首页 > 资源 > 文章详情
正式发布 Cloud TPU v5e,以实现经济高效的 AI 模型训练与推理
我们宣布 Cloud TPU 平台的两项重要更新。首先,在最新 MLPerf™ Training 3.1 测试结果中1 ,TPU v5e 在大语言模型(LLM)训练方面的性价比较上一代 TPU v4 提高了 2.3 倍。在此之前,9 月份的 MLPerf™ Inference 3.1 基准测试显示,TPU v5e 在大型语言模型推理方面的性价比比 TPU v4 提高了 2.7 倍。
其次,Cloud TPU v5e 现已正式发布,Singlehost 推理和 Multislice Training 技术也同步上市。这些进步为 Google Cloud 客户带来了成本效益、可扩展性和多功能性,能够使用统一的 TPU 平台来运行训练和推理工作负载。
自今年 8 月份推出以来,TPU v5e 已被客户广泛用于运行各种工作负载,涵盖了 AI 模型训练和服务领域:Anthropic 公司正在使用 TPU v5e 来有效扩展其 Claude LLM 的服务。Hugging Face 和 AssemblyAI 公司分别使用 TPU v5e 来高效服务图像生成和语音识别工作负载。此外,Google 还借助 TPU v5e 来处理 Google Bard 等前沿内部技术的大规模训练和服务工作负载。
在 MLPerf Training 3.1 LLM 基准上提供 2.3 倍的性能效率
在 MLPerf Training 3.1 基准测试中,针对 GPT-3 175B 模型,我们进一步发展了新颖的混合精度训练方法,除了使用本机 BF16 外,还利用了 INT8 精度格式。这种新技术被称为精确量化训练(Accurate Quantized Training / AQT),使用了一个量化库,其中利用了当今 AI 硬件加速器的低位和高性能数字,该量化库可供开发人员在 Github 上使用。借助 Multislice Training 技术,GPT-3 175B 模型在扩展到 4,096 个 TPU v5e 芯片时能够收敛(即继续训练将不会进一步改善模型)。性价比更高意味着客户现在可以在节约费用的同时提高模型的准确性。
