首页 > 资源 > 文章详情
迁移最佳实践
GCP DMS
GCP DMS 是基于数据库的整体(whole instance)迁移方案,实用原生(mysql native)的迁移方式对数据库进行迁移。
Pro vs Con
Pro
• 由于使用的是原生的迁移方式,所以对数据库的支持比较好,既可以迁移数据,也可以迁移 secondary index,stored procedure,function,trigger 等
• 支持一次性的全量 dump,也支持全量(full dump)加增量(cdc)的持续迁移
• 配置简单,方便使用
• 产品无需付费
Con
• 只能做整机的 1:1 迁移,不能做 database/table 级别的筛选,也不能进行多个数据库实例合并成一个数据库的迁移
• 在做 full dump 的起始阶段,需要在 source 端停止写,让 DMS 抓到起始点启动任务,并且在 full dump 期间,source 端不能进行 DDL 操作
Best Practice
• 在进行迁移时,可以考虑将目标机型起大一些,譬如说,本来需要一个 4vCPU 32G memory 的数据库,那么在最开始迁移的时候,可以起一个 8vCPU 的实例,更高的机能也伴随更好的网络性能,可以帮助迁移任务更快的完成。在 CDC 阶段业务趋于平稳,进行 cut off 之前,可以将实例的机型再调整回 4vCPU。虽然这个操作会导致实例重启,但是因为此时还没有进行 cut off,而且重启之后,复制也会自动继续,所以不需要太担心。
• 综合使用多种监控指标和工具
o 在源库可以执行 show processlists; 查看任务启动的情况
// a better show processlist SELECT ID, TIME, USER, HOST, DB, COMMAND, STATE, INFO FROM INFORMATION_SCHEMA.PROCESSLIST WHERE DB IS NOT NULL AND (`INFO` NOT LIKE '%INFORMATION_SCHEMA%' OR INFO IS NULL) ORDER BY `DB`, `TIME` DESC |
o 在 DMS Console,通过 Storage usage in total bytes 查看迁移的数据量的变化,以及速度是否正常
o 在目标端,也就是 GCP 端的 Cloud SQL,可以在创建或者任务开启之前,开启 Query Insights,通过这个工具来查看数据库的写入情况
■ 在 full dump 期间是无法额外手动连接 Cloud SQL,因此无法执行 show processlist 查看
■ Query Insights 是一个免费工具,如果是在数据库启动之后再开启,也不会导致数据库重启
o Cloud SQL 同时还提供 System Insights,用来监控一些系统指标,包括但不限于
■ CPU utilization
■ Disk read/write operations
■ Ingress/egress bytes
■ Database load per database
■ Log entries by severity
o 查看 replication-setup.log 是否有报错
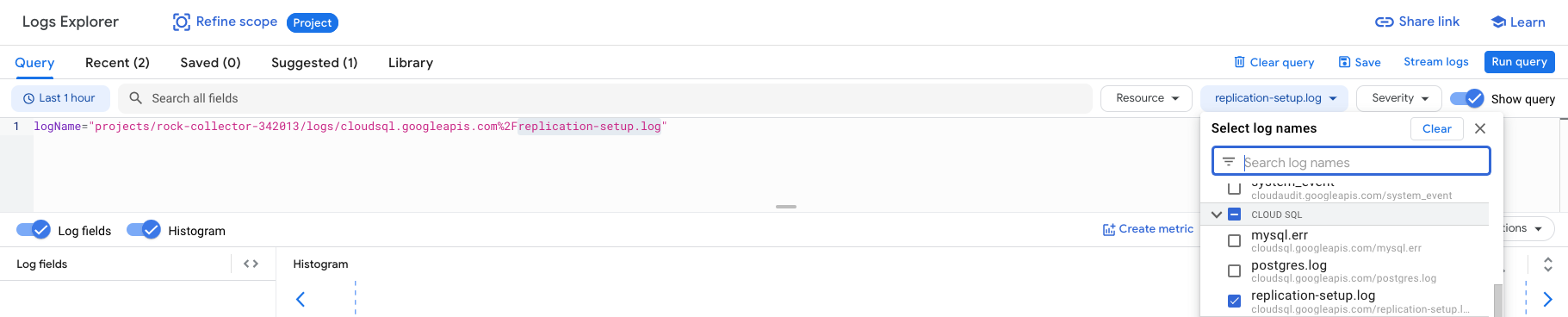
• 在 cut off 前,除了通过 DMS Console 提供的 Replication delay 指标判断源库和目标端是否同步,最好在目标端,也就是 GCP Cloud SQL 上执行 show slave status;对比Read_Master_Log_Pos 与 Exec_Master_Log_Pos 之间的差值来判断复制延迟(首先要确保两个log file 也是一致的)
• 为了保证数据的一致性,还是需要在 cut off 时,对源段的写入进行暂停。验证没有延迟后,进行 GCP 从库的 promotion。整个 promotion 的时间大概为 2 分半(测试库为空库)到 3 分钟(测试库有 1.3T 的数据)。
o 在 Promotion 之前,可以在 GCP 的数据库上创建一个从库(源段数据库 a --> GCP 数据库 b --> GCP 数据库 b 的从库 c)
o 创建从库前,首先在数据库 b 上先点击 Enable replication,这一步会使数据库 b 生成 binlog(默认情况下,从库是不生成 binlog 的),这个按钮会在 CDC 阶段可用,在 full dump 阶段这个按钮会是灰掉不可用的状态
