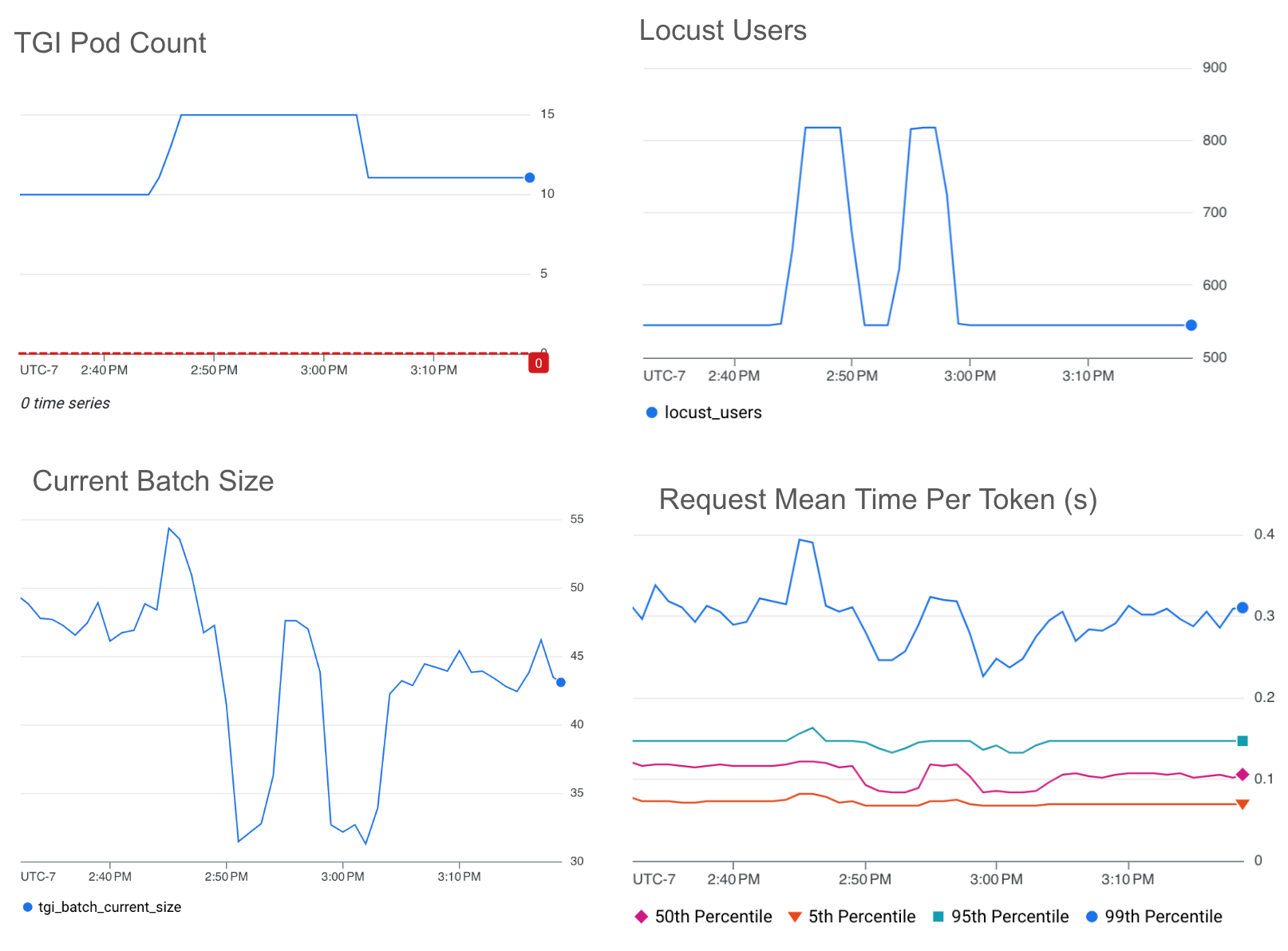
下面,您将看到来自我们指标比较的一些示例实验,这些实验使用 Cloud Monitoring 仪表板实现了可视化。对于每个实验,我们在一台 L4 GPU g2-standard-16 机器上使用 Llama 2 7b 运行了 TGI,并使用 HPA 自定义指标 Stackdriver 适配器和 ai-on-gke locust-load-generation 工具生成具有不同请求大小的流量。我们在下面显示的每个实验中使用了相同的流量负载。下面的阈值是通过实验确定的。
请注意,mean-time-per-token 图是 TGI 的指标,即预填充和解码的总持续时间除以每个请求生成的输出令牌数。此指标使我们能够比较使用不同指标的自动扩缩对延迟的影响。
GPU 利用率
自动扩缩的默认指标是 CPU 或内存利用率。这对于在 CPU 上运行的工作负载非常有效。但是,对于推理服务器,这些指标不再是作业资源利用率的唯一指标,因为推理服务器主要依赖于 GPU。GPU 的等效指标是 GPU 利用率。GPU 利用率表示 GPU 占空比,即 GPU 处于活动状态的时间量。
