首页 > 资源 > 文章详情
使用 Vertex AI 自动建立公共网站索引以实现高效语义搜索
引言
如果您希望改变与非结构化数据交互的方式,那么您找对地方了!在本篇文章中,我们将带您了解生成式 AI 中那些令人兴奋的领域,尤其是 Vector Search 和大语言模型 (LLM) 等工具是如何彻底改变搜索功能的。
您将会了解向量搜索的强大功能,此外,您还可以探索快速获取非结构化数据(例如网页)的技术,从而有效增强您的搜索与聊天系统。
查询公共页面的典型对话式搜索解决方案包括以下步骤:
1. 抓取并加载网页内容:提取并整理网页内容以便进一步处理。
2. 创建文档块和向量嵌入:将网页内容划分为更小的片段,并生成每个块的向量表示。
3. 将文档块和嵌入存储在安全位置:安全地存储文本块和向量嵌入,以实现高效检索。
4. 构建向量搜索索引来存储嵌入以供日后查询:构建向量搜索索引,根据相似性高效搜索和检索向量嵌入。
5. 持续使用新的网页内容更新向量搜索索引:定期用新的网页内容更新索引以保持相关性。
6. 在向量搜索索引上执行搜索查询,检索相关网页内容:利用向量搜索索引来识别和检索相关网页内容,以响应搜索查询。
随着时间的推移,维护数据摄取过程可能会令人畏惧,尤其在处理数千个网页时。
但是别担心,我们会为你提供支持。
我们的解决方案
我们简化了数据摄取的流程,让您可以更轻松地部署对话式搜索解决方案,从指定网页中获取见解。我们的解决方案利用了多种 Google Cloud 产品组合,这些产品包括 Vertex AI Vector Search、Vertex AI 文本嵌入模型、 Cloud Storage、 Cloud Run 以及 Cloud Logging。
优势:
易于部署:指导步骤确保无缝集成到您的 Google Cloud 项目中。
灵活配置:自定义项目、区域、索引前缀、索引和端点名称以满足您的需求。
实时监控:Cloud Logging 提供对数据摄取管道的全面可见性。
可扩展存储:Cloud Storage 可安全地存储文本块和嵌入内容,以实现高效检索。
参考架构
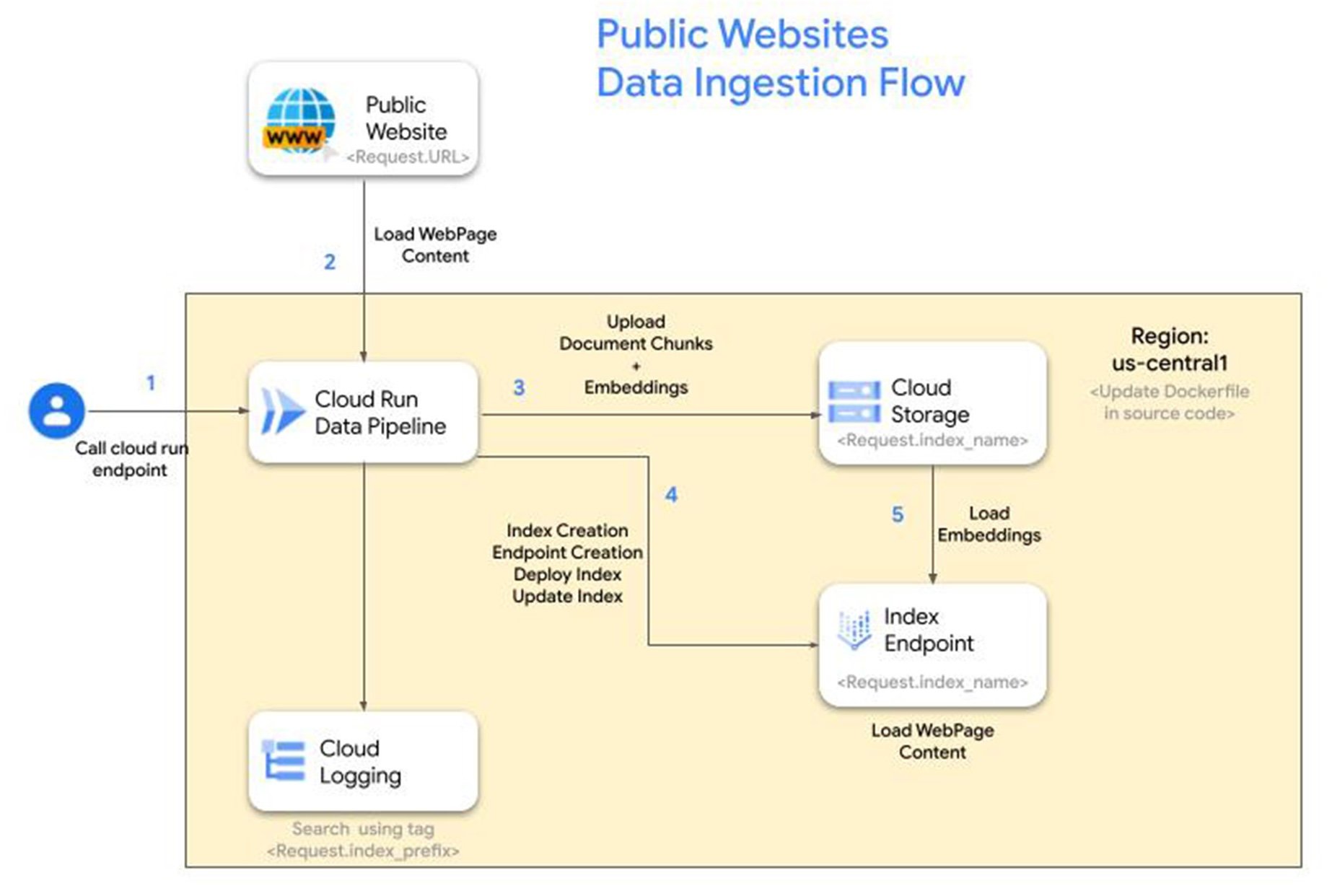
步骤
1. 启用API
使用 Google Cloud 控制台或通过下面的 gcloud 命令来启用以下 API