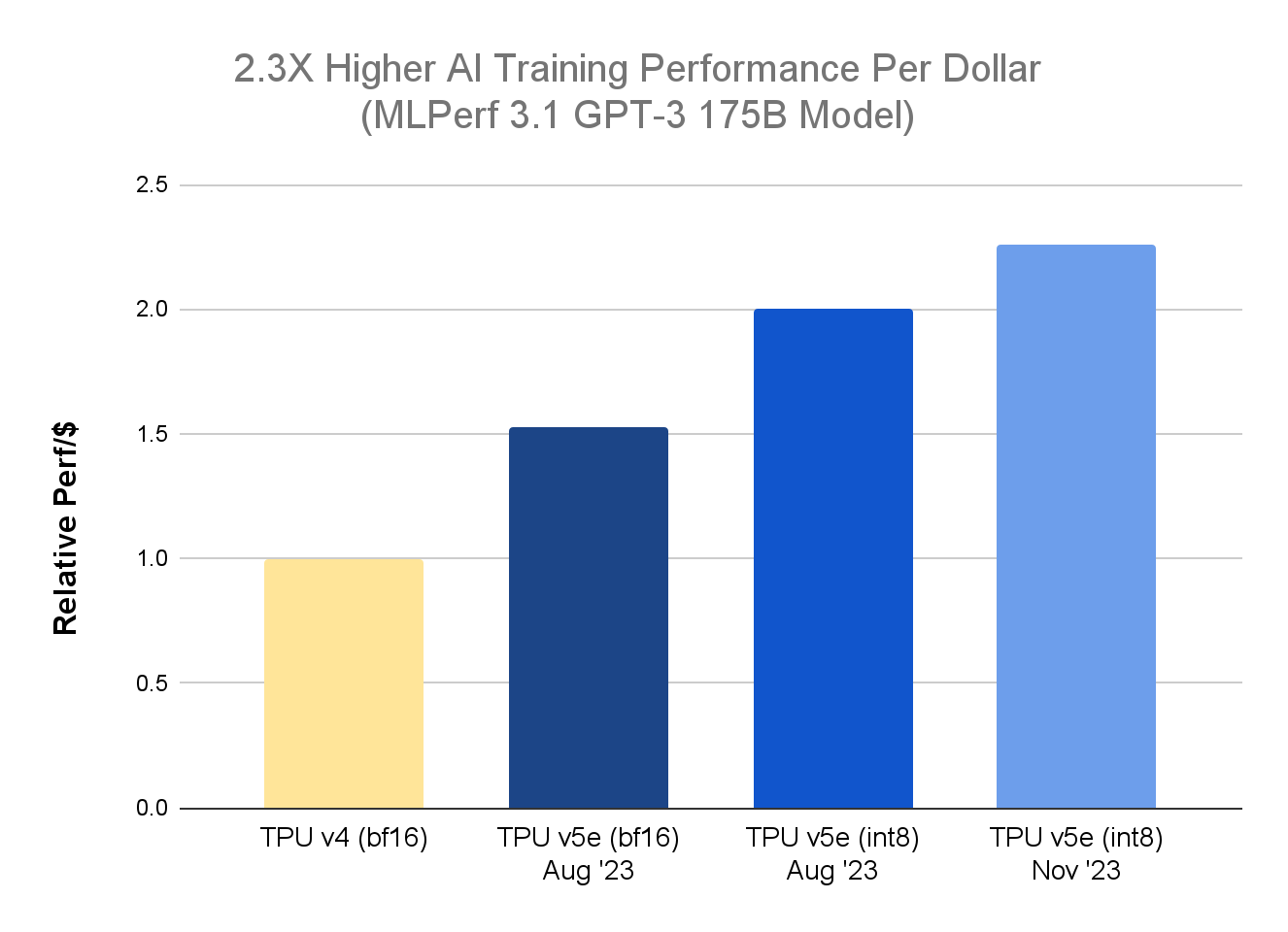
TPU v5e 数据来自 MLPerf™ 3.1 Training Closed 结果;TPU v4 数据来自 Google 内部数据。截至 2023 年 11 月,GPT-3 1750 亿参数模型的所有数据均按每芯片 seq-len=2048 为单位完成标准化。并以 TPU v4:3.22 美元/芯片/小时、TPU v5e:1.2 美元/芯片/小时的公开定价显示每美元相对性能。*1
利用 Multislice Training 技术扩展到 50,000 个芯片
Cloud TPU Multislice Training 是一项全栈技术,可实现跨数万个 TPU 芯片进行大规模 AI 模型训练,为训练大型生成式 AI 模型提供了一种简单可靠的方法,从而加快价值实现速度并提高成本效率。
最近,我们在最多数量的 AI 加速器芯片上运行了世界上最大的分布式 LLM 训练作业之一。利用 Multislice 和 AQT 驱动的 INT8 精度格式,我们扩展到了 50,000 多个 TPU v5e 芯片,以训练一个 32B 参数的密集 LLM 模型,同时实现了 53% 的有效模型触发器利用率 (MFU)。作为对比,当在 6,144 个 TPU v4 芯片上训练 PaLM-540B 时,我们实现了 46% 的 MFU。
此外,我们的测试还报告了高效的扩展性,使研究人员和从业者能够快速训练大型复杂模型,助力在各种 AI 应用领域实现更快的突破。
但我们并不止步于此。我们持续投资于新颖的软件技术,以推动可扩展性和性能的发展,从而使已经在 TPU v5e 上部署了 AI 训练工作负载的客户能够在新功能推出时从中受益。例如,我们正在探索分层数据中心网络(DCN)集合等解决方案,并进一步优化跨多个 TPU pod 的编译器调度。