下图显示了 HPA 在 GPU 利用率上的自动扩缩,目标值阈值为 85%。
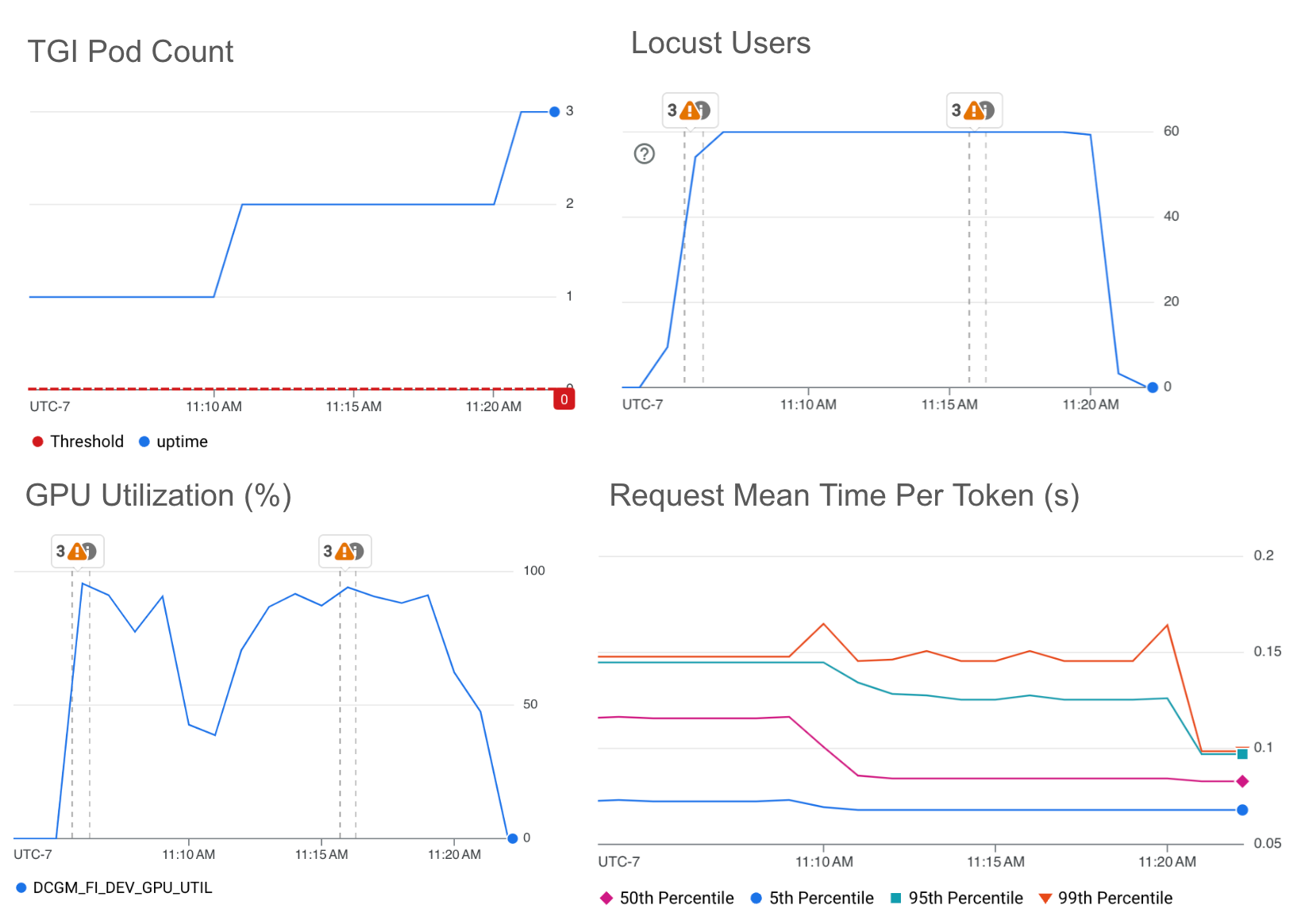
GPU 利用率图与每个令牌的平均请求时间没有明确的关系。即使每令牌的平均请求时间正在减少,GPU 利用率仍会继续增加,从而导致 HPA 继续扩大规模。对于 LLM 自动扩缩,GPU 利用率不是一个有效的指标。很难将此指标映射到推理服务器正在经历的当前流量。GPU 占空比指标不衡量浮点运算利用率,因此它无法表明加速器正在执行多少工作,也无法表明加速器何时以最大容量运行。与下面的其他指标相比,GPU 利用率往往过度预置,这使得成本效率低下。
简而言之,我们不建议使用 GPU 利用率来自动扩缩推理工作负载。
批次大小
考虑到 GPU 利用率指标的局限性,我们还探索了 TGI 提供的 LLM 服务器指标。我们探索的 LLM 服务器指标已由最流行的推理服务器提供。