# Authenticate to your GCP project gcloud auth login |
# Enable following services # Vertex AI gcloud services enable aiplatform.googleapis.com --async # Cloud Run gcloud services enable run.googleapis.com # Cloud Logging gcloud logging enable # Resource Manager gcloud services enable cloudresourcemanager.googleapis.com # Artifact Registry gcloud services enable artifactregistry.googleapis.com # Storage gcloud services enable storage.googleapis.com |
2. 克隆存储库
git clone https://github.com/IvanERufino/public-website-vector-search |
在此存储库下,您将找到一个使用 fastapi 框架以 python 编写的应用程序,该应用程序公开了一个 REST 端点,该端点将负责介绍中详述的步骤。有关该应用程序的更多信息,请访问其 README.md 文件。
3. 在 DockerFile 中设置项目和区域
下载 github 存储库后,在您选择的任何受支持的文本编辑器中打开它。编辑 Dockerfile 并更新您偏好的 REGION 和 PROJECT_ID 值。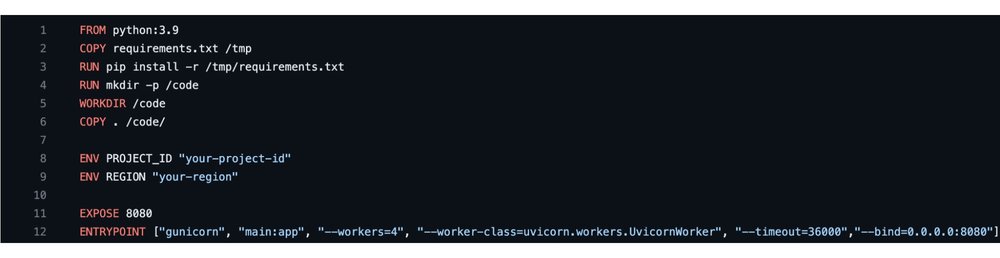
4. 构建映像并部署 Cloud Run 应用
gcloud builds submit --tag gcr.io/public-website-index-administrator/data_pipeline # Update the cloud run parameters for memory and instances if