o 在开启 replication 之后,点击 create read replica 就可以创建从库 c 了,当 c 创建好切没有太大的延迟,可以将 c promote 出来,进行数据和功能的验证

• 将参数 max_allowed_packet 的值调大可以加速 mysqldump 的速度,尤其对有 blob 类型数据的表。注意,如果将源端的参数调大,需要将目标端的该参数一起调大到同一数值。
• 在默认情况下,mysql 的复制是单线程的,在 mysql 5.7 以及更高版本上,可以在目标端,也就是 Cloud SQL MySQL 上通过调整参数开启多线程复制
o slave_parallel_workers
o slave_parallel_type = logical_clock
o slave_preserve_commit_order = 1
o slave_pending_jobs_size_max (最大可设置为 1G)
• 在迁移 mysql 数据库时,系统库并不会被迁移,也就是说,user 信息以及相关的权限并不会从源端迁移到目标端。需要在目标端,也就是 Cloud SQL MySQL 上重建用户
o 可以在 GCP Cloud SQL Console 界面的 User 页面修改密码或者添加新用户
o 也可以在迁移进入到 CDC 阶段后,用 root 账户 login 到实例里进行创建
Data Validation Tool
• Introducing the Data Validation Tool for EDW migrations
• Automate Validation using the Data Validation Tool (DVT) Lab
迁移时,如何避免 source 端停写
使用 read replica 作为桥梁
如果是自建的 MySQL,或者是 AWS RDS 等其他云平台的数据库实例,可以通过使用(创建)从库的方法进行迁移。以 AWS RDS 为例:
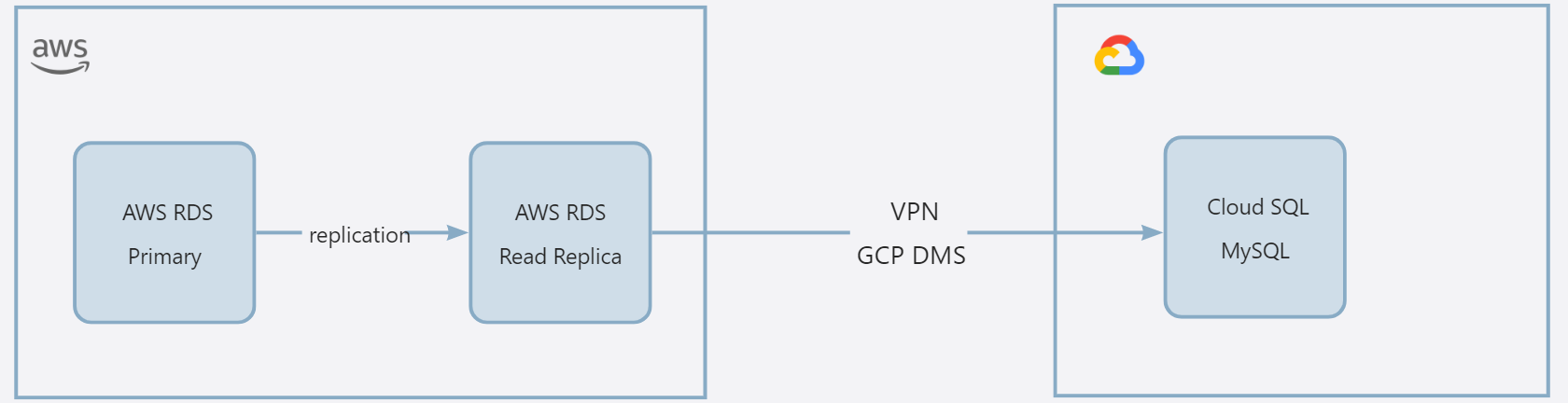
通过这种方式,可以停止 AWS 端主从复制,此时 AWS RDS Read Replica 做为 Cloud SQL MySQL 的源端,且没有写入操作,可以顺利启动 DMS 任务。具体步骤如下:
1. 如果没有 read replica,需要先创建一个 replica
2. AWS RDS 的 read replica by default 是不开启备份的,而不开启备份就无法产生后续用于复制迁移的 binlog,因此需要通过修改实例,手动开启从库的备份
a. 不需要修改 read_only 参数
3. 创建用于复制的用户,以及赋予合适的权限
CREATE USER 'repl_user'@'mydomain.com' IDENTIFIED BY 'password'; GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl_user'@'mydomain.com'; |
4. 查询从库上是否产生了 binlog,并设置合适的 binlog 保留时间。
a. 参数 binlog_format 的值需要修改为 ROW,这个参数在 AWS RDS 的默认值为 mixed。
b. 如果使用的是默认参数组,默认参数组不支持修改参数,需要创建自定义参数组,设置 binlog_format = ROW, 然后修改数据库实例,应用新的参数组,并重启从库实例使新的参数组生效
show binary logs; +----------------------------+-----------+------------------------------+ | Log_name | File_size | Encrypted | +----------------------------+-----------+------------------------------+ | mysql-bin-changelog.000038 | 601 | No | | mysql-bin-changelog.000039 | 601 | No | | mysql-bin-changelog.000040 | 157 | No | +----------------------------+-----------+------------------------------+ call mysql.rds_set_configuration('binlog retention hours', 168); call