首页 > 资源 > 文章详情
Google Cloud 上的 Gemma 性能深入剖析

今年早些时候,我们宣布推出了 Gemma,它是一系列开放式权重模型,设计初衷就是为了支持开发人员在 Google Cloud 上快速试验、调整模型并将其投入生产环境。Gemma 模型可以在您的笔记本电脑、工作站上运行,也可以使用您选择的 Cloud GPU 或 Cloud TPU,通过 Vertex AI 或 Google Kubernetes Engine (GKE) 在 Google Cloud 上运行。这包括使用 PyTorch 和 JAX、利用 Cloud GPU 上的 vLLM、HuggingFace TGI 和 TensorRT LLM 以及 Cloud TPU 上的 JetStream 和 Hugging Face TGI (Optimum-TPU) 进行训练、微调和推理。
我们的基准测试结果表明,与作为基准的 Llama-2 训练性能相比,使用 Cloud TPU v5e 的 Gemma 模型的训练效率提高到原来的 3 倍(性价比更高)。本周早些时候,我们发布了 JetStream,这是一个经济实惠且性能较高的全新推理引擎。我们分析了 Gemma 在 Cloud TPU 上的推理性能,发现与我们用作基准的先前 TPU 推理堆栈相比,当通过 JetStream 应用 Gemma 时,LLM 推理的推理效率提高到原来的 3 倍(推理性价比更高)。
在这篇博文中,我们将介绍 Gemma 模型在 Google Cloud 加速器上的训练性价比和推理性价比。我们展示的结果是根据截至 2024 年 4 月的数据得出的。我们预计,通过开源社区、企业用户和 Google 团队的积极贡献,这些模型的基础架构效率和质量将会不断改进和提高。
背景:Gemma 模型架构详细信息
Gemma 系列模型包含两个变体:Gemma 2B 和 Gemma 7B(密集型解码器架构)。对于 2B 和 7B 模型,我们分别使用 2 万亿和 6 万亿个词元对 Gemma 进行了预训练,模型训练的上下文长度为 8,192 个词元。上述两个模型的头部维度均为 256,并且这两个变体都利用旋转式位置编码 (RoPE)。

Gemma 7B 模型利用的是多头注意力机制,而 Gemma 2B 利用的是多查询注意力机制。此方法有助于降低推理过程中对内存带宽的要求,这对于 Gemma 2B 设备端推理场景可能是有利的,因为在该场景下,内存带宽通常是有限的。