我们选择的选项之一是批次大小(tgi_batch_current_size),它表示每次推理迭代中处理的请求数。
下图显示了 HPA 在当前批次大小上的自动扩缩,目标值阈值为 35。

当前批次大小图与请求平均每个令牌时间图之间存在直接关系。较小的批次大小表示较小的延迟。批次大小是优化低延迟的一个很好的指标,它直接表明推理服务器当前正在处理的流量。当前批次大小指标的一个限制是,在尝试实现最大批次大小并因此实现最大吞吐量时,不容易触发扩缩,因为批次大小会随着不同的传入请求大小而略有不同。我们必须选择一个略低于最大批次大小的值,以确保 HPA 会触发扩缩。
如果您希望针对特定的尾延迟,我们建议您使用当前批次大小指标。
队列大小
我们从 TGI LLM 服务器指标中选择的另一个选项是队列大小(tgi_queue_size)。队列大小表示在添加到当前批次之前在推理服务器队列中等待的请求数。
下图显示了 HPA 对队列大小的扩缩,目标值阈值为 10。
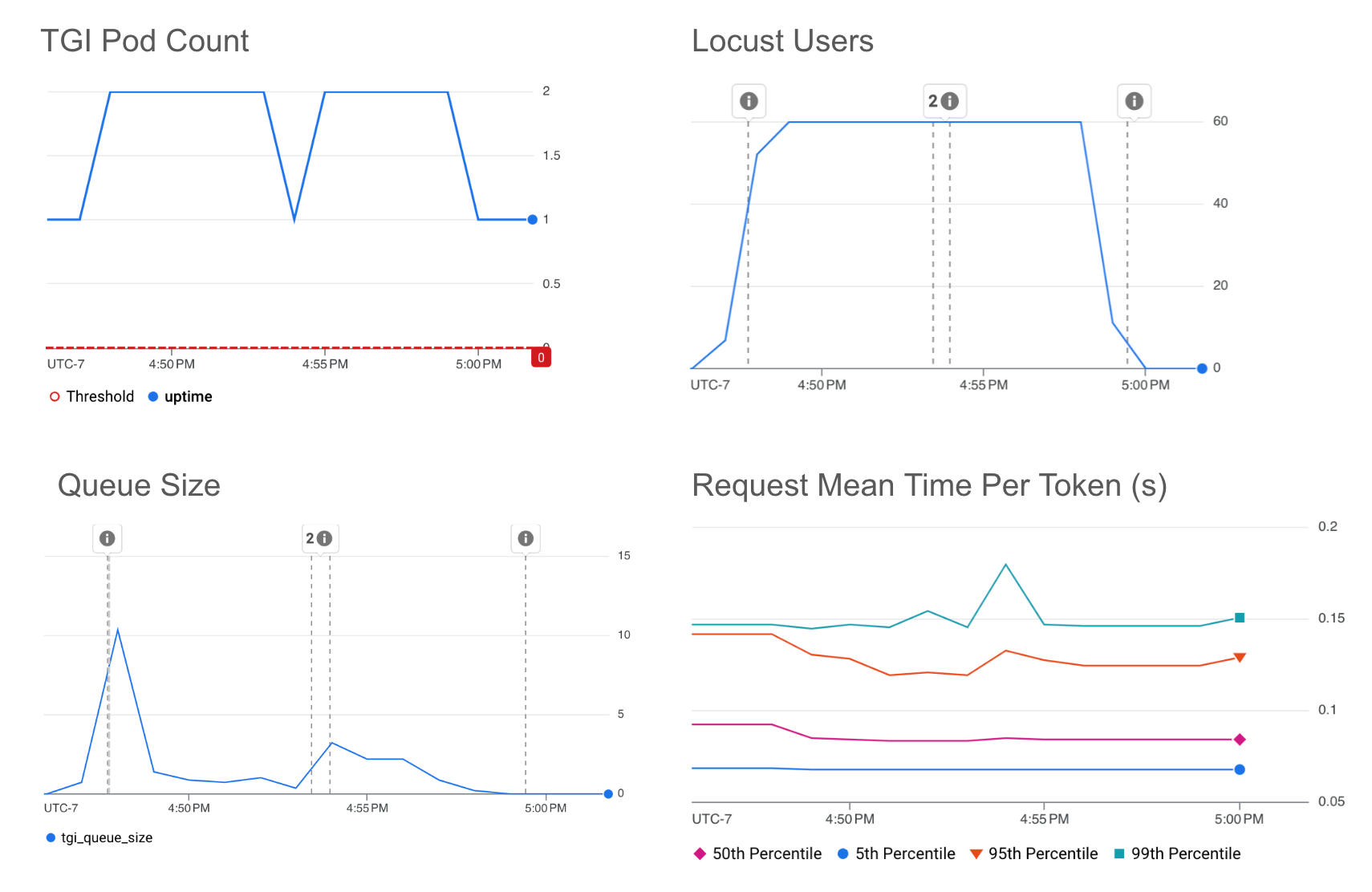