mysql.rds_show_configuration; +------------------------+-------+-----------------------------------------------------------------------------------------------------------+ | name | value | description | +------------------------+-------+-----------------------------------------------------------------------------------------------------------+ | binlog retention hours | 168 | binlog retention hours specifies the duration in hours before binary logs are automatically deleted. | | source delay | 0 | source delay specifies replication delay in seconds between current instance and its master. | | target delay | 0 | target delay specifies replication delay in seconds between current instance and its future read-replica. | +------------------------+-------+-----------------------------------------------------------------------------------------------------------+ |
5. 停止 AWS RDS 主从的复制
CALL mysql.rds_stop_replication; |
6. (可以稍等待 1 分钟后)开启 GCP DMS 任务
a. 此时 DMS 任务的配置中,源段应该设定为 AWS RDS 的从库,而非主库
7. 上文中有提及,由于 DMS 在 full dump 期间不支持 DDL 操作,因此可以考虑在 full dump 期间,持续保持 AWS 端的主从复制断开,等到进度进展到 CDC 阶段,再恢复 AWS 主从之间的复制
8. 恢复 AWS 主从之间的复制
CALL mysql.rds_start_replication; |
9. 观察 AWS 主从复制的延迟,以及 DMS 任务的复制延迟。
a. 复制延迟的指标一般是基于 slave_behind_second 这个值来的,考虑到复制原理,这个值有的时候不是特别准确
b. 最好通过在从库上执行 show slave status;对比 Read_Master_Log_Pos 与 Exec_Master_Log_Pos 之间的差值来判断复制延迟
Master_Log_File: mysql-bin.000007 Read_Master_Log_Pos: 67748 <-source binary log position indicating how far the IO_THREAD has read events from that log Relay_Log_File: relay-log.000004 Relay_Log_Pos: 29775 Relay_Master_Log_File: mysql-bin.000007 Slave_IO_Running: Yes Slave_SQL_Running: Yes Exec_Master_Log_Pos: 64282 <—Coordinates in the source binary log indicating how far the replication SQL (applier) thread has executed events received from that log |
请注意,这个 workaround 并不适用于 AWS Aurora MySQL。这个 workaround 的核心是需要在从库上产生 binlog,用于后续的复制迁移。然而对 Aurora 来说,整个 cluster 公用一个存储,只有在 wirter 上会生成 binlog,而且 Aurora 无法在同一个 region 里创建 cluster 的 replica cluster,因此没有办法做类似的链式复制。如果 Source 端是 Aurora MySQL 的话,可以在 EC2 上自建 MySQL 作为链式复制的桥梁,或者使用其他的迁移工具。
使用手动 dump file 的方式做 GCP DMS continuouse migration