Gemma 训练性价比
要评估给定模型或一系列大小类似的模型的训练基础架构,需要关注两个重要维度:1) 有效的模型 FLOP 利用率;2) 相对性价比。
有效的模型 FLOP 利用率
模型 FLOP 利用率 (MFU) 是指模型吞吐量(即模型每秒实际执行的浮点运算次数)与底层训练基础架构吞吐量峰值之间的比率。我们使用每个训练步骤的浮点运算次数和单步用时的分析估算值来计算模型吞吐量(参考 PaLM)。当应用于混合精度训练设置 (Int8) 时,生成的指标称为“有效的模型 FLOP 利用率 (EMFU)”。在其他条件相同的情况下,MFU(或 EMFU)越高,表示性价比越高。MFU 的提升意味着训练成本的降低。
Gemma 训练设置
Google 内部使用 TPU v5e 对 Gemma 模型进行了预训练。Gemma 2B 采用了两个 v5e-256;Gemma 7B 采用了 16 个 Cloud TPU v5e-256。
我们测量了 Cloud TPU 上 Gemma 模型的 MFU(或 EMFU)。由于 Cloud TPU v5e 和 Cloud TPU v5p 都是最新一代的 Cloud TPU(截至撰写这篇博文时),我们将向您展示 Gemma 模型在这两类 Cloud TPU 上的性能表现。就性价比而言,Cloud TPU v5e 是迄今为止最具成本效益的 Cloud TPU。相比之下,Cloud TPU v5p 是功能最强大且可伸缩的 Cloud TPU,适用于更复杂的 LLM 架构,例如混合专家以及大规模排名和推荐系统等替代工作负载。
下图显示了使用 bf16 精度和混合精度 (int8) 训练(使用 AQT)的 Gemma 2B 和 Gemma 7B 训练运行的 EMFU。
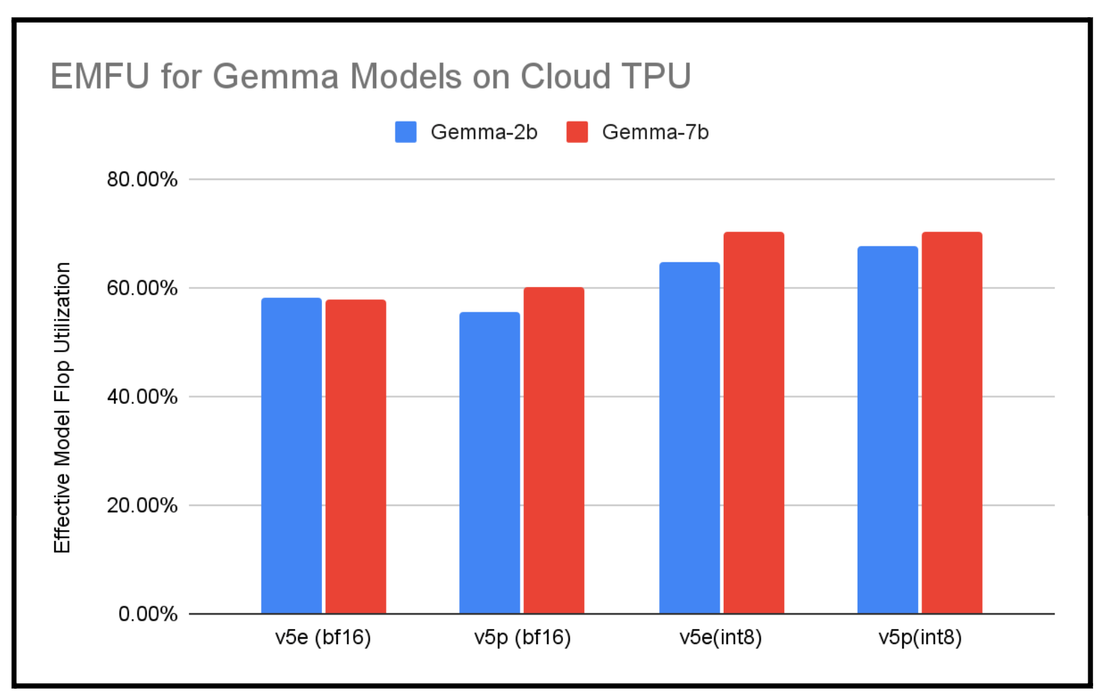
Gemma 2B 和 7B 有效的模型 Flop 利用率。在 TPU v5e-256 和 v5p-128 上使用 MaxText 进行衡量。上下文长度为 8,192。截至 2024 年 2 月的数据。
这些结果是使用 MaxText 参考实现计算得出的。我们还提供了使用 Hugging Face Transformers 训练和微调 Gemma 模型的实现方法。
使用 MaxText 实现高性能训练
我们认识到,由于模型架构、训练参数(例如上下文长度)以及底层集群规模的差异,比较不同类型模型的训练基础架构性能会是一个难题。我们选择将 Llama 2 已发布的结果(词元总数和总 GPU 小时数)作为与 Gemma 7B 训练进行比较的基准,原因如下:
1.模型架构与 Gemma 7B 相似
2.由于 Gemma 7B 是采用 2 倍的上下文长度进行训练的,此类比较有利于 Llama 2 基准
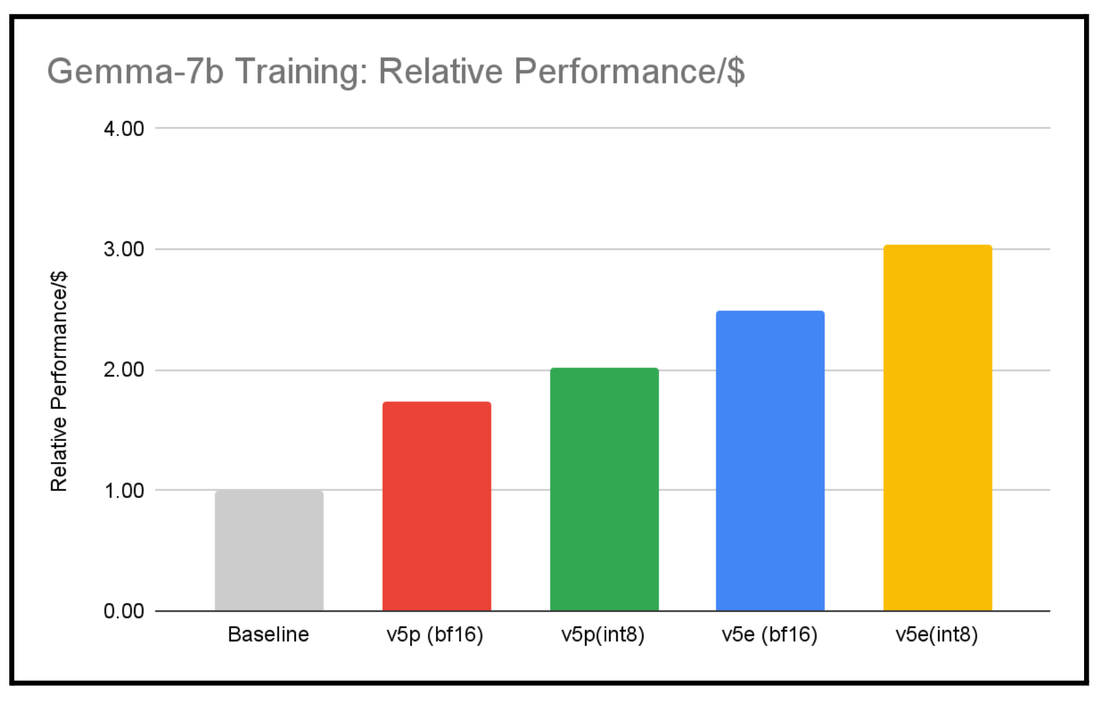
Gemma 7B 与基准的相对训练性价比。在 TPU v5e-256 和 v5p-128 上使用 Gemma 7B (MaxText) 进行衡量。上下文长度为 8,192。基准 (LLama2-7b) 性价比是根据已发布的结果,使用总 GPU 小时数和总训练词元数计算得出的。性价比是根据各个加速器的定价计算得出的。截至 2024 年 2 月的数据。
我们计算性价比的方法如下:(峰值 FLOP*EMFU)/(虚拟机实例的定价)。使用 MaxText 参考实现后,我们发现,Gemma 7B 模型的性价比是基准训练性价比 (Llama2 7B) 的 3 倍。请注意,这里显示的性能或性价比的差异是模型架构、超参数、底层加速器和训练软件等因素综合作用的结果;性能的提升不能仅归因于其中某一个因素。
Gemma 推理性价比
LLM 推理通常受内存限制,而训练可受益于大规模并行处理能力。推理包括两个阶段,每个阶段都具有不同的计算特性:预填充和解码。预填充阶段可以在计算受限的情况下运行(如果词元数量大于峰值 FLOP/HBM 带宽),而解码阶段是自回归的,除非进行高效批处理,否则往往会受到内存限制。由于我们在解码阶段一次只处理一个词元,批次大小往往需要很大,才能逃离受限于内存的区域。因此,仅仅增加整体批次大小(对于预填充和解码)可能不是最佳选择。由于吞吐量和延迟,以及前缀和解码长度之间的相互作用,我们将输入(预填充)和输出(解码)数据分开处理,下面重点讨论输出词元。
接下来,为了描述我们的观察结果,我们使用单位成本的吞吐量作为指标,因为它代表了模型服务器每秒可以针对用户的所有请求生成的输出词元数量。这是图表的 Y 轴,以百万输出词元为单位进行衡量。对于 Cloud TPU v5e,此数字还需要除以特定地区的 Compute Engine CUD 定价。
利用 Cloud TPU v5e 上的 JetStream 提高 TPU 推理的成本效益
