首页 > 资源 > 文章详情
开始在 GKE 上使用 AI 笔记本和 Jupyterhub
最近,分布式计算密集型机器学习应用出现增长,促使数据科学家和机器学习从业者寻找简单的方法来设计原型和开发自己的机器学习模型。通过在 Google Kubernetes Engine (GKE) 上运行 Jupyter 笔记本和 JupyterHub 提供了一种解决方案,这种方案自带安全性和可伸缩性作为平台的核心要素。
GKE 是一种托管式容器编排服务,提供了一个灵活的可伸缩平台来部署和管理容器化应用。GKE 将底层基础设施抽象化,让您可以轻松部署和管理复杂的部署。
Jupyterhub 是一款功能强大、基于多租户服务器的 Web 应用,支持用户与 Jupyter 笔记本交互并在上面进行协作。用户可以创建带有自定义映像和计算资源的自定义计算环境,并在其中运行自己的笔记本。“Zero to Jupyterhub for Kubernetes”(z2jh) 是一个 Helm Chart,可用于在 Kubernetes 上安装 Jupyterhub,该 Chart 针对复杂的用户场景提供了多种配置。
我们非常高兴地宣布推出了一个解决方案模板,该模板将帮助您顺利地开始在 GKE 上使用 Jupyterhub。使用 GKE 模板可以大大简化 z2jh 的使用,模板中提供预先配置的 GKE 集群、Jupyterhub 配置和自定义功能,让您可以快速、简便地设置 Jupyterhub。此外,我们还添加了身份验证和持久化存储等功能,并降低了模型原型设计和实验的复杂性。在本博文中,我们将讨论解决方案模板、在 GKE 上运行 Jupyterhub 的体验、在 GKE 上运行的独特性以及自定义身份验证和持久化存储等功能。
在 GKE 上运行 Jupyterhub 的体验
如果在 GKE 上运行 Zero to Jupyterhub,可以为机器学习应用提供一个强大的平台,但安装过程比较复杂。为了尽量让机器学习从业者能够顺畅使用,我们的解决方案模板将基础设施设置抽象化,并解决了常见的企业平台难题(包括身份验证和安全性,以及笔记本的持久化存储问题)。
安全性和身份验证
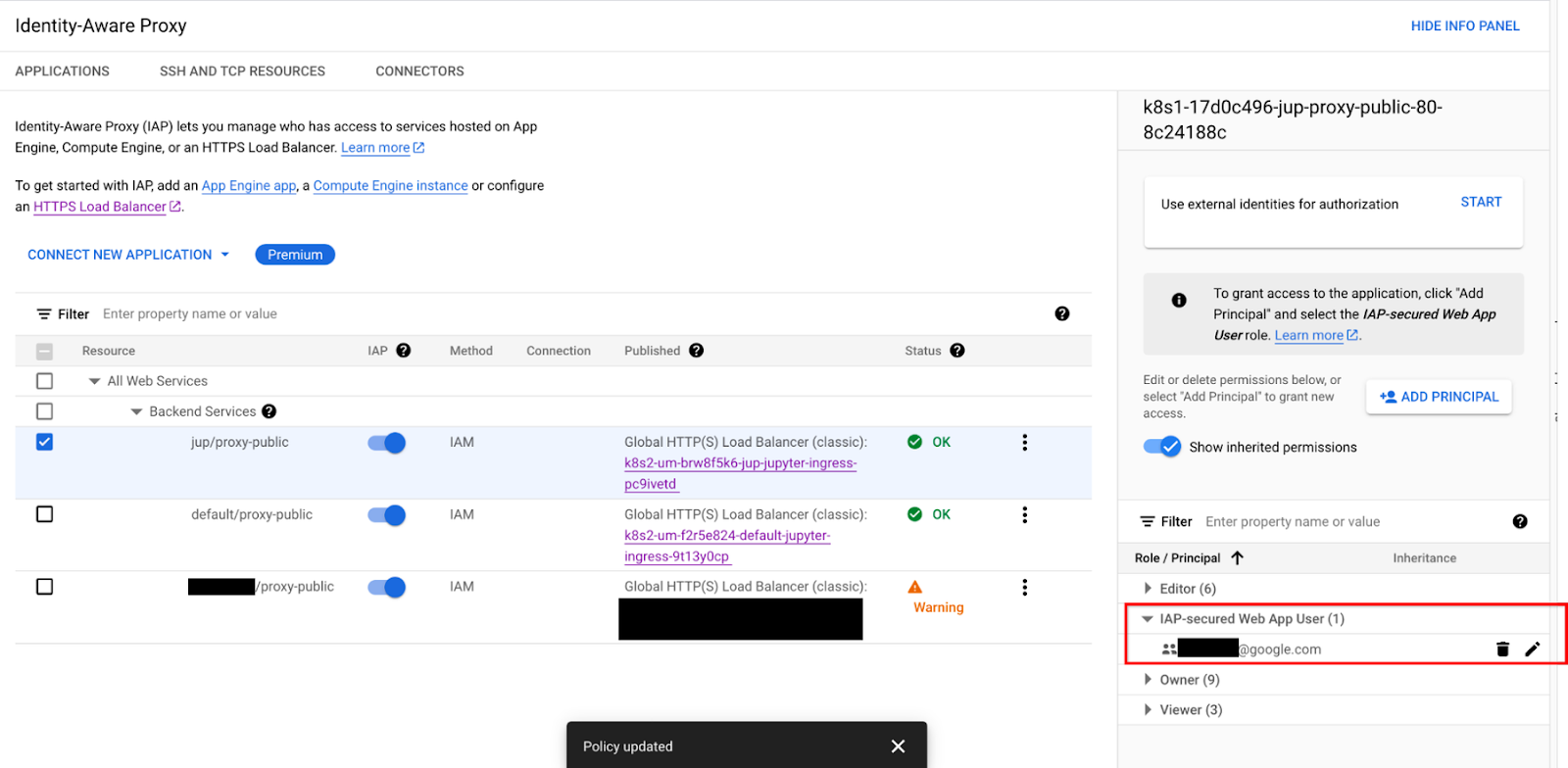