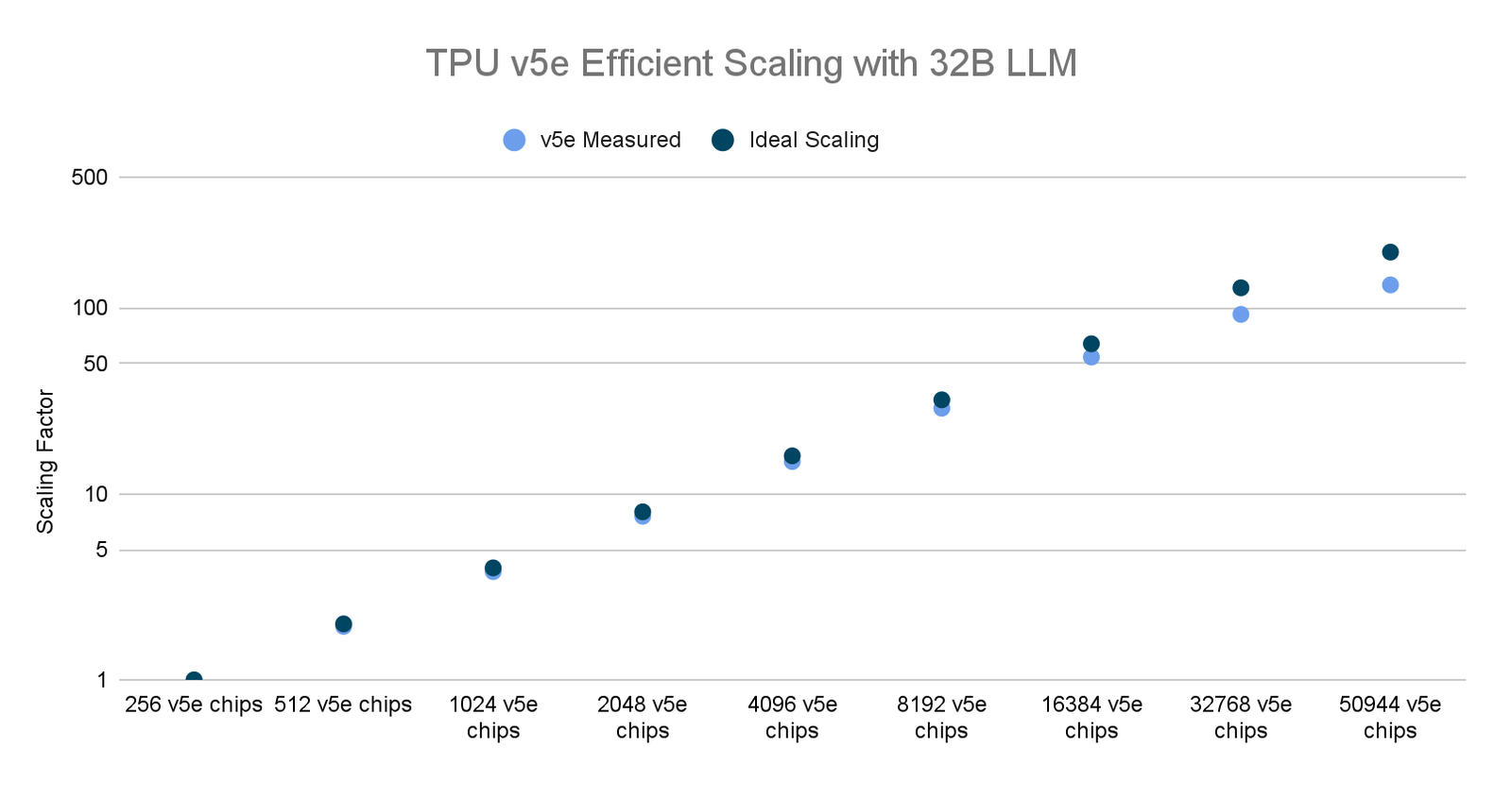
TPU v5e 数据来自截至 2023 年 11 月的 Google 内部数据,针对使用 MaxText 实现的 320 亿参数解码器语言模型的所有数据均按每芯片 seq-len=2048 为单位完成标准化。*2
客户部署 Cloud TPU v5e 进行 AI 训练和服务
客户凭借大规模的 Cloud TPU v5e 集群快速高效地进行前沿 LLM 的训练和服务。例如,AssemblyAI 正致力于实现尖端 AI 语音模型的民主化,并在 TPU v5e 上取得了显著的成果。
“最近,我们有机会在 GKE 上试验 Google 的全新 Cloud TPU v5e,以了解这些专为 AI 设计的芯片是否能降低我们的推理成本。在真实环境中的真实数据上运行我们的生产语音识别模型后,我们发现 TPU v5e 的性价比比其他替代方案高出多达 4 倍。” ——AssemblyAI 技术副总裁 Domenic Donato
另外,10 月初,我们与 Hugging Face 合作进行了一项演示,展示了使用 TPU v5e 加速 Stable Diffusion XL 1.0(SDXL)推理的过程。Hugging Face Diffusers 现在支持通过 JAX 在 Cloud TPU 上提供 SDXL,从而实现内容创作用例的高性能和高效推理。例如,在文本到图像生成工作负载的情况下,在使用了八个芯片的 TPU v5e 上运行 SDXL 可以在一个芯片生成一张图像的时间内生成八张图像。
Google Bard 团队也在使用 Cloud TPU v5e 为其生成式 AI 聊天机器人进行培训和服务。
“自从 Bard 推出以来,TPU v5e 就一直在为 Bard 的 ML 训练和推理工作负载提供支持。我们非常满意 TPU v5e 的灵活性,TPU v5e 可用于大规模的训练运行(数千个芯片)和高效的 ML 服务,并且覆盖 200 多个国家的用户,支持 40 多种语言。” —— Google Bard 的优秀软件工程师 Trevor Strohman