Prerequisites
• enable GTID
o 如果 source 是 GCP Cloud SQL,默认是开启 GTID 的
mysql> show global variables like '%gtid%'; +----------------------------------+-----------------------------------------------+ | Variable_name | Value | +----------------------------------+-----------------------------------------------+ | binlog_gtid_simple_recovery | ON | | enforce_gtid_consistency | ON | | gtid_executed | fd1a7b66-34ed-11ee-9c18-42010a15b1c3:1-825785 | | gtid_executed_compression_period | 1000 | | gtid_mode | ON | | gtid_owned | | | gtid_purged | fd1a7b66-34ed-11ee-9c18-42010a15b1c3:1-776571 | | session_track_gtids | OFF | +----------------------------------+-----------------------------------------------+ |
o 如果是 AWS RDS 或者 Aurora MySQL,默认不开启 GTID,需要在自定义参数组中开启以下参数
■ gtid_mode = ON
■ enforce_gtid_consistency = ON
■ binlog_format = ROW
用 mysqldump 将数据库倒出
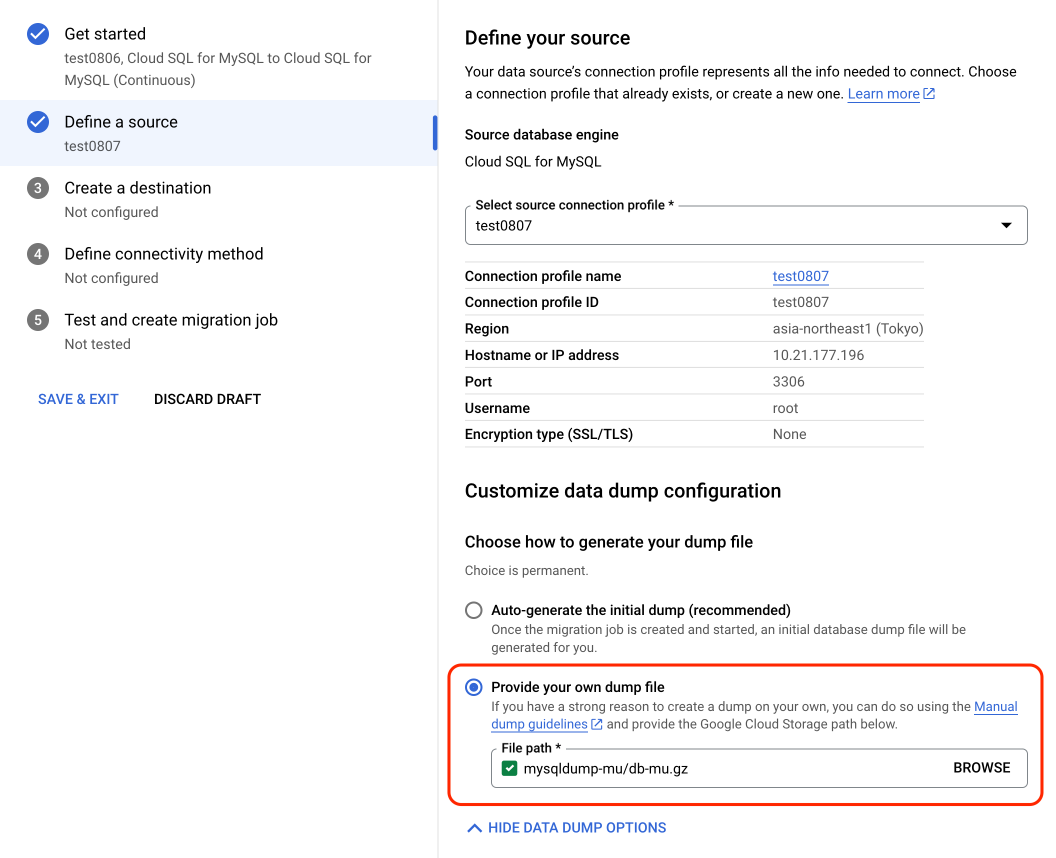
由于用 GCP 的 DMS 方法,需要在开始时在源库停止写,因此也可以使用 mysqldump 手动导出数据库的方式
mysqldump \\ -h [SOURCE_ADDR] -P [SOURCE_PORT] -u [USERNAME] -p \\ --databases [DBS] \\ --hex-blob \\ --no-autocommit \\ --default-character-set=utf8mb4 \\ --master-data=1 \\ --single-transaction \\ --routines \\ | gzip \\ | gsutil cp - gs://[BUCKET_NAME]/[DUMP_FILENAME].gz
//example mysqldump \\ -h 10.21.177.196 -P 3306 -u root -p \\ --databases mu \\ --hex-blob \\ --no-autocommit \\ --default-character-set=utf8mb4 \\ --set-gtid-purged=on \\ --column-statistics=0 \\ --single-transaction \\ --routines \\ | gzip \\ | gsutil cp - gs://mysqldump-mu/db-mu.gz
//mysqldump的参数设置,请参考官方文档 1. mysqldump :https://dev.mysql.com/doc/refman/8.0/en/mysqldump.html 2. https://cloud.google.com/database-migration/docs/mysql/mysql-dump?authuser=1&_ga=2.85122393.-1375574886.1685340733 |
注意:
1. 在做 mysqldump 的时候,不要做 DDL,以保证数据的一致性
2. mysqldump 在开始 dump 前,会在所有的 tables 上加一个 global read lock (flush tables with read lock;),需要数据库在一个比较短的时间内没有写入 (~20s)
常见问题
Definer 的相关问题
Definer is not supported. Definer user root@localhost not supported. Please update host to %