needed gcloud run deploy datapipeline --image gcr.io/public-website-index-administrator/data_pipeline --allow-unauthenticated --region=asia-east1 --memory=2Gi --min-instances=1 |
5. 调用端点创建索引
要开始将公共网站的内容加载到 GCP 上的索引端点中,请调用 http post 端点,并在正文中加入所需的配置参数。
Index_name => str :此参数将匹配您的索引和 indexEndpoint DisplayName 以及您的 GCS Bucket。
如果具有该名称的 GCS 存储桶不存在,则会创建一个新存储桶以及一个新索引。
如果 GCS 存储桶名称不是普遍唯一的,该方法将返回 400。
Url => str :要嵌入内容的 URL。 URL 必须以 sitemap.xml 结尾,否则方法将返回 400。
Prefix_name => str :它将作为云日志的标签,用以跟踪您的工作进度,并在您的 GCS 存储桶中创建一个文件夹,该文件夹用于存储嵌入内容。
下面是使用 CuRL 命令调用端点的示例。
curl -XPOST -H 'Content-Type: application/json' https://datapipeline.web.app/api/v1/public_url -d '{"index_name": "testing", "url": "https://cloud.google.com/bigquery/sitemap.xml", "prefix_name": "bigquery"}' |
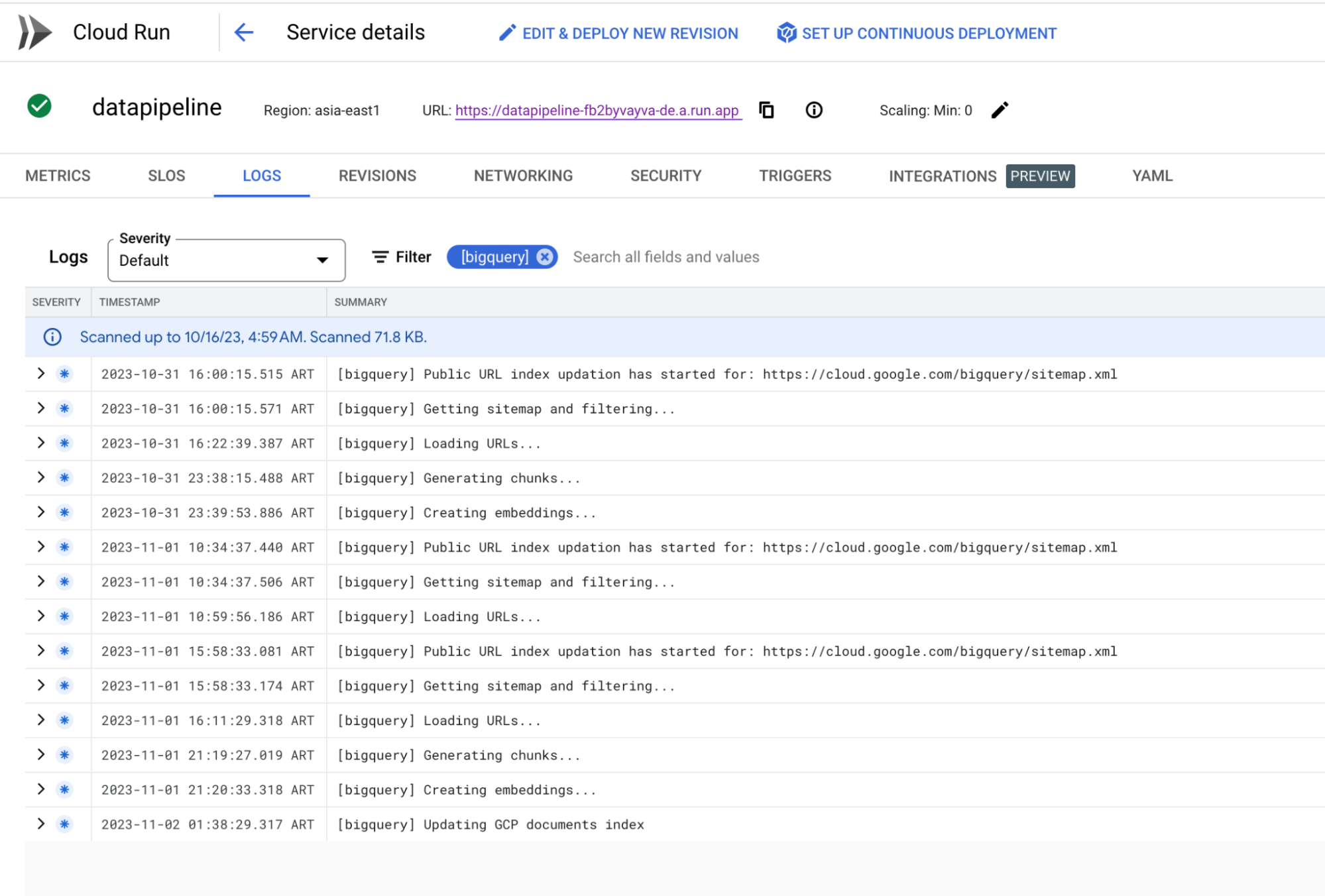
6. 检查 Cloud Logging 的进度
使用提供的 CuRL 命令启动索引创建后,您可以利用 Cloud Logging 并根据指定的前缀名称过滤日志来监控提取过程的进度。
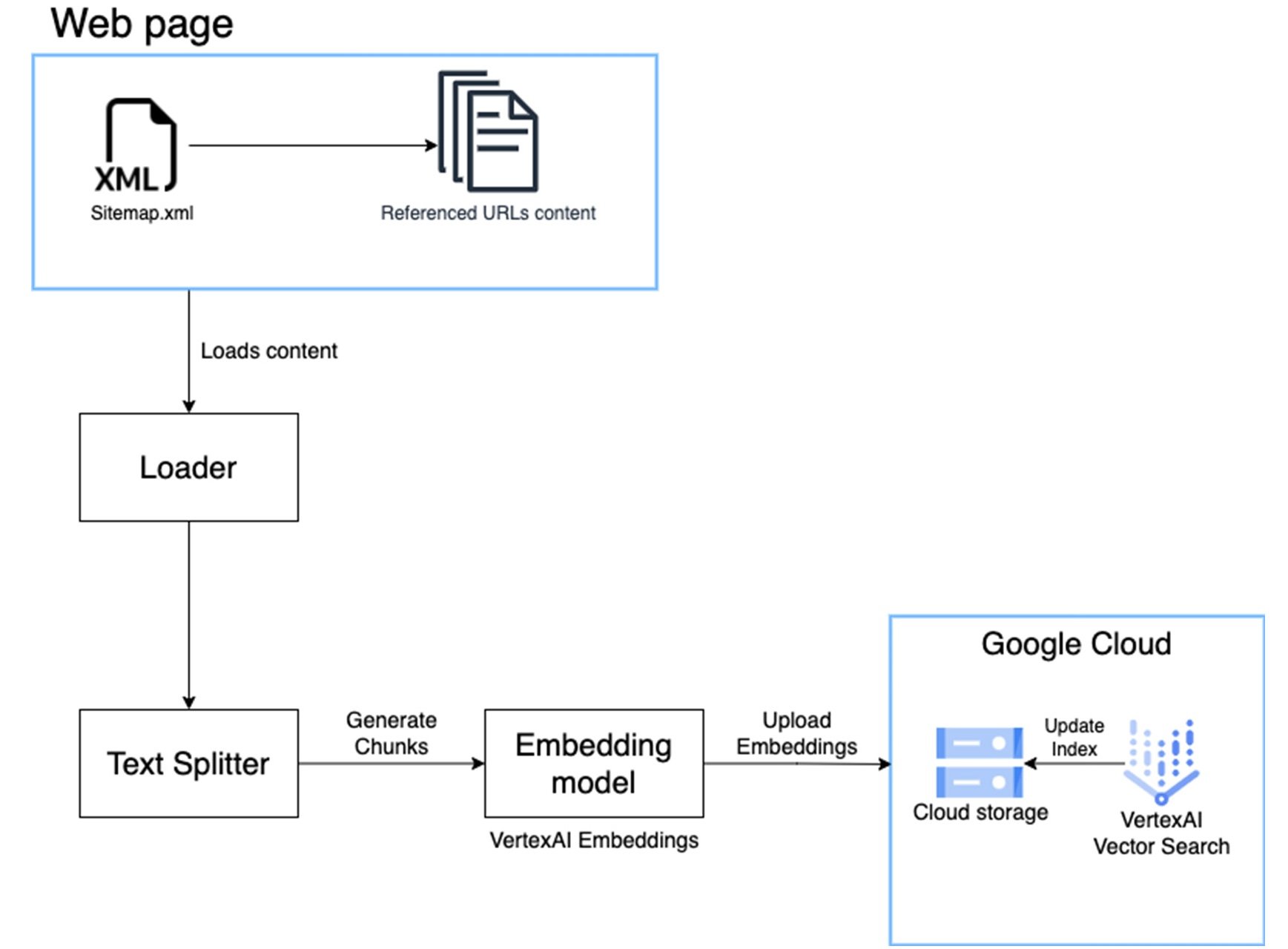
数据管道