推理性能难以衡量,因为吞吐量、成本和延迟可能受到多种因素的影响,例如模型大小、加速器类型、模型架构类型以及所使用的精度格式等。因此,我们使用成本效益(每百万个词元的成本)作为指标,对比基准的 TPU 推理堆栈,衡量 JetStream 的性能。我们发现,所用 JetStream 堆栈经过优化的 TPU 推理堆栈的成本效益是基准 TPU 推理堆栈的 3 倍,具体如下图所示(指标越低,表示成本效益越高)。
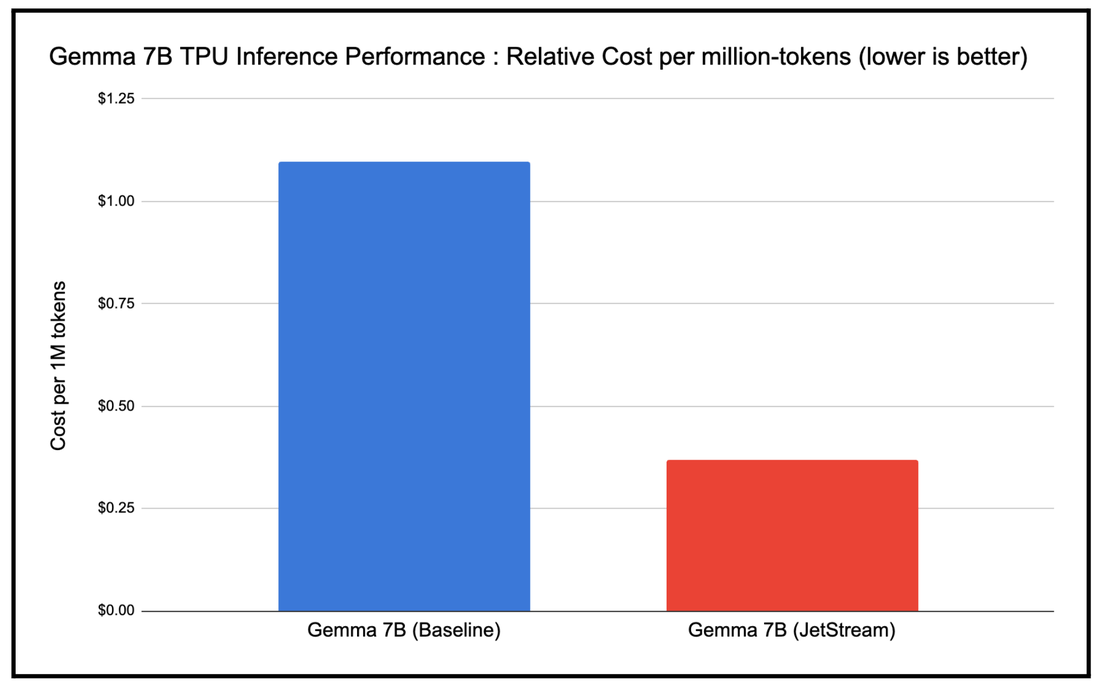
JetStream 每百万个词元的成本与基准 TPU 推理堆栈的对比情况。Google 内部数据。在 TPU v5e-8 上使用 Gemma 7B (MaxText) 进行衡量。输入长度为 1,024,输出长度为 1,024,适用于特定的请求速率和批次大小。连续批量处理,适用于权重、激活、KV 缓存的 int8 量化。截至 2024 年 4 月的数据。
通过 JetStream TPU 推理大规模应用单位成本吞吐量较高的 Gemma 7B
我们还想观察使用 JetStream 堆栈大规模应用 Gemma 7B 的性能,并将其与基准 TPU 推理堆栈进行比较。作为本次实验的一部分,我们改变了发送到这些 TPU 推理堆栈的请求速率(从每秒 1 个请求到 256 个请求不等),然后衡量了使用长度可变的输入和输出词元应用 Gemma 7B 的单位成本吞吐量。我们观察到一个一致的现象,即通过 JetStream 应用 Gemma 7B 的单位成本吞吐量高于基准,即使是在请求速率较高的情况下也是如此。
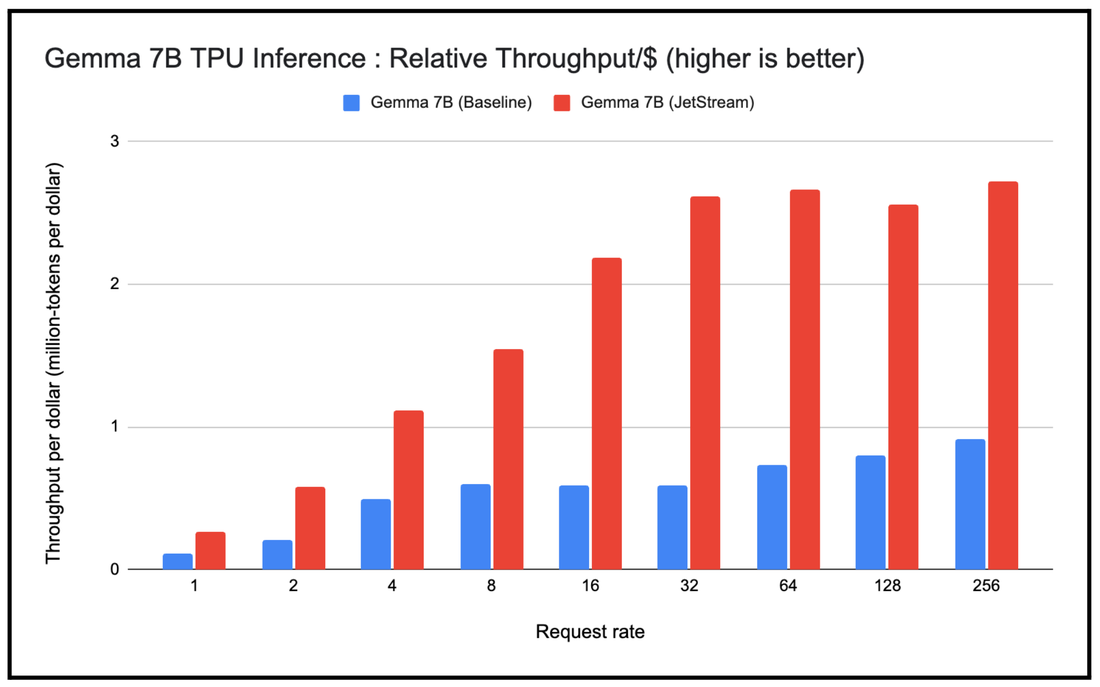
JetStream 单位成本吞吐量(每美元 100 万个词元)与基准 TPU 推理堆栈的对比情况。Google 内部数据。在 TPU v5e-8 上使用 Gemma 7B (MaxText) 进行衡量。输入长度 1,024,输出长度 1,024,请求速率从 1 到 256 不等。连续批量处理,适用于权重、激活、KV 缓存的 int8 量化。截至 2024 年 4 月的数据。
衡量单位成本吞吐量和每百万词元的成本
我们使用 Google Kubernetes Engine (GKE) 中的 JetStream 容器编排了实验。输入数据集中包含长度可变的输入和输出,因此可以模拟真实世界中语言模型的输入流量。为了生成图表,我们使用 JetStream 部署了 Gemma 模型,并逐渐增加了每秒向模型端点发送的请求数量。提高请求速率最初会增加批次大小、吞吐量以及每个令牌的延迟时间。然而,一旦批次大小达到临界值,后续请求就会排入队列等待处理,并且根据生成的输出词元数量,吞吐量会趋于稳定。
