首页 > 资源 > 文章详情
使用 BigQuery 和 Gemini 模型创建营销活动
创建营销活动通常是一个复杂且耗时的过程。企业希望创建与客户需求高度相关且个性化的实时营销活动,来实现最大限度地提升销售额的目标。要达到这一目的,就需要具备实时数据分析、细分以及快速创建和执行活动的能力。实现这种高水准的敏捷性和个性化可以显著地帮助企业提升竞争优势。
一场成功的营销活动始终取决于创造力和数据驱动的洞察力。生成式 AI 目前正在放大这两个要素,生成式 AI 的进步有可能彻底改变营销活动的创建方式。通过利用实时数据,生成式 AI 可以大规模生成个性化内容,例如针对具体场景和可用图像的具有针对性的电子邮件、社交媒体广告或网站内容。这种全新的方式与当前的方法形成了鲜明对比,目前许多营销人员仍然受到人工处理流程的限制,并且可使用的创意资源也是十分有限的。
在当今内容充斥的环境下,虽然传统营销方式仍有一席之地,但海量的内容需求迫使我们采用更智能的方法。生成式 AI 可以帮助营销团队快速、高效地开展营销活动,并提供此前难以想象和到达的个性化水平,从而提升参与度、转化率和客户满意度。
在本篇文章中,我们将介绍数据和营销团队如何利用 BigQuery 中多模态大语言模型(LLM)的强大功能来创建和发起更有效、更智能的营销活动所涉及到的各个步骤。在本演示中,我们以 Data Beans 作为示例,这是一家虚构的技术公司,为咖啡销售商提供基于 BigQuery 构建的 SaaS 平台。 Data Beans 利用 BigQuery 与 Vertex AI 的集成来访问 Gemini Pro 1.0 和 Gemini Vision Pro 1.0 等 Google AI 模型,以加速创意工作流,同时大规模提供定制化的活动。
演示概览
该演示重点介绍了 Data Beans 启动营销流程的三个步骤,该流程利用 Gemini 模型为选定的咖啡菜单创建具有视觉吸引力的本地化营销活动。首先,我们使用 Gemini 模型集思广益并从所选菜单项生成出高质量图像,确保图像准确反映原始咖啡产品。接下来,我们使用这些相同的模型,以每个城市的母语为其制作定制化的营销文本。最后,该文本被集成到样式化的 HTML 电子邮件模板中,然后整个营销活动存储在 BigQuery 中以供分析和跟踪。

步骤 1 和 1.1:创建初始图片提示
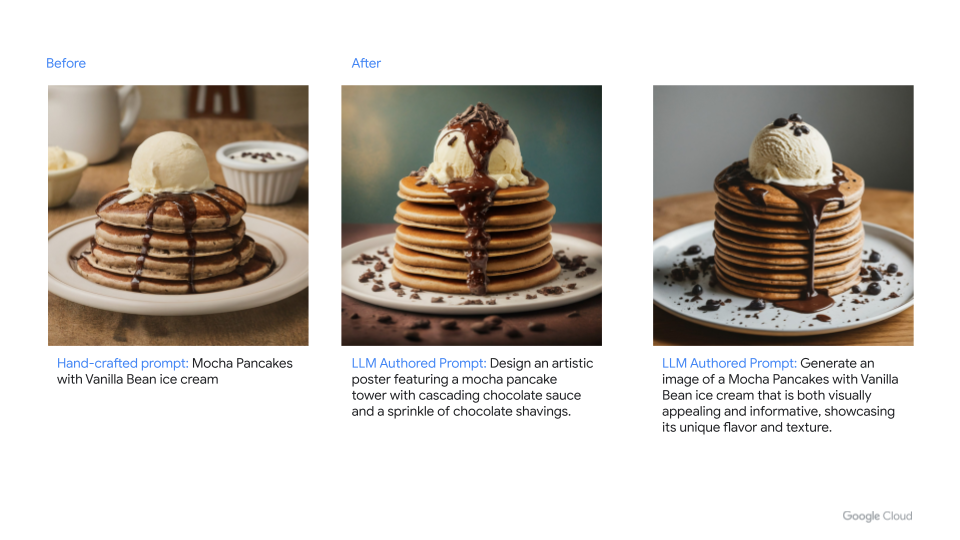
我们通过使用 Imagen 2 创建初始图像提示和关联图像来开始营销活动。这会生成一个相当基本的图像,可能不完全相关,因为我们在此阶段尚未向提示提供所有必要的信息。
picture_description = "Mocha Pancakes with Vanilla Bean ice cream" llm_human_image_prompt = f"Create an image that contains a {picture_description} that I can use for a marketing campaign." human_prompt_filename = ImageGen(llm_human_image_prompt) img = Image.open(human_prompt_filename) llm_human_image_json = { "gcs_storage_bucket" : gcs_storage_bucket, "gcs_storage_path" : gcs_storage_path, "llm_image_filename" : human_prompt_filename } img.thumbnail([500,500]) IPython.display.display(img) |
步骤 1.2:优化提示词
创建初始图像后,我们现在专注于通过创建更好的提示来改善我们的图像。为此,我们使用 Gemini Pro 1.0 来改进我们早期的 Imagen 2 提示。
example_return_json = '[ { "prompt" : "response 1" }, { "prompt" : "response 2" }, { "prompt" : "A prompt for good LLMs" }, { "prompt" : "Generate an image that is awesome" }]' llm_generated_image_prompt=f"""For the below prompt, rewrite it in 10 different ways so I get the most creative images to be generated. Try creative thinking, generate innovative and out-of-the-box ideas to solve the problem. Explore unconventional solutions, thinking beyond traditional boundaries, and encouraging imagination and originality. Embrace unconventional ideas and mutate the prompt in a way that surprises and inspires unique variations. Think outside the box and develop a mutator prompt that encourages unconventional approaches and fresh perspectives. Return the results in JSON with no special characters or formatting. Limit each json result to 256 characters. Example Return Data: {example_return_json} Prompt: "Create a picture of a {picture_description} to be used for a marketing campaign." """ llm_success = False temperature=.8 while llm_success == False: try: llm_response = GeminiProLLM(llm_generated_image_prompt, temperature=temperature, topP=.8, topK = 40) llm_success = True except: # Reduce the temperature for more accurate generation temperature = temperature - .05 print("Regenerating...") print(llm_response) |