*请注意,当 HPA 在默认的五分钟稳定期结束后触发缩减时,Pod 数量会下降。您可以轻松微调此稳定期窗口以及其他默认 HPA 配置选项,以满足您的流量需求。
我们看到队列大小图和每令牌平均请求时间图之间存在直接关系。队列大小越大,延迟越高。我们发现队列大小是自动扩缩推理工作负载的一个很好的指标,它直接表明推理服务器正在等待处理的流量。队列不断增长表示批处理已满。由于队列大小仅与队列中的请求数有关,而不是当前正在处理的请求数,因此队列大小的自动扩缩无法实现与批处理大小一样低的延迟。
如果您希望最大化吞吐量同时控制尾延迟,我们建议利用队列大小。
确定目标值阈值
为了进一步展示队列和批次大小指标的强大功能,我们使用了 ai-on-gke/benchmarks 中的 profile-generator 来确定这些实验要使用的阈值。我们相应地选择了阈值:
为了表示最佳吞吐量工作负载,我们确定了吞吐量不再增长、只有延迟增长点的队列大小。
为了表示对延迟敏感的工作负载,我们选择在延迟阈值约为最佳吞吐量的 80% 左右时自动扩缩批处理大小。
下面是我们使用 ai-on-gke/benchmarks 中的 the profile-generator 的数据创建的吞吐量与延迟图:
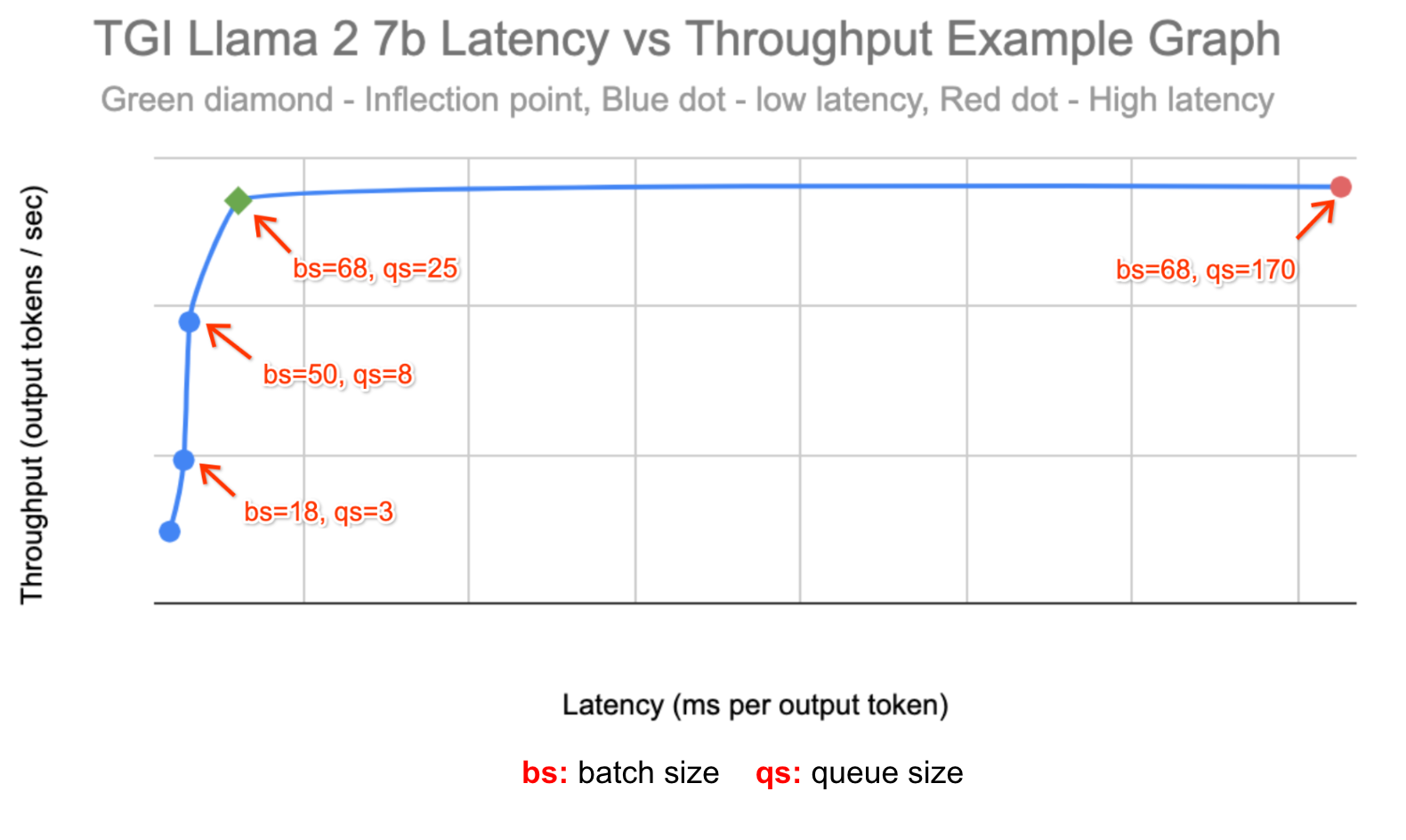
对于每个实验,我们在两台 g2-standard-96 机器上的单个 L4 GPU 上运行了 TGI 和 Llama 2 7b,并使用 HPA 自定义指标 stackdriver 实现了 1 到 16 个副本之间的自动扩缩。我们使用 ai-on-gke locust-load-generation 工具生成具有不同请求大小的流量。我们确定了一个稳定在约 10 个副本的负载,然后通过将负载增加 150% 来模拟流量高峰。
队列大小
下图显示了 HPA 对队列大小的扩展,目标值阈值为 25。
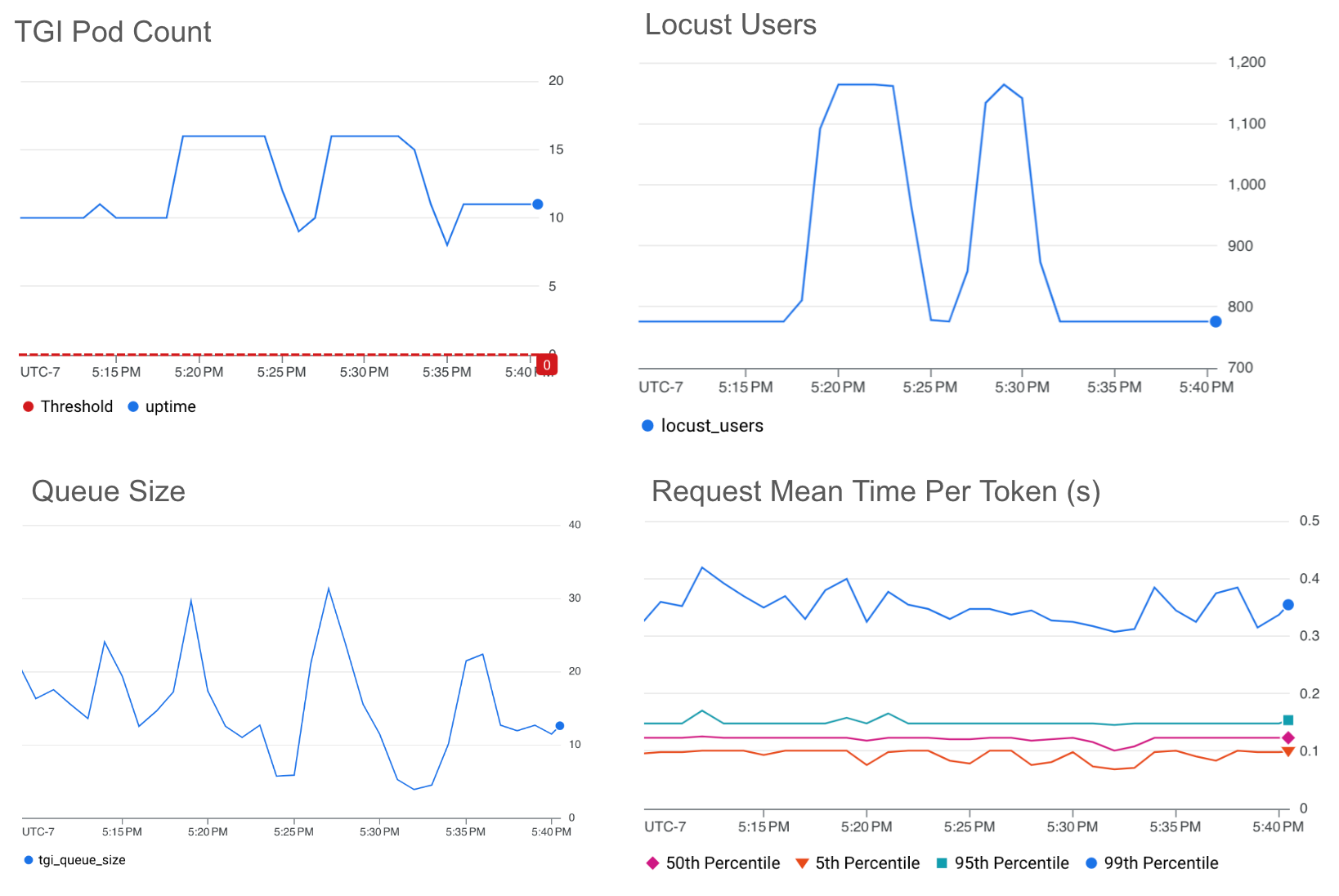
我们看到,即使流量激增 150%,我们的目标阈值也能够将每个令牌的平均时间维持在~0.4 秒以下。
批次大小
下图显示了 HPA 在批量大小上的扩缩,目标值阈值为 50。
*请注意,平均批次大小下降约 60% 与流量下降约 60% 有关。
我们看到,即使流量激增 150%,我们的目标阈值也能够将每个令牌的平均时间维持在几乎低于~0.3 秒的水平。
与在最大吞吐量时选择的队列大小阈值相比,在最大吞吐量的约 80% 时选择的批量大小阈值维持了 < ~80% 的平均每令牌时间。
实现更好的自动扩缩
使用 GPU 利用率进行自动扩缩可能会导致您过度配置 LLM 工作负载,从而增加不必要的成本,无法实现您的性能目标。
使用 LLM 服务器指标进行自动扩缩将使您能够实现延迟或吞吐量目标,同时在加速器上花费最少的钱。批处理大小使您能够针对特定的尾延迟。队列大小使您能够优化吞吐量。
有关如何使用这些最佳实践为您自己的 LLM 推理服务器设置自动扩缩的说明,请按照使用 Google Kubernetes Engine 在 GPU 上为 LLM 工作负载配置自动扩缩中概述的步骤进行操作。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们