MySQL 迁移作业不会迁移用户数据。因此,如果源数据库包含由用户使用 DEFINER 子句定义的元数据,则在新的 Cloud SQL 副本上调用这些元数据时会失败,因为这些用户在新的 Cloud SQL 副本上还不存在。
• 通过以下语句查询 Definer
SELECT DISTINCT DEFINER FROM INFORMATION_SCHEMA.EVENTS WHERE EVENT_SCHEMA NOT IN ('mysql', 'sys');
SELECT DISTINCT DEFINER FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA NOT IN ('mysql', 'sys');
SELECT DISTINCT DEFINER FROM INFORMATION_SCHEMA.TRIGGERS WHERE TRIGGER_SCHEMA NOT IN ('mysql', 'sys');
SELECT DISTINCT DEFINER FROM INFORMATION_SCHEMA.VIEWS WHERE TABLE_SCHEMA NOT IN ('mysql', 'sys'); |
如果您的元数据由 'root'@'localhost' 创建,则迁移过程将失败。在开始迁移作业之前,请将定义者更改为其他用户。
https://cloud.google.com/database-migration/docs/mysql/mysql-definer
• 要更改 Definer
show create procedure prop_add_partition; 得到 procedure 的内容如下: CREATE DEFINER=`root`@`localhost` PROCEDURE `prop_add_partition`( IN daytime DATE, IN num INT(10), IN tname VARCHAR(50) ) BEGIN DECLARE i INT DEFAULT 0; WHILE i < num DO SET @dd = DATE_ADD(daytime, INTERVAL i DAY); SET @dd2 = DATE_ADD(@dd, INTERVAL 1 DAY); SET @pname = CONCAT('p', DATE_FORMAT(@dd, '%Y%m%d')); SET @pvalue = TO_DAYS(@dd2); SET @v_add_sql = CONCAT('ALTER TABLE ', tname, ' REORGANIZE PARTITION pp INTO (PARTITION ', @pname, ' VALUES LESS THAN (', @pvalue, '),PARTITION pp VALUES LESS THAN (MAXVALUE));'); PREPARE stmt FROM @v_add_sql; EXECUTE stmt; SET i = i + 1; END WHILE; END
修改 definer,drop 掉旧的,然后创建新的 delimiter $$ CREATE DEFINER=`root`@`%` PROCEDURE `prop_add_partition`( IN daytime DATE, IN num INT(10), IN tname VARCHAR(50) ) BEGIN DECLARE i INT DEFAULT 0; WHILE i < num DO SET @dd = DATE_ADD(daytime, INTERVAL i DAY); SET @dd2 = DATE_ADD(@dd, INTERVAL 1 DAY); SET @pname = CONCAT('p', DATE_FORMAT(@dd, '%Y%m%d')); SET @pvalue = TO_DAYS(@dd2); SET @v_add_sql = CONCAT('ALTER TABLE ', tname, ' REORGANIZE PARTITION pp INTO (PARTITION ', @pname, ' VALUES LESS THAN (', @pvalue, '),PARTITION pp VALUES LESS THAN (MAXVALUE));'); PREPARE stmt FROM @v_add_sql; EXECUTE stmt; SET i = i + 1; END WHILE; END$$ |
Access denied; you need (at least one of) the SUPER privilege(s) for this operation.