步骤 1.3:根据大语言模型生成的提示生成图像
现在我们有了增强的提示,我们将使用它们来生成图像。实际上,我们正在使用大语言模型生成提示,然后再输入到大语言模型来生成图像。
llm_json = json.loads(llm_response) # Add an image to the generation that will not contain any food items. We will test this later. llm_json.append({'prompt' : 'Draw a coffee truck with disco lights.'}) image_files = [] for item in llm_json: print(item["prompt"]) try: image_file = ImageGen(item["prompt"]) image_files.append ({ "llm_prompt" : item["prompt"], "gcs_storage_bucket" : gcs_storage_bucket, "gcs_storage_path" : gcs_storage_path, "llm_image_filename" : image_file, "llm_validated_by_llm" : False }) except: print("Image failed to generate.") |
步骤 2-3:验证图像并执行质量控制
我们现在将使用大语言模型来验证生成的输出。实际上,我们要求大语言模型检查每个生成的图像是否包含我们要求的食物。例如,图像是否包含提示中的咖啡或食品?这不仅可以帮助我们验证是否存在抽象的东西,还可以帮助我们验证图像的质量。此外,我们还可以检查图像是否具有视觉吸引力——这是营销活动的必备条件。
example_return_json = '{ "response" : true, "explanation" : "Reason why..." }' llm_validated_image_json = [] number_of_valid_images = 0 llm_validated_image_prompt = f"""Is attached image a picture of "{picture_description}"? Respond with a boolean of true or false and place in the "response" field. Explain your reasoning for each image and place in the "explanation" field. Return the results in JSON with no special characters or formatting. Place the results in the following JSON structure: {example_return_json} """ for item in image_files: print(f"LLM Prompt : {item['llm_prompt']}") print(f"LLM Filename : {item['llm_image_filename']}") imageBase64 = convert_png_to_base64(item['llm_image_filename']) llm_success = False temperature = .4 while llm_success == False: try: llm_response = GeminiProVisionLLM(llm_validated_image_prompt, imageBase64, temperature=temperature) print(f"llm_response : {llm_response}") llm_json = json.loads(llm_response) llm_success = True except: # Reduce the temperature for more accurate generation temperature = temperature - .05 print("Regenerating...") # Mark this item as useable if llm_json["response"] == True: item["llm_validated_by_llm"] = True number_of_valid_images = number_of_valid_images + 1 item["llm_validated_by_llm_explanation"] = llm_json["explanation"] llm_validated_image_json.append( { "llm_prompt" : item["llm_prompt"], "gcs_storage_bucket" : item["gcs_storage_bucket"], "gcs_storage_path" : item["gcs_storage_path"], "llm_image_filename" : item["llm_image_filename"], "llm_validated_by_llm" : item["llm_validated_by_llm"], "llm_validated_by_llm_explanation" : item["llm_validated_by_llm_explanation"] }) |
步骤 4:对图像进行排名
现在我们已经完成了验证和质量控制,我们可以选择最适合我们需求的图像。通过巧妙的提示,我们可以再次使用 Gemini Pro 1.0 为我们生成的数千张图像执行此操作。为此,我们要求 Gemini 根据每个图像的视觉效果、信息清晰度以及与我们的 Data Beans 品牌的相关性对每个图像进行排名。然后我们将选择得分最高的项目。