立即使用 TPU v5e 为 AI 生产工作负载提供支持
对于创新速度而言,AI 加速、性能、效率和规模继续发挥着至关重要的作用,对于大模型而言尤其如此。现在 Cloud TPU v5e 已经正式发布,我们迫切期待看到客户和生态系统合作伙伴如何突破可能的极限。若您希望立即开始使用 Cloud TPU v5e,请联系我们。
1. MLPerf™ v3.1 Training Closed 的结果多个基准如图所示。资料日期:2023 年 11 月 8 日。资料来源:mlcommons.org。结果编号:3.1-2004。每美元性能并非 MLPerf 的评估标准。TPU v4 结果尚未经 MLCommons 协会验证。MLPerf™ 名称和标志是 MLCommons 协会在美国和其他国家的商标,并保留所有权利,严禁未经授权的使用。更多信息,请参阅 www.mlcommons.org。
2. 扩展因子为(给定集群规模下的吞吐量)与(基本集群规模下的吞吐量)之比。我们的基本集群规模是一个 v5e pod(例如 256 个芯片)。例如:在 512 芯片规模下,我们的吞吐量是 256 芯片规模下的 1.9 倍,因此扩展因子为 1.9。
3. 为了得出 TPU v5e 的每美元性能,我们用每个芯片的训练吞吐量(以每秒处理的 token 数量来测算)除以按需市场价 1.20 美元,即 TPU v5e 在 us-west4 地区(美国拉斯维加斯)公开提供的每芯片小时价格(美元)。为了得出 TPU v4 的每美元性能,我们将每芯片的训练吞吐量(以每秒处理的 token 数量来测算;Google Cloud 内部结果,未经 MLCommons 协会验证)除以按需市场价 3.22 美元,即 TPU v4 在 us-central2 地区(俄克拉荷马-不公开的 GCP 区域)公开提供的每芯片小时价格(美元)。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们