首页 > 资源 > 文章详情
如何在 BigQuery ML 中进行多变量时间序列预测

无论是公司处于哪个行业,都十分依赖时间序列预测来预测产品需求、预测销售、预测在线订阅/取消以及许多其他用例。这也使得时间序列预测成为 BigQuery ML 中最受欢迎的模型之一。
我们该如何理解多变量时间序列预测呢? 举个例子,如果您想预测冰淇淋的销量,可以使用外部协变量“天气”以及目标指标“过去销量”为预测过程提供帮助。 BigQuery 中的多变量时间序列预测让您可以创建更加准确的预测模型,而无需将数据转移到 BigQuery 以外的地方。
在时间序列预测方面,目标时间序列之外的协变量或特征通常用于提供更佳的预测结果。截至目前,BigQuery ML 仅支持使用 ARIMA_PLUS 模型的单变量时间序列建模。它也是最受欢迎的 BigQuery ML 模型之一。
虽然 ARIMA_PLUS 被广泛使用,但仅仅使用目标变量进行预测在一些场景中是不够的。时间序列中的某些模式会强烈依赖于其他特征。我们也了解到客户对支持多变量时间序列预测的强烈需求,以便您可以使用协变量和特征进行预测。
我们最近宣布了可使用外部回归进行多变量时间序列预测的公共预览版。并且我们正在引入一种新的模型类型——ARIMA_PLUS_XREG,其中 XREG 指的是外部回归量或副特征。您可以使用 SELECT 语句来选择具有目标时间序列的副特征。这个新模型利用 BigQuery ML 线性回归模型来包含辅助特征,并利用 BigQuery ML ARIMA_PLUS 模型对线性回归残差进行建模。
该 ARIMA_PLUS_XREG 模型支持以下功能:
针对数字、分类和数组特征提供自动化的特征工程。
ARIMA_PLUS 模型支持的所有模型功能,例如检测季节性趋势、节假日等。
Headlight 是一家由 AI 驱动的广告代理商,它正在使用多变量预测模型来根据队列年龄确定订阅、取消等漏斗下行指标的转化量。您可以点击此处查看该客户视频和相关演示。
以下部分展示了 BigQuery ML 中全新的 ARIMA_PLUS_XREG 模型的一些示例。 在此示例中,我们探索了 bigquery-public-data.epa_historical_air_quality数据集,其中包含每日空气质量和天气信息。我们使用该模型根据其历史数据和一些协变量(例如温度和风速)来预测 PM2.5。
示例:利用天气信息预测西雅图的空气质量
第一步. 创建数据集
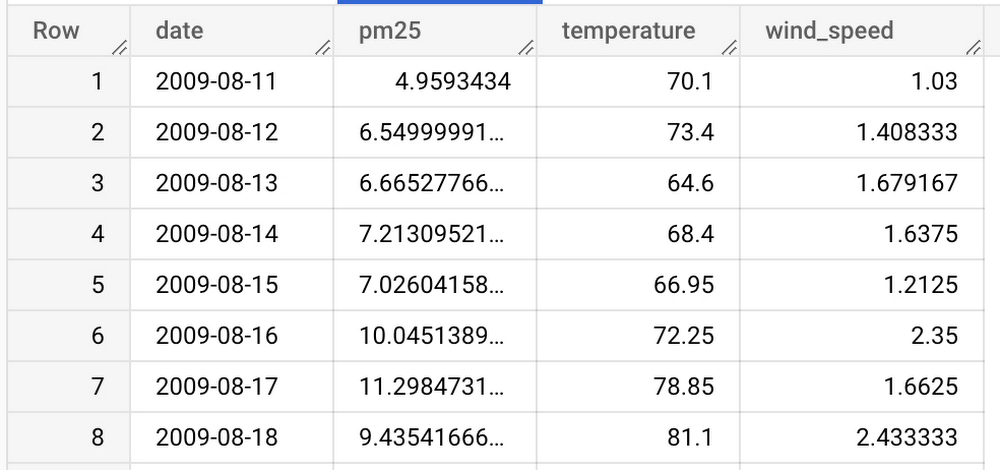
PM2.5、温度和风速数据在单独的表格中。 为了简化查询,通过将这些表连接到新表“bqml_test.seattle_air_quality_daily”来创建一个新表,其中包含以下列:
date: 观测日期
PM2.5: 每日平均 PM2.5 值
wind_speed:每日平均风速
temperature: 每日最高温度
新表包含从 2009-08-11 到 2022-01-31 的每日数据。
CREATE TABLE `bqml_test.seattle_air_quality_daily`
AS
WITH
pm25_daily AS (
SELECT
avg(arithmetic_mean) AS pm25, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.pm25_nonfrm_daily_summary`
WHERE
city_name = 'Seattle'
AND parameter_name = 'Acceptable PM2.5 AQI & Speciation Mass'
GROUP BY date_local
),
wind_speed_daily AS (
SELECT
avg(arithmetic_mean) AS wind_speed, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.wind_daily_summary`
WHERE
city_name = 'Seattle' AND parameter_name = 'Wind Speed - Resultant'
GROUP BY date_local
),
temperature_daily AS (
SELECT
avg(first_max_value) AS temperature, date_local AS date