我们了解,上述基准测试对提示长度分布、采样和批处理优化很敏感,并且可以利用高性能注意力内核的变体及其他调整进一步改进。如果您想试用基准测试,可以采用 GKE 上的 AI 基准框架,在 GKE 上针对 AI 工作负载运行自动化基准测试。
Google Cloud 上的高性能 LLM 推理
为了大规模应用具有成本效益的 LLM,Google Cloud 提供了多种方案,供用户根据自己的编排、框架、服务层和加速器偏好设置进行选择。其中一种方案是将 GKE 作为编排层,支持 Cloud TPU 和 GPU 进行大规模模型推理。此外,每个加速器都提供了一系列服务层选项,包括 JetStream(JAX、PyTorch、MaxText)、Hugging Face TGI、TensorRT-LLM 和 vLLM。
摘要
无论您是选择 JAX 或 PyTorch 作为框架、选择通过 GKE 编排实现自行管理的灵活性,还是选择全托管式统一 AI 平台 (Vertex AI),Google Cloud 都会提供 AI 优化型基础架构,让您可以使用 Cloud GPU 或 TPU 轻松地在生产环境中大规模运行 Gemma。Google Cloud 为 Gemma 模型(或任何其他开源或自定义的大语言模型)提供了一组全面的高性能且经济实惠的训练、微调和服务选项。
根据使用 Cloud TPU v5e 和 v5p 的 Gemma 模型的训练性能,我们发现,使用 Gemma 参考实现进行 MaxText 训练的性价比高达基准的 3 倍。我们还发现,在 Cloud TPU 上使用 JetStream 进行推理的推理效率高达基准的 3 倍。无论您对在 Cloud GPU 上运行推理感兴趣,还是对在 Cloud TPU 上运行推理感兴趣,我们都针对 Gemma 模型提供了高度优化的服务实现。
要开始使用此模型,请访问 Gemma 文档,简要了解 Gemma 模型、模型访问权限、Gemma 的设备端变体以及所有相关资源。您也可以查看 Gemma 技术报告,详细了解其模型、架构、评估和安全基准。最后,请访问与 GKE 上的 Gemma 相关的文档,获取易于理解的操作说明,轻松开展实验。我们迫不及待地想要看到您使用 Gemma 构建出的作品!
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们