数据管道的构建是为了简化提取、分块和嵌入创建的过程。这是管道的详细图。我们利用 LangChain 库来加载和分割 Web 数据。请参阅代码以了解更多详细信息。
7.查询索引以获得搜索结果
管道完成后,大约需要 3-4 小时(具体取决于摄取的网站),您将在 Google Cloud 项目中创建一个索引和一个索引端点,并且您可以在 Vertex AI 的Vector Search 选项下找到它们。
您现在可以使用向量搜索 Python 库的 match 函数查询索引端点。
有关如何查询现有向量搜索索引端点的参考代码如下。
from langchain.vectorstores.matching_engine import MatchingEngine from langchain.agents import Tool from langchain.embeddings import VertexAIEmbeddings from vertexai.preview.language_models import TextGenerationModel from google.cloud import aiplatform PROJECT_ID = '{YOUR-PROJECT-ID}' REGION = '{YOUR-REGION}' INDEX='{YOUR-INDEX-ID}' ENDPOINT='{YOUR-INDEX-ENDPOINT-ID}' DOCS_BUCKET='{YOUR-GCS-BUCKET}' embeddings = VertexAIEmbeddings() vector_store = MatchingEngine.from_components( index_id=INDEX, region=REGION, embedding=embeddings, project_id=PROJECT_ID, endpoint_id=ENDPOINT, gcs_bucket_name=DOCS_BUCKET ) def matching_engine_search(question): relevant_documentation=vector_store.similarity_search(question, k=8) context = "\\n".join([doc.page_content for doc in relevant_documentation])[:10000] return str(context) TEXT_GENERATION_MODEL='text-bison@001' question = "What is Apigee" matching_engine_response=matching_engine_search(question) prompt=f""" Follow exactly those 3 steps: 1. Read the context below and aggregate this data Context : {matching_engine_response} 2. Answer the question using only this context 3. Return the answer User Question: {question} If you don't have any context and are unsure of the answer, reply that you don't know about this topic. """ model = TextGenerationModel.from_pretrained(TEXT_GENERATION_MODEL) response = model.predict( prompt, temperature=0.2, top_k=40, top_p=.8, max_output_tokens=1024, ) print(f"Question: \\n{question}") print(f"Response: \\n{response.text}") |

总结
为了进一步提高解决方案的效率,您可以实行并行处理,以同时摄取大型网站或多个网站,从而大幅度减少整体数据消耗时间。
创建索引端点后,您现在可以开发一个生成式 AI 应用程序,该应用程序利用向量搜索索引来识别最接近的匹配项,并采用文本生成模型为我们的查询提供上下文和答案。如需了解有关这个令人兴奋的主题的更多信息,请查看此博客。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们