首页 > 资源 > 文章详情
使用 Google Cloud 数据库构建企业级生成式 AI 应用
大语言模型 (LLM)是在大量公开可用且主题广泛的数据上训练出来的,在许多方面都很强大,但仍有一些可以改进的地方。
由于训练数据庞大,频繁训练它们可能会耗费大量资源。因此,它们可能无法获得最新的信息。此外,由于它们是在可用数据的基础上进行训练的,因此它们并不知道公司防火墙后面的任何内容。询问大语言模型谁赢得了最新的体育比赛或您的健康保险保费是多少,它可能无法给出答案。这些限制对于一般的知识类问题来说可能没问题,但企业正在寻求利用大语言模型来创建生成式 AI 应用程序,这些应用程序需要提供高精度、能够访问实时信息并且可以支持复杂的对话体验。
目前有一种越来越流行的方法来解决这一问题,那就是利用一种名为检索增强生成(RAG)的技术来使大语言模型“落地”。这为企业构建新一代 AI 应用程序开辟了新的机会,因为这些应用程序可以通过新的或专有的数据来丰富大语言模型提示,以产出相关且准确的信息。这对于受敏感信息法规约束的公司和行业尤其重要。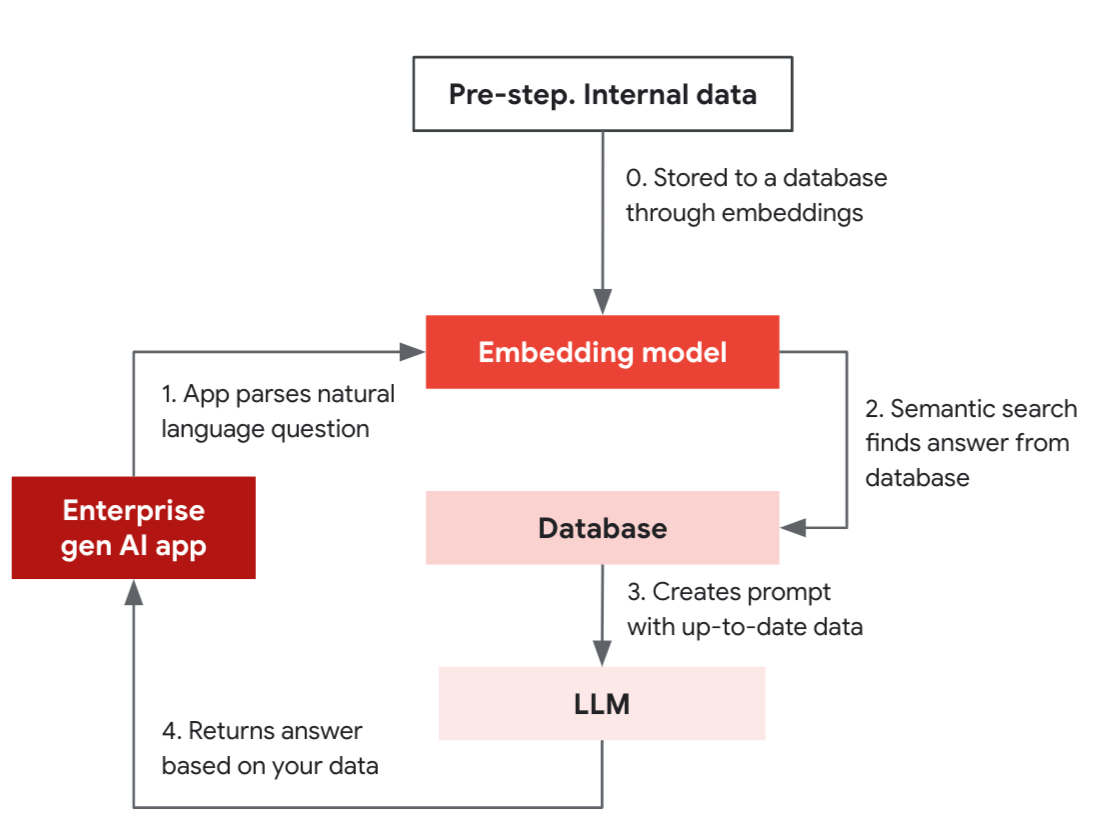
RAG 方法
让我们以客服聊天机器人为例来了解一下 RAG 的工作原理,该机器人能够回答各种问题,包括可用性、定价和退货政策。如果您向一位典型的大语言模型询问一个通用问题,例如“5 岁以下儿童流行的玩具有哪些?”它或许能够给出答案——但由于大语言模型不知道商店当前的库存情况,所以答案与购物者的需求可能并不相关。为了让客服聊天机器人使用最新的数据和策略来提供答案,RAG 方法可能被证明是有效的。
这个简化的 RAG 示例由一个准备步骤和四个正式步骤组成,详细介绍了应用程序如何利用支持向量索引数据库的相似性搜索功能来提供可靠的答案。
准备步骤:内部数据通过嵌入模型存储在数据库中。
正式步骤:
生成式 AI 应用程序使用嵌入模型将自然语言问题(“您是否有 具有特征 A、B、C 的 X 产品?”)转换为向量。
使用嵌入模型将问题转化为向量,并在数据库上进行语义搜索。
数据库返回数据,作为大语言模型提示的一部分。
大语言模型根据数据构建精准的答案。
大语言模型和数据库协同工作以提供实时结果。在初始设置中,您将通过嵌入模型将产品描述等内部数据作为向量存储到操作数据库中。这使您的应用程序根据您的数据进行搜索并提供新鲜、准确的结果。设置完成后,您的应用程序现在可以使用数据库中的相似性搜索来回答问题,然后结合大语言模型的提示来提供相关答案。
嵌入允许您使用近似近邻谓词根据相似性过滤数据。这些类型的查询可实现产品推荐等体验,让您可以搜索与他们之前交互过的产品相似的产品。因此,它们使大语言模型在用于构建提示时更加强大。这是因为大语言模型本身有输入大小限制并且没有状态概念,因此并不总是可以在提示中提供完整的上下文。因此,嵌入使我们能够在大型文本中进行搜索,例如数据库、文档和聊天记录等,从而能够模拟长期记忆并理解特定于业务的知识。
向量数据库
RAG 方法的一个关键组成部分是使用向量嵌入。Google Cloud 提供了一些存储它们的方式。 Vertex AI Vector Search 是一款专为大容量、低延迟地存储和检索向量而设计的工具。如果您熟悉 PostgreSQL,pgvector 扩展提供了一种简单的方法,可以在数据库中添加向量查询以支持生成式 AI 应用程序。 Cloud SQL 和 AlloyDB 支持 pgvector,在使用 IVFFlat 索引模式时,与标准 PostgreSQL 相比,AlloyDB AI 支持高达 4 倍的向量大小和高达 10 倍的性能提升。
构建企业级的生成式 AI 应用程序可能看起来很困难,但通过利用 LangChain 等开源兼容工具和 Google Cloud 的资源,您可以通过我们在本文中介绍的概念和工具轻松开始您的旅程。要了解有关 Cloud SQL和 AlloyDB中 pgvector的更多信息,请访问此博客。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们