在处理敏感数据时,向笔记本授予正确的访问权限尤其困难。默认情况下,Jupyterhub 会公开一个公共端点,任何人都可以访问。应锁定此端点,以防止意外访问。我们的解决方案利用 Identity-Aware Proxy (IAP) 来控制对该公共端点的访问。IAP 会为通过 HTTPS 访问的 Jupyterhub 应用创建一个中央授权层,同时使用应用级访问权限模型,并为笔记本启用基于 IAM 的访问权限控制,从而使用户的数据更加安全。为 Jupyterhub 添加身份验证可确保用户有效性和笔记本安全性。
默认情况下,模板会通过 Google Cloud IAP 保留一个 IP 地址。平台管理员也可以提供一个域名来托管他们的 JupyterHub 端点,该端点受 IAP 保护。配置好 IAP 后,平台管理员必须更新服务许可名单,为用户授予“IAP-secure Web App User”角色。您可以查看下图,也可以根据此处的说明,了解如何允许访问部署的 JupyterHub:
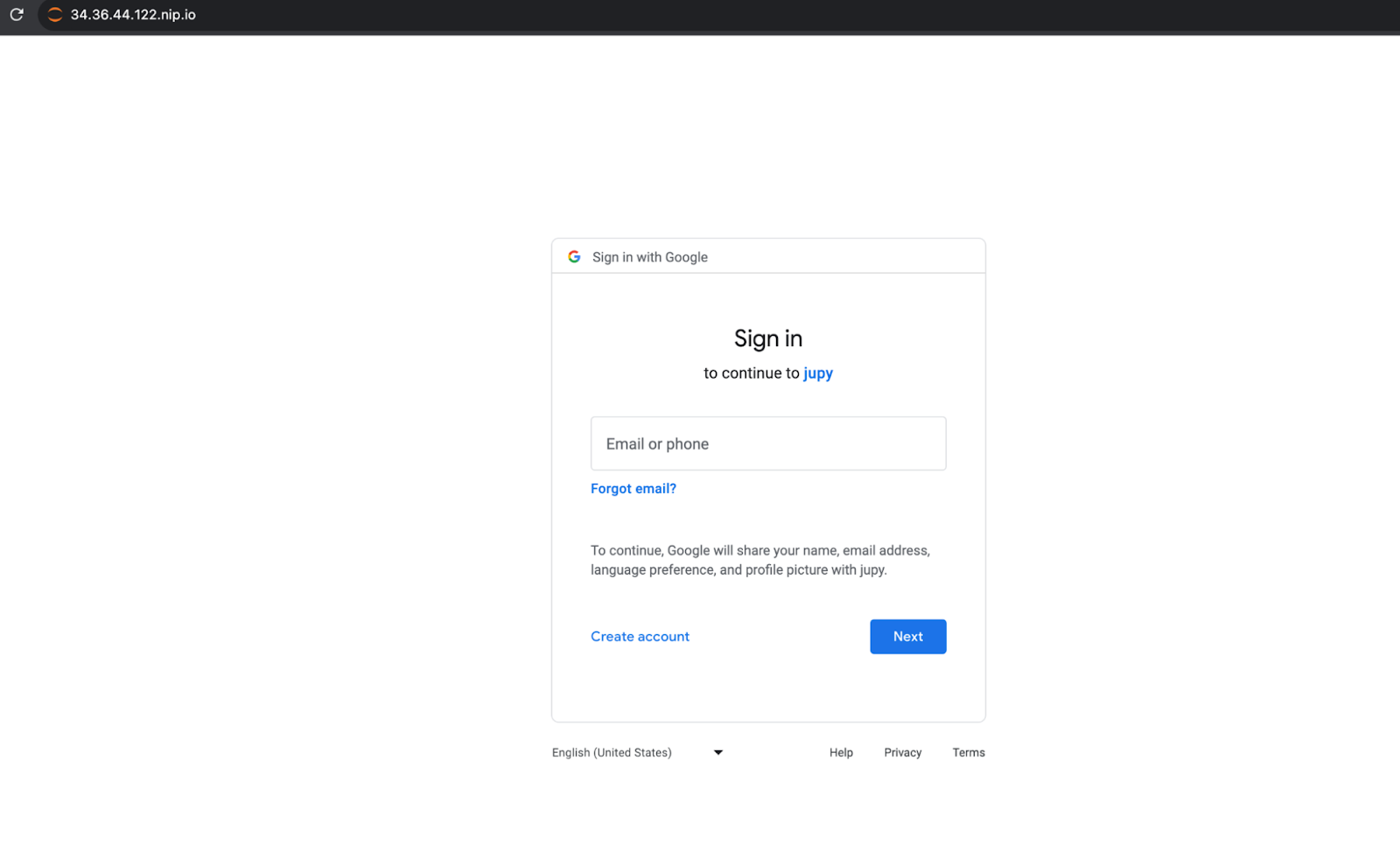
现在,当用户访问受 IAP 保护的 Jupyterhub 端点时,他们会看到 Google 登录界面(如下所示),提示他们使用 Google 身份登录。
持久化存储
在 GKE 上运行 Jupyterhub 并不会得到开箱即用的持久化存储解决方案,因此笔记本会在集群被删除时丢失。为了保留笔记本数据,我们的模板提供了与 Google 存储解决方案(如 Filestore、GCSFuse 和 Compute Engine Persistent Disk)集成的选项。每种解决方案都提供了不同的功能,适用于不同的应用场景:
Filestore - 支持动态预配和标准 POSIX。虽然标准层的持久化卷最小大小只有 1 Ti,但它们支持多共享,能够降低成本。
GCSFuse - 使用 Cloud Storage 存储桶作为持久化卷,但需要手动创建存储桶,即平台工程师必须为每位用户预配存储桶。可通过 Google Cloud 控制台中的界面支持管理 Cloud Storage,可通过 IAM 配置访问权限控制。
Compute Engine Persistent Disk - 支持动态预置,可自动扩缩,同时支持不同的磁盘类型。
如需详细了解存储解决方案,请参阅本指南。
解决方案概览
