首页 > 资源 > 文章详情
使用 Vertex AI 进行 RLHF 调整
基础模型是大型神经网络模型,可以通过极小的调整来适应各种任务,并在生成高质量文本、图像、语音、代码等方面表现出令人印象深刻的能力。企业正在利用基础模型来支持不同的生成式 AI 用例,例如生成创意博客文章或提升客户支持。
但对于高质量结果的看法各不相同。为了使基础模型能够更好地满足特定需求,企业和组织需要对其进行调整,使其能够做出适当的行为和响应。基于人类反馈的强化学习(RLHF)是一种流行的方法,通过这种方法,最初在通用文本数据语料库上训练的大语言模型 (LLM) 等基础模型可以与复杂的人类价值观保持一致。在企业用例的上下文中,RLHF 利用人类反馈来帮助模型生成响应,以满足特定的要求。
RLHF 是什么?
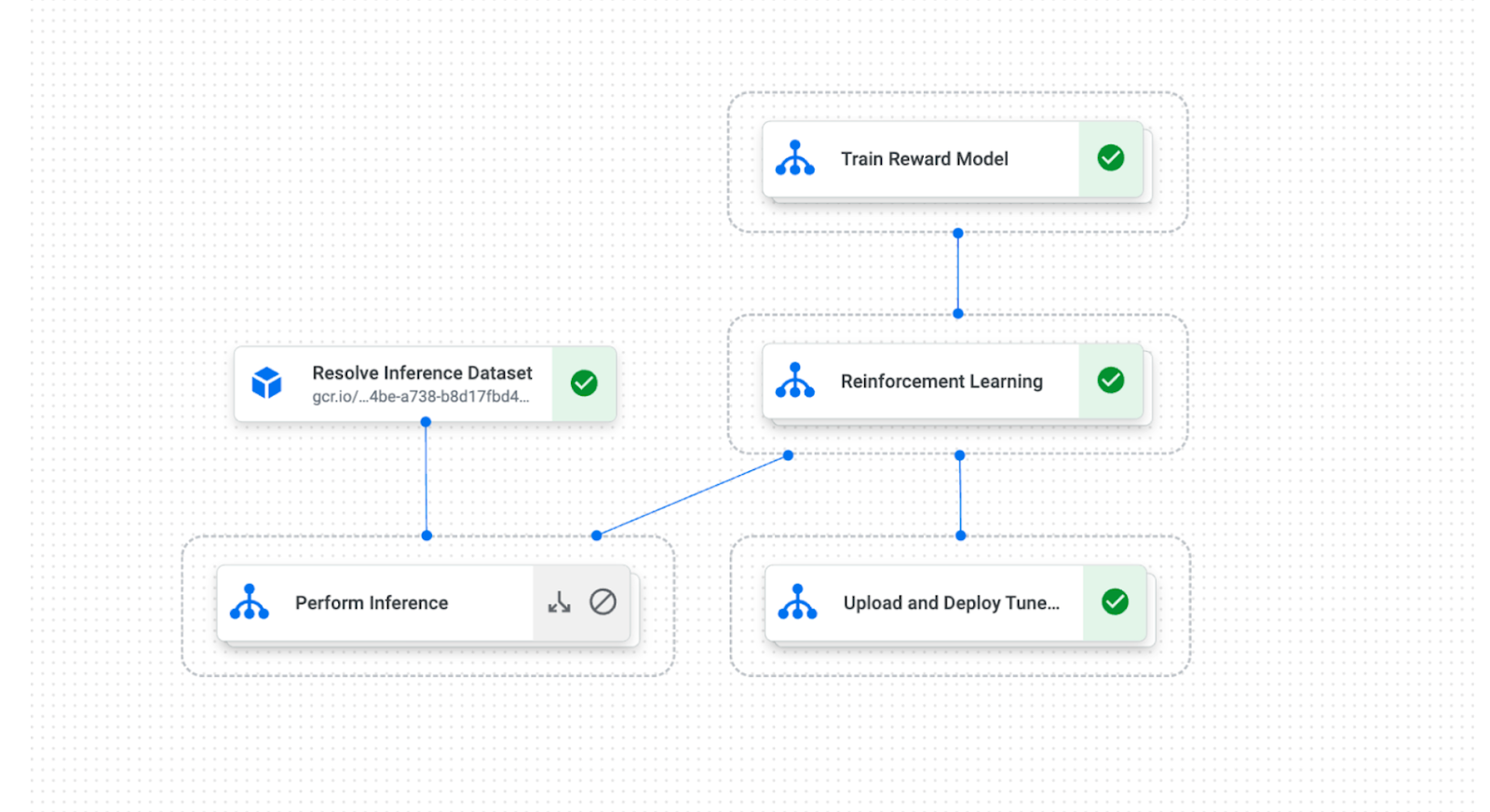
RLHF 调整包括两个阶段:奖励建模和强化学习。
1. 奖励建模
在进行奖励建模时,数据是以比较的形式收集的。首先,我们将相同的提示输入一个或多个大语言模型以创建多个响应。然后,我们要求人工评分员将这些回答从好到坏进行排名。我们在这些响应之间挑选出所有可能的配对,这样在每一对问答中,自然就会有一个响应比另一个响应更受欢迎。我们对许多提示都这样做,通过这样的方式创建了“人类偏好数据集”。
我们将奖励模型训练成一个评分函数,以便它对给定提示的响应程度进行评分。回想一下,对于每个提示,我们都有一个包含多个响应的排名列表。奖励模型的分数需要尽可能与排名一致。我们将其制定为损失函数,并对奖励模型进行训练,使其做出的奖励预测与实际排名一致。
2. 强化学习
一旦我们拥有了奖励模型,我们就可以对任意一对<提示,响应>的质量进行评分。在此步骤中,我们需要“提示数据集”,它仅包含提示信息(即未标记)。然后,我们从数据集中提取提示,使用大语言模型生成响应,并使用奖励模型对响应的质量进行评分。如果响应是高质量的,那么该响应中的所有标记(以提示为条件)都将被“强化”,即未来产生它们的概率会更高。通过这种方式,我们可以优化大语言模型来生成最大化奖励的响应。该算法称为强化学习(RL)。
RLHF 的调整需要编排这两个阶段,利用数据并行性和模型分区在多主机 TPU 或 GPU 上处理大规模分布式训练,并通过计算图编译优化高效吞吐量。密集的计算还需要一流的硬件加速器来实现快速训练。借助 Vertex AI,客户可以使用封装 RLHF 算法的 Vertex AI Pipeline 来实施 RLHF,以调整 PaLM 2、FLAN-T5 和 Llama 2 模型。这有助于将大语言模型与企业针对特定用例的细微偏好和价值观结合起来。

采用 Vertex AI 的最先进 RLHF
