首页 > 资源 > 文章详情
最大限度地提高 GKE 上 GPU 的 LLM 服务吞吐量 — 实用指南

让我们面对现实:提供 AI 基础模型(例如 LLM)的成本可能是非常高昂的。由于需要硬件加速器来实现更低的延迟,而这些加速器通常并没有被有效的利用,因此组织需要一个能够大规模提供 LLM 的 AI 平台,同时最大限度地去降低每个令牌的成本。通过工作负载和基础架构自动扩缩以及负载平衡等功能,Google Kubernetes Engine(GKE)可以帮助您实现这一目标。
将 LLM 集成到应用程序中时,您需要考虑如何以经济高效的方式提供服务,同时仍在一定延迟范围内提供最高吞吐量。为了提供帮助,我们为 GKE 创建了一个性能基准测试工具,该工具可自动执行端到端设置(从集群创建到推理服务器部署和基准测试),您可以使用它来衡量和分析这些性能权衡。
以下是一些建议,可以帮助您最大限度地提高 GKE 上 NVIDIA GPU 的服务吞吐量。将这些建议与性能基准测试工具相结合,将使您能够在 GKE 上设置推理堆栈时做出数据驱动的决策。我们还讨论了如何针对给定的推理工作负载优化模型服务器平台。
基础架构决策
在选择适合您的模型且具有成本效益的基础架构时,您需要回答以下问题:
1. 您是否应该量化您的模型?如果是,您应该使用哪种量化?
2. 您如何选择适合您的模型的机器类型?
3. 您应该使用哪种 GPU?
让我们更深入地探讨这些问题。
1. 您是否应该量化您的模型?如果是,您应该使用哪种量化?
量化是一种减少加载模型权重所需加速器内存量的方法;它通过使用较低精度的数据类型来表示权重和激活来实现这一点。量化可以节省成本,并且由于内存占用较少,可以提高延迟和吞吐量。但在某个时候,量化模型会导致模型准确度明显下降。
在量化类型中,FP16 和 Bfloat16 量化提供的精度几乎与 FP32 相同(取决于模型,如本文所示),但内存使用量却只有一半。大多数较新的模型检查点已以 16 位精度发布。FP8 和 INT8 可将模型权重的内存使用量减少高达 50%(如果模型服务器未单独量化,KV 缓存仍将消耗类似的内存),通常准确度损失最小。
4 位或更低的量化(如 INT4 或 INT3)会导致准确度下降。在使用 4 位量化之前,请务必评估模型准确度。还有一些训练后量化技术(如激活感知量化(AWQ))可以帮助减少准确度损失。
您可以使用我们的自动化工具采用不同的量化技术部署您选择的模型,并对其进行评估以了解它如何满足您的需求。
建议 1:使用量化来节省内存和成本。如果使用低于 8 位的精度,请在评估模型准确率后再使用。
2. 您如何选择适合您的模型的机器类型?
计算所需机器类型的一个简单方法是考虑模型中的参数数量和模型权重的数据类型。
模型大小(以字节为单位)= 模型参数数量 * 数据类型(以字节为单位)
因此,对于使用 16 位精度量化技术(例如 FP16 或 BF16)的 7b 模型,您需要:
70 亿 * 2 字节 = 140 亿字节 = 14 GiB
同样,对于 8 位精度的 7b 模型(例如 FP8 或 INT8),您需要:
70 亿 * 1 字节 = 70 亿字节 = 7 GiB
在下表中,我们应用了这些指南来显示一些流行的开放重量 LLM 可能需要多少加速器内存。
模型 | 模型实体(参数数量) | 模型大小(所需 GPU 内存,以 GB 为单位) | ||
| FP16 | 8 位精度 | 4 位精度 | ||
| Gemma | 2b | 4 | 2 | 1 |
| 7b | 14 | 7 | 3.5 | |
| LIama 3 | 8b | 16 | 8 | 4 |
| 70b | 140 | 70 | 35 | |
| FaIcon | 7b | 14 | 14 | 3.5 |
| 40b | 80 | 40 | 20 | |
| 180b | 360 | 180 | 90 | |
| BIoom | 176b | 352 | 176 | 88 |
注意:上表仅供参考。确切的参数数量可能与模型名称中提到的参数数量不同,例如 Llama 3 8b 或 Gemma 7b。对于开放模型,您可以在 Hugging Face 模型卡页面中找到确切的参数数量。
最佳实践是选择一个加速器,该加速器最多可为模型权重分配 80% 的内存,从而为 KV 缓存(模型服务器用于高效令牌生成的键值缓存)节省 20%。例如,对于具有单个 NVIDIA L4 Tensor Core GPU(24GB)的 G2 机器类型,您可以将 19.2GB 用于模型权重(24 * 0.8)。根据令牌长度和提供的请求数,您可能需要高达 35% 的 KV 缓存。对于非常长的上下文长度(如 1M 令牌),您需要为 KV 缓存分配更多内存,并期望它主导内存使用。
建议 2:根据模型的内存需求选择 NVIDIA GPU。当单个 GPU 不够用时,请使用具有张量并行性的多 GPU 分片。
3. 您应该使用哪种 GPU?