解决方案模板使用 Terraform 和 Helm Chart 来预配 JupyterHub。请按照自述文件中的分步说明开始操作。解决方案中包含两组资源:平台级资源和 Jupyterhub 级资源。
系统管理员应为每个开发环境部署一次平台级资源。这包括所有用户共享的通用基础设施和 Google Cloud 服务集成。系统管理员也可以重复使用已部署的开发环境。
GKE 集群和节点池 - 此模块在 main.tf 文件中进行配置,可部署一个带有 GPU 节点池的 GKE 集群。GKE 还提供其他 GPU 和机器类型。
Kubernetes 系统命名空间和服务账号,以及必要的 IAM 政策绑定。
当系统管理员在集群上安装 JupyterHub 时,系统会创建以下资源。系统管理员必须重新安装,才能应用对 JupyterHub 配置所做的任何更改(即此处所列的更改)。
JupyterHub z2jh 服务器 - 为用户启动 Jupyter 笔记本环境。
与 IAP 相关的 K8s 部署 - 包括 Ingress、后端配置以及用于将 Google Cloud IAP 和 JupyterHub 集成的托管式证书。
Filestore、GCSFuse 或 Persistent Disk 还会创建存储卷,具体取决于用户的选择。
可自定义的用户配置文件/资源
GKE 灵活的容器自定义和节点池配置与 Jupyter 中笔记本配置文件这一概念相得益彰。Jupyterhub 配置提供可自定义数量的预设配置文件,其中包含预先确定的 Jupyter 笔记本映像、内存、CPU、GPU 等。通过使用配置文件,工程师可以利用 GPU 和 TPU 等 GKE 基础设施来运行他们的笔记本。
搭配使用,相得益彰:Jupyter 和 GKE
搭配使用 Jupyter 和 GKE,不失为一种简单而强大的解决方案,可以构建、运行和管理 AI 工作负载。Jupyterhub 的易用性使其成为机器学习模型和数据探索的热门选择。有了 GKE,Jupyterhub 的可伸缩性和可靠性进一步提高,因此变得更为强大。
您还可以点击此处,了解如何使用 Ray 运行 Jupyterhub。
如果您对于如何通过 GKE 使用 Jupyterhub 有任何疑问,请在我们的 GitHub 上提交问题。如需详细了解如何使用 GKE 构建 AI 平台,请参阅我们的用户指南。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们