类似的,这个报错也是由于 superuser@localhost(比如上个 issue 中的 root@localhost)导致的,解决方法也是同上
Definer user 'x' does not exist. Please create the user on the replica.
User ‘x' 没有存在于 GCP 端的目标 Cloud SQL 库中。可以手动在 Cloud SQL Console 上添加该用户。
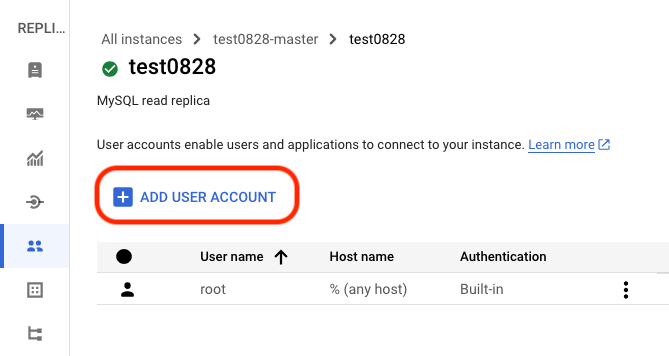
此时新添加的用户,将与执行添加的用户享有同样的权限。譬如说,数据库的 root 用户此时拥有最高权限,此时,添加一个名为 ‘xxx’ 的新用户,那么 xxx 将与 root 享用同样的权限。
这显然并不符合数据库的安全管理要求,但是不需要担心。DMS 任务在做 full dump 的阶段时,此时作为目标的 Cloud SQL 库是不可以访问的,当复制进行到 CDC 的阶段,就可以登录到数据库对该用户('xxx')的权限进行限制,而此时因为迁移还在进行中,只有负责迁移的人员会对数据库进行访问,并没有真正的接入其他应用或者被其他用户访问,因此数据库的安全仍然在一个可控范围内。
ERROR 1045 (28000) at line {line_number}: Access denied for user 'cloudsqlimport'@'localhost.
这依然是一个 Definer 相关的报错。源数据库的某个 Definer 没有存在于目标数据库中
Error importing data: generic::unknown:exit status 1 ERROR 1227 (42000) at line 18551: Access denied; you need (at last one of) the SUPER privilege(s) for this operation
可能有两种原因导致这个报错:
1. dump file 包含了系统数据库(mysql)
a. 在 --database 中只配置需要迁移的自建的用户数据库,不要包含数据库
b. 如果是使用其他工具,将 mysql 等系统库排除
2. dump file 包含了 definer 信息
a. 如果 definer 是 root@localhost,将 definer 的信息移除,或者修改为 root@%
b. 如果 definer 是其他用户,可以在 GCP 端创建同名用户
Error UNSUPPORTED_STORAGE_ENGINE
Your source has tables with unsupported storage engine. Only InnoDB storage engine tables are well supported for migration.