GKE 提供多种由 NVIDIA GPU 支持的虚拟机。您如何决定使用哪个 GPU 来为您的模型提供服务?
下表列出了用于运行推理工作负载的流行 NVIDIA GPU 列表及其性能特征。
| Compute Engine Instance | NVIDIA GPU | 内存 | HBM 带宽 | 混合精度 FP16/FP32/bfloat16 Tensor 核心峰值计算 |
| A3 | NVIDIA H100 Tensor Core GPU | 80 GB | HBM3 @ 3.35 TBps | 1,979 TFLOPS |
| A2 ultra | NVIDIA A100 80GB Tensor Core GPU | 80 GB | HBM2e @ 1.9 TBps | 312 TFLOPS |
| A2 | NVIDIA A100 40GB Tensor Core GPU | 40 GB | HBM2 @ 1.6 TBps | 312 TFLOPS |
| G2 | NVIDIA L4 Tensor Core GPU | 24 GB | GDDR6 @ 300 GBps | 242 TFLOPS |
注意:A3 和 G2 VM 支持结构稀疏性,您可以使用它来提高性能。显示的值具有稀疏性。如果没有稀疏性,列出的规格会低一半。
根据模型的特点,吞吐量和延迟可以受三个不同维度的限制:
1. 吞吐量可能受 GPU 内存(GB/GPU)限制:GPU 内存保存模型权重和 KV 缓存。批处理可提高吞吐量,但 KV 缓存增长最终会达到内存限制。
2. 延迟可能受 GPU HBM 带宽(GB/s)限制:根据内存带宽,会读取生成的每个 token 的模型权重和 KV 缓存状态。
3. 对于较大的模型,延迟可能受 GPU FLOPS 限制:张量计算依赖于 GPU FLOPS。隐藏层和注意力头越多,表示使用的 FLOPS 越多。
在选择适合您的延迟和吞吐量需求的最佳加速器时,请充分考虑这些维度。
下面,我们比较了 Llama 2 7b 和 Llama 2 70b 模型的 G2 和 A3 的吞吐量/费用。该图表使用标准化吞吐量/费用,其中 G2 的性能设置为 1,并将 A3 的性能与其进行比较。