我们现在提供封装 RLHF 算法的 Vertex AI Pipeline 模板。RLHF 内置在 Vertex AI 上的 Generative AI Studio 中,使用户可以轻松利目前最新的 AI 技术以及企业安全功能,例如 VPC/SC。用户可以将 RLHF 与 Vertex AI MLOps 功能(例如模型仓库和模型监控)结合使用。 RLHF 与 Vertex AI 可以帮助企业和组织实现以下目标:
性能:提升大语言模型的性能,以更好地符合人们的偏好。
访问 Google 最先进的专有模型
利用 Cloud TPU 和 A100 GPU 等新型加速器来加快调整速度
安全性: RLHF 可以通过提供响应的负面样本来帮助大语言模型提升安全性。
Recruit Group
Recruit Group 是全球领先的人力资源技术和业务解决方案领域的公司,致力于改变工作世界。人力资源技术战略业务是该公司的业务支柱之一,其使命是为求职者匹配工作机会,并在全球范围内为整个求职过程提供工具。在集团内部,Recruit Co., Ltd. 主要在日本提供搜索平台、职业咨询和面试准备服务。业务目标是利用 AI 技术优化求职者和雇主之间的沟通,使人们更快、更简单地找到工作。
最近出现了许多基础模型;但在使用通用基础模型来解决一些特定任务时需要更加清晰。例如,完善求职者的简历时需要校对,并为他们提供全面的行业知识、工作类型、公司和招聘流程方面的建议。由于大语言模型的普遍性,基础模型很难提出改进简历的建议。这样的任务需要更好地根据人类偏好来调整模型进行输出,并能够控制输出的格式。
Recruit Co., Ltd. 一直在评估基础模型和一个通过 RLHF 调整的模型。这个实验的目的是探索模型在利用人力资源领域知识进行调整后,能否更好地完成简历写作这一文本生成任务。实验结果由人力资源专家进行评估。专家们会对生成的简历进行逐一检查,并确定简历是否符合生产水平质量标准的预期。成功指标是生成的简历中通过质量标准的百分比。
| 模型 | 数据大小 | 评分 |
| 基础模型(text-bison-001) | - | 70% |
| 监督调整(text-bison-001) | 提示数据集: 4,000 | 76% |
| RLHF (text-bison-001) | 提示数据集: 1,500 人类偏好数据集: 4,000 | 87% |
结果表明,使用客户数据进行 RLHF 调整可以提高模型性能,从而带来更好的结果。 Recruit Group 计划评估 AI 生成的内容与专家制作的内容之间的差异,以估算自动化的收益和成本。
下一步
要了解有关 RLHF 与 Vertex AI 的更多信息,请参阅文档,其中向您展示并提供了如何将 RLHF 与 Vertex AI 结合使用的资源。您还可以查看笔记本,以便开始使用 RLHF。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们