DMS 任务只能迁移存储引擎为 InnoDB 的数据。一般出现这种报错,常见的原因是数据库中有的数据存储类型为 MyISAM。 MyISAM 是基于一种老的(现在已经不用了)ISAM 存储引擎而来的,是一种 non-transactional 的存储引擎。当数据库执行 PITR 操作时,这种存储引擎的数据会打断数据库的恢复,造成整个进程的失败。
• 查找没有使用 InnoDB 存储引擎的表
SELECT TABLE_NAME, ENGINE FROM information_schema.TABLES WHERE TABLE_SCHEMA = 'dbname' AND ENGINE <> 'InnoDB'; |
• 修改表的存储引擎
ALTER TABLE table_name ENGINE=InnoDB; |
参数一致性的问题
有一些参数(flag),需要在任务开始前,就在从库上先配置好,确保主从之间的参数一致性。比较常见的包括 sql_mode, default_time_zone, character_set_server, collation_server 等。在创建 DMS 任务的时候,就可以在创建目标实例的页面进行参数的配置,但是由于某些原因,可能存在某些配置的参数,在 DMS 的console 界面找不到。譬如,在 Cloud SQL Console 界面可以配置的 collation_server, 在 DMS 任务启动目标数据库的 flag 配置界面就没有。
解决方法是,对于在 DMS 端无法配置的参数,可以在创建好 DMS 任务后,先不启动,转到 Cloud SQL 界面,继续对未配置的 flags 进行配置,都确认无误后再启动 DMS 任务。这个问题后台已经在进行积极的修复。
• Cloud SQL MySQL 支持的 Flag 列表,在列表尾端有注明修改 flag 是否会导致实例重启
• 不同云平台提供的数据库服务,对某些 flag 有不同的支持,譬如 AWS Aurora version 2.x (MySQL 5.7)支持 utf8mb4_0900_as_ci collation,但是 Cloud SQL for MySQL 5.7 不支持该 collation
启动任务后,状态在开始 full dump 之后又出现等待源端停止写
在前边有提到,GCP DMS 在启动任务时,需要停止源段的写入,通常小于一分钟,对于比较大的数据库,可能需要几分钟。但是在某些极端少见的情况下,会发现当状态转变成开始进行 full dump 的阶段,然后继续源段的写入操作后,导致 DMS 任务状态又变成等待源端数据库停止写操作(Waiting for source writes to stop)。这是由于任务运行的还不够平稳造成的。
因此,在开始任务时,用户可以对以下内容进行监控,来了解任务的运行情况
• 在源端执行 show processlist; 观察是否有 DMS 的进程对源库的数据进行 select
• 在 DMS Console 的任务界面,可以监控 “Storage usage in total bytes” 指标。根据这个指标,可以有效的掌握数据的写入情况,以及了解写入速度(根据经验,如果是 4 条 ipsec tunnel 的同 region 的 VPN,DMS 可以在 1 个小时迁移将近 200G 数据,不同的 region 情况可能稍有出入)。
• 在目标端,也就是 GCP 端的 Cloud SQL,可以在创建或者任务开启之前,开启 Query Insights,通过这个工具来查看数据库的写入情况
o 在 full dump 期间是无法额外手动连接 Cloud SQL,因此无法执行 show processlist 查看
o Query Insights 是一个免费工具,如果是在数据库启动之后再开启,也不会导致数据库重启
• Cloud SQL 同时还提供 System Insights,用来监控一些系统指标,包括但不限于
o CPU utilization
o Disk read/write operations
o Ingress/egress bytes
o Database load per database
o Log entries by severity