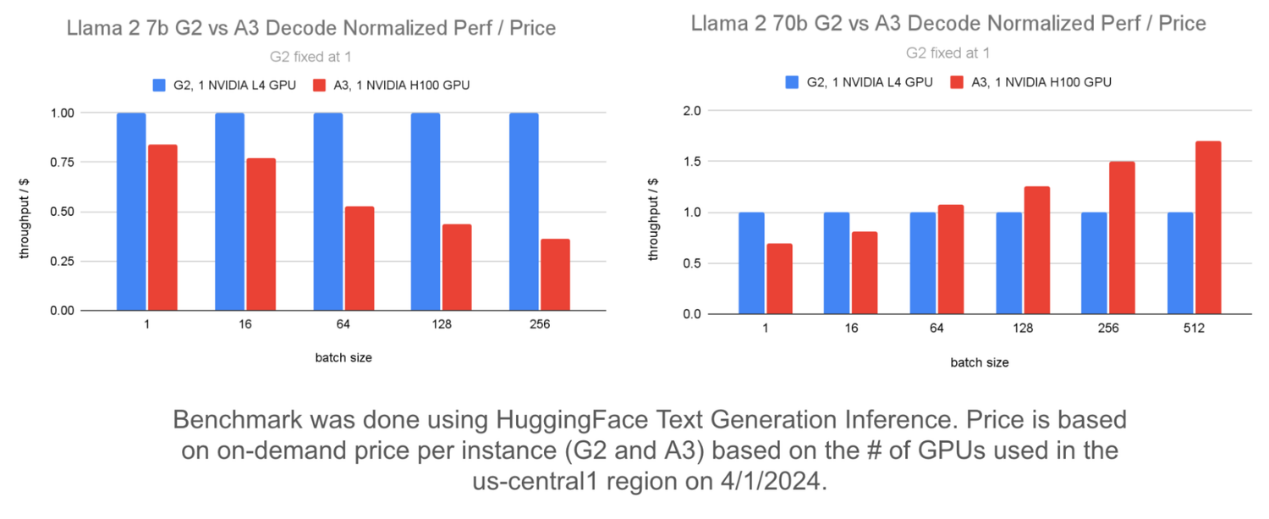
左侧图表显示,在批次大小较大的情况下,Llama 2 7b 模型使用 G2 提供的吞吐量/费用比 A3 更高。右侧图表显示,在使用多个 GPU 为 Llama 2 70b 模型提供服务时,在批次大小较大的情况下,A3 提供的吞吐量/费用比 G2 更高。Falcon 7b 和 Flan T5 等其他类似尺寸的模型也是如此。
您可以选择所需的 GPU 机器并使用我们的自动化工具创建 GKE 集群,然后可以使用它来运行您选择的模型和模型服务器。
建议 3:对于参数为 7b 或更少的模型,只要延迟可以接受,请使用 G2 以获得更好的性价比。对于更大的模型,请使用 A3。
模型服务器优化
有多个模型服务器可用于在 GKE 上为您的 LLM 提供服务:HuggingFace TGI、JetStream、NVIDIA Triton 与 TensorRT-LLM 以及 vLLM。一些模型服务器支持重要的优化,如批处理、PagedAttention、量化等,这些优化可以提高 LLM 的整体性能。以下是在为 LLM 工作负载设置模型服务器时需要询问的几个问题。
如何针对输入量大和输出量大的用例进行优化?
LLM 推理涉及两个阶段:预填充和解码。
1. 预填充阶段并行处理提示词中的令牌并构建 KV 缓存。与解码阶段相比,该操作具有更高的吞吐量和更低的延迟。
2. 解码阶段紧随预填充阶段,其中根据 KV 缓存状态和先前生成的令牌按顺序生成新令牌。与预填充阶段相比,该操作具有更低的吞吐量和更高的延迟。
根据您的用例,您可能会有更大的输入长度(例如摘要、分类)、更大的输出长度(内容生成)或两者之间相当均匀的分割。
下面显示了 G2 和 A3 预填充吞吐量的比较。

图表显示,A3 的预填充吞吐量是 G2 的 13.8 倍,成本仅为 G2 的 5.5 倍。因此,如果您的用例具有较大的输入长度,那么 A3 的每美元吞吐量将提高 2.5 倍。
您可以使用基准测试工具模拟适合您需求的不同输入/输出模式并验证其性能。
建议 4:在输入提示词比输出提示词长得多的模型上使用 A3 可获得更好的性价比。分析模型的输入/输出模式,并选择可为您的用例提供最佳性价比的基础架构。
批处理会对性能产生何种影响?