FROM
`bigquery-public-data.epa_historical_air_quality.temperature_daily_summary`
WHERE
city_name = 'Seattle' AND parameter_name = 'Outdoor Temperature'
GROUP BY date_local
)
SELECT
pm25_daily.date AS date, pm25, wind_speed, temperature
FROM pm25_daily
JOIN wind_speed_daily USING (date)
JOIN temperature_daily USING (date)
以下是数据预览:
第二步. 创建模型
新的多变量模型 ARIMA_PLUS_XREG 的“CREATE MODEL”查询与当前的 ARIMA_PLUS 模型非常相似。其主要区别在于 MODEL_TYPE 和 SELECT 语句中包含的特征列。
CREATE OR REPLACE
MODEL
`bqml_test.seattle_pm25_xreg_model`
OPTIONS (
MODEL_TYPE = 'ARIMA_PLUS_XREG',
time_series_timestamp_col = 'date',
time_series_data_col = 'pm25')
AS
SELECT
date,
pm25,
temperature,
wind_speed
FROM
`bqml_test.seattle_air_quality_daily`
WHERE
date
BETWEEN DATE('2012-01-01')
AND DATE('2020-12-31')
第三步. 预测未来数据
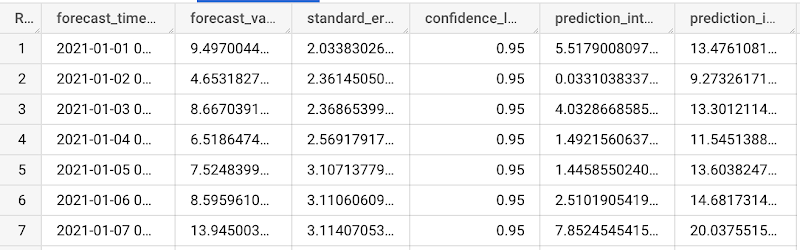
借助创建的模型,您可以使用 ML.FORECAST 函数来预测未来的数据。与 ARIMA_PLUS 模型相比,您必须将未来协变量指定为输入。
SELECT
*
FROM
ML.FORECAST(
MODEL
`bqml_test.seattle_pm25_xreg_model`,
STRUCT(30 AS horizon),
(
SELECT
date,
temperature,
wind_speed
FROM
`bqml_test.seattle_air_quality_daily`
WHERE
date > DATE('2020-12-31')
))
运行完上面的查询后,可以看到预测结果:
第四步. 评估模型
您可以使用 ML.EVALUATE 函数来评估预测误差。您可以将 perform_aggregation 设置为“TRUE”以获取聚合错误指标或“FALSE”来查看每个时间戳错误。
SELECT
*
FROM
ML.EVALUATE(
MODEL `bqml_test.seattle_pm25_xreg_model`,
(
SELECT
date,
pm25,
temperature,
wind_speed
FROM
`bqml_test.seattle_air_quality_daily`
WHERE
date > DATE('2020-12-31')
),
STRUCT(
TRUE AS perform_aggregation,
30 AS horizon))
ARIMA_PLUS_XREG的评估结果如下:

作为对比,我们还在下表中展示了单变量预测 ARIMA_PLUS 结果:
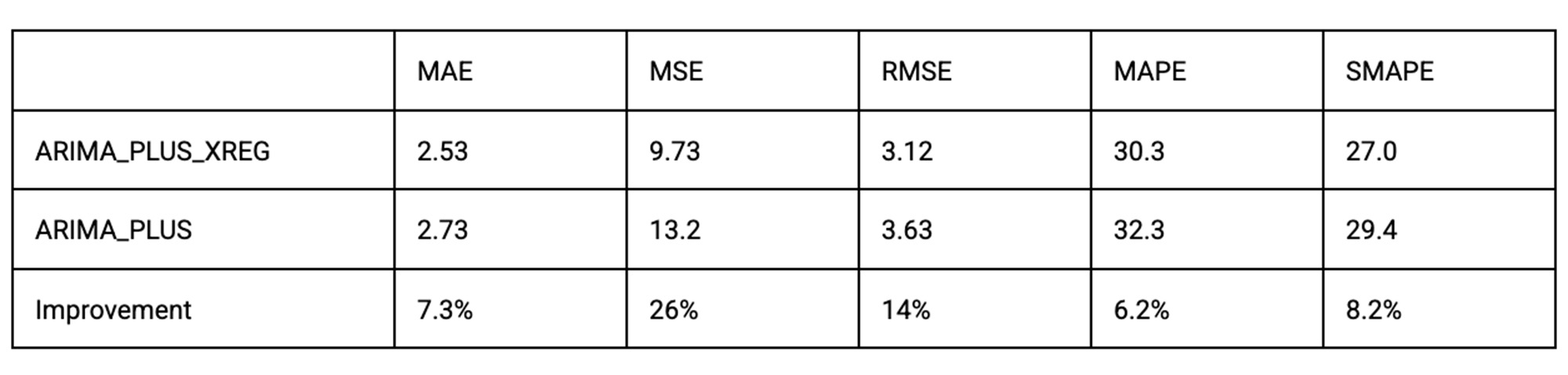
与 ARIMA_PLUS 相比,ARIMA_PLUS_XREG 在这个特定数据集和日期范围内的所有测量指标上具有更好的表现。
总结
在前面的示例中,我们演示了如何创建多变量时间序列预测模型、使用该模型预测未来值以及评估预测结果。 ML.ARIMA_EVALUATE 和 ML.ARIMA_COEFFICIENTS 表值函数也有助于调查您的模型。根据用户的反馈,利用该模型为用户的工作效率带来了以下几方面的提升。
1. 它缩短了预处理数据所花费的时间,并允许用户在进行 ML 时将数据保存在 BigQuery 中。
2. 它减少了了解 SQL 的用户在 BigQuery 中进行 ML 工作的开销。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们