image_prompt = [] for item in image_files: if item["llm_validated_by_llm"] == True: print(f"Adding image {item['llm_image_filename']} to taste test.") imageBase64 = convert_png_to_base64(item['llm_image_filename']) new_item = { "llm_image_filename" : item['llm_image_filename'], "llm_image_base64" : f"{imageBase64}" } image_prompt.append(new_item) example_return_json='[ {"image_name" : "name", "rating" : 10, "explanation": ""}]' llm_taste_test_image_prompt=f"""You are going to be presented with {number_of_valid_images}. You must critique each image and assign it a score from 1 to 100. You should compare the images to one another. You should evaluate each image multiple times. Score each image based upon the following: - Appetizing images should get a high rating. - Realistic images should get a high rating. - Thought provoking images should get a high rating. - Plastic looking images should get a low rating. - Abstract images should get a low rating. Think the rating through step by step for each image. Place the result of the scoring process in the "rating" field. Return the image name and place in the "image_name" field. Explain your reasoning and place in the "explanation" field in less than 20 words. Place the results in the following JSON structure: {example_return_json} """ llm_success = False temperature=1 while llm_success == False: try: llm_response = GeminiProVisionMultipleFileLLM(llm_taste_test_image_prompt, image_prompt, temperature = temperature) llm_success = True except: # Reduce the temperature for more accurate generation temperature = temperature - .05 print("Regenerating...") print(f"llm_response : {llm_response}") |
步骤 5:生成营销活动文案
现在我们已经选择了最佳图像,让我们生成最佳营销文案。我们将所有生成的数据存储在 BigQuery 中,因此我们生成 JSON 格式的文本。我们正在生成文本以纳入促销活动和其他相关项目。
example_return_json_1 = '{ "city" : "New York City", "subject" : "email subject" , "body" : "email body" }' example_return_json_2 = '{ "city" : "London", "subject" : "marketing subject" , "body" : "The body of the email message" }' imageBase64 = convert_png_to_base64(highest_rated_llm_image_filename) llm_marketing_campaign = [] # Loop for each city for city_index in range(0, 4): print(f"Processing city: {city_names[city_index]}") prompt=f"""You run a fleet of coffee trucks in {city_names[city_index]}. We need to craft a compelling email marketing campaign for the below image. Embrace unconventional ideas and thinking that surprises and inspires unique variations. We want to offer exclusive discounts or early access to drive sales. Look at the image and come up with a savory message. The image contains "{picture_description}". The marketing campaign should be personalized for {city_names[city_index]}. Do not mention the weather in the message. Write the response using the language "{city_languages[city_index]}". The campaign should be less than 1500 characters. The email message should be formatted in text, not HTML. Sign the email message "Sincerely, Data Beans". Mention that people can find the closest coffee truck location by using our mobile app. Return the results in JSON with no special characters or formatting. Double check for special characters especially for Japanese. Place the value of "{city_names[city_index]}" in the "city" field of the JSON response. Example Return Data: {example_return_json_1} {example_return_json_2} Image of items we want to sell: """ llm_success = False temperature = .8 while llm_success == False: try: llm_response = GeminiProVisionLLM(prompt, imageBase64, temperature=.8, topP=.9, topK = 40) llm_json = json.loads(llm_response) print(llm_response) llm_success = True except: # Reduce the temperature for more accurate generation temperature = temperature - .05 print("Regenerating...") llm_marketing_campaign.append(llm_json) llm_marketing_prompt.append(prompt) llm_marketing_prompt_text.append(llm_response) |
另外,请注意我们如何使用 Gemini Pro 1.0 将营销信息翻译为不同国家的语言。

步骤 6:创建 HTML 营销邮件
生成的项目显示为 Web 应用程序的一部分。为了简化分发,我们需要创建一个具有嵌入式格式的 HTML 电子邮件以及嵌入我们的图像。同样,我们使用 Gemini Pro 1.0 根据我们在前面步骤中创建的图像和文本,将营销文本创作为 HTML。
imageBase64 = convert_png_to_base64(highest_rated_llm_image_filename) for item in llm_marketing_campaign: print (f'City: {item["city"]}') print (f'Subject: {item["subject"]}') prompt=f"""Convert the below text into a well-structured HTML document. Refrain from using <h1>, <h2>, <h3>, and <h4> tags. Create inline styles. Make the styles fun, eye-catching and exciting. Use "Helvetica Neue" as the font. All text should be left aligned. Avoid fonts larger than 16 pixels. Do not change the language. Keep the text in the native language. Include the following image in the html: - The image is located at: https://REPLACE_ME - The image url should have a "width" of 500 and "height" of 500. Double check that you did not use any <h1>, <h2>, <h3>, or <h4> tags. Text: {item["body"]} """ llm_success = False temperature = .5 while llm_success == False: try: llm_response = GeminiProLLM(prompt, temperature=temperature, topP=.5, topK = 20) if llm_response.startswith("html"): llm_response = llm_response[4:] # incase the response is formatted like markdown # Replace the image with an inline image (this avoids a SignedURL or public access to GCS bucket) html_text = llm_response.replace("https://REPLACE_ME", f"data:image/png;base64, {imageBase64}") item["html"] = html_text #print (f'Html: {item["html"]}') filename= str(item["city"]).replace(" ","-") + ".html" with open(filename, "w", encoding='utf8') as f: f.write(item["html"]) print ("") llm_success = True llm_marketing_prompt_html.append(prompt) llm_marketing_prompt_html_text.append(html_text) except: # Reduce the temperature for more accurate generation temperature = temperature - .05 print("Regenerating...") |
总结与相关资源
将大语言模型融入到创意工作流程中的做法正在彻底改变创意领域。通过集思广益和生成大量内容,大语言模型可以为创作者的活动提供各种高质量的图像,加快自动本地化的文本生成速度,并分析大量数据。此外,AI 驱动的质量检查可确保生成的内容符合所需的标准。
虽然大语言模型的创造力有时会生成不相关的图像,但 Gemini Pro Vision 1.0 “taste test” 功能可让您选择最有吸引力的结果。此外,Gemini Pro Vision 1.0 对其决策过程提供了富有洞察力的解释。Gemini Pro 1.0 通过以本地语言生成内容来扩大受众参与度,并支持代码生成,并且无需了解 HTML。
要试验本演示中展示的功能,请参阅完整的 Colab Enterprise 笔记本源代码。 要了解有关这些新功能的更多信息,请查看此文档。您还可以使用本教程将 Google 一流的 AI 模型应用于您的数据、部署模型并实施 ML工作流,而无需从 BigQuery 移动数据。最后,查看此演示,了解如何直接从 BigQuery 构建端到端数据分析和 AI 应用程序,同时利用 Gemini 等高级模型的潜力。作为奖励,您将看到我们的幕后花絮,了解演示是如何制作的。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们