批处理请求对于实现更高的吞吐量至关重要,因为它们可以利用更多的 GPU 内存、HBM 带宽和 GPU FLOPS,而不会增加成本。
下面使用固定输入/输出长度和静态批处理对不同批次大小的比较显示了对吞吐量和延迟的影响。
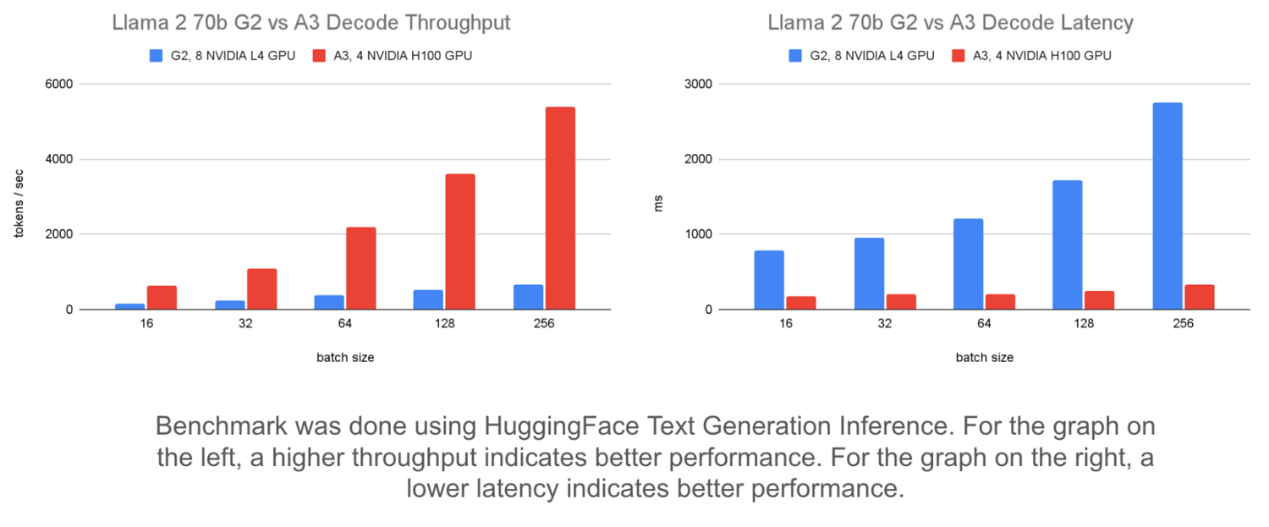
左侧图表显示,将批次大小从 16 增加到 256 可将 A3 上运行的 Llama 2 70b 模型的吞吐量提高多达 8 倍。它可将 G2 上的吞吐量提高多达 4 倍。
右侧图表显示了批处理如何影响延迟。在 G2 上,延迟增加了 1,963 毫秒。但在 A3 上,延迟增加了 155 毫秒。这表明 A3 可以处理更大的批次大小,延迟增加最小,直到批次大小大到足以受到计算限制。
选择理想的批次大小涉及到增加批次的规模,直到达到延迟目标或吞吐量不再提高。您可以使用基准测试工具提供的监控自动化来监控模型服务器的批次大小。然后,您可以使用它来确定设置的理想批次大小。
建议 5:使用批处理来提高吞吐量。最佳批次大小取决于您的延迟要求。选择 A3 可降低延迟。如果可以接受稍高的延迟,则选择 G2 可节省资金。
最大限度地利用 GPU
在本篇博文中,您了解了模型特性、基础架构选择和模型服务器优化如何决定模型服务性能。这强调了在不同条件下测量模型性能以及确定理想设置以最大化 GKE 上的服务吞吐量的重要性。要开始使用,请参考 ai-on-gke/benchmarks 存储库中列出的步骤进行操作。
要在 GKE 上的 A3 或 G2 机器上部署推理工作负载,请按照 Gemma on Triton、Gemma on TGI 或 Gemma on vLLM 中列出的步骤操作,这些步骤分别演示了如何分别使用 TensorRT-LLM、HuggingFace TGI 和 vLLM 在 Triton 上部署 Gemma-7b 和 Gemma-2b 模型。有关使用 TGI 和 vLLM 部署这些优化技术的更多示例,请参阅在 GKE 上优化模型和服务配置。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们