综合使用这些工具和监控指标,可以有效的帮助了解迁移任务的进行情况。比如,在 DMS 页面看到怎么几分钟了,存储的使用量始终持平,而且源库的 processlist 也都在 sleep,是不是数据迁移有什么问题?这个时候就可以看一下 query insights,选定最近的几分钟,看有什么语句正在执行,同时看 system insights,现在 disk 的操作主要是读还是写?database load per database 的指标中,主要是哪个数据库在执行操作?以及 eplication-setup.log 中是否有报错。在查看了这些信息后,会发现,disk opeartion 显示有大量的 read 操作,query insights 显示正在创建 secondary index,所以迁移任务还是在很好的运行中,就不用担心了。
DMS 任务已经迁移了很多数据,却突然存储使用显示降为 0
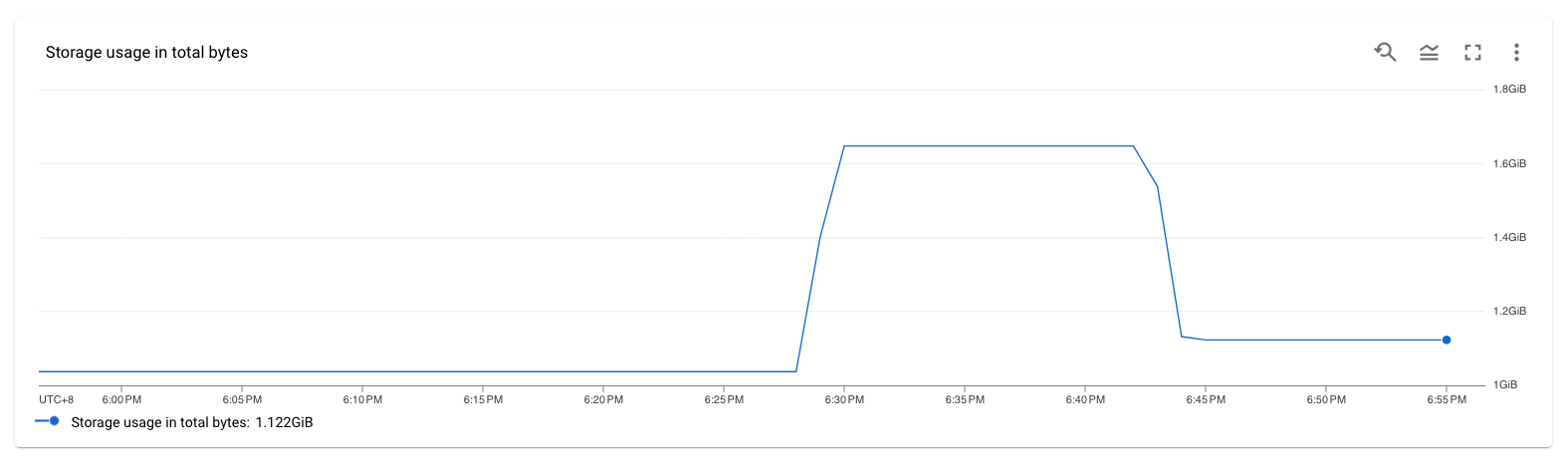
查看 replication-setup.log:
"DUMP_STAGE(RETRY): Attempt 1/2: import failed: get errors when dumping data: Error: [Worker001]: Error while chunking `ads`.`prod_filled_v2`: MySQL Error 2013 (HY000): Lost connection to MySQL server during query, Error: While 'Dumping data': Fatal error during dump
All 2 import attempts failed: Timed out when waiting for dump metadata file: context deadline exceeded; Clearing database and trying again."
timestamp: "2023-09-05T10:46:57.946350Z"
在日志中可以看到 Timed out when waiting for dump metadata file: context deadline exceeded; Clearing database and trying again。这是在 mysqldump metadata 的时候 timeout 导致的。可以将这几个参数调大 max_allowed_packet,net_read_timeout,net_write_timeout 。由于报错,继而清理了数据库,于是在指标上显示为存储使用的下降。
还有另外一种情况是,在迁移时,遇到无法处理的数据导致报错。由于 GCP DMS 是以 mysqldump 为核心的 shell 命令,因此会在 retry 之前先对之前已经迁移的数据进行回滚。这种情况也会导致 storage usage 的指标回落。
Lost connection to MySQL during Dump
在 replication-setup.log 中看到类似的报错:
DUMP_STAGE(RETRY): Attempt 1/2: import failed: get errors when dumping data: Error: [Worker001]: Error while chunking `ads`.`prod_filled_v2`: MySQL Error 2013 (HY000): Lost connection to MySQL server during query, Error: While 'Dumping data': Fatal error during dump
All 2 import attempts failed: Timed out when waiting for dump metadata file: context deadline exceeded; Clearing database and trying again.
这是由于在 dump 比较大的表是出现了超时问题,可以调整以下参数尝试解决:
• max_allowed_packet = 1G
• net_read_timeout = 3600
• net_write_timeout = 3600
其他的一些常见的问题,请参考我们的文档中 troubleshooting 的部分
https://cloud.google.com/database-migration/docs/mysql/diagnose-issues
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们