首页 > 资源 > 文章详情
在 Google Kubernetes Engine 上使用 Kubeflow 和 Ray 构建 ML 平台
越来越多的企业正在采用 ML 功能来增强自身的服务、产品和运营能力。随着 ML 不断成熟,他们构建了集中式 ML 平台来为组织中的多个团队和用户提供服务。从本质上说,ML 是一个需要重复迭代的实验过程。ML 平台标准化了模型开发和部署工作流程,为重复过程提供更高的一致性。这不仅提高了生产力,也能够减少从原型到生产的时间周期。
每个组织和 ML 项目都有独特的要求,并且 ML 平台有很多选择。借助 Google Cloud,您可以选择 Vertex AI(一种完全托管的 ML 平台),也可以选择 Google Kubernetes Engine(GKE)在自我管理的资源上构建自定义平台。Vertex AI 提供完全托管的工作流程、工具和基础设施,可降低复杂性、加速 ML 的部署,并更轻松地在组织中扩展 ML。一些组织可能更喜欢构建自己的自定义 ML 平台,这种方法可以灵活地满足高度专业化的 ML 要求和框架。通常,这些组织会针对特定的资源利用行为和基础设施战略来构建自己的平台。
对于 ML 平台来说,开源软件(OSS)是数字创新的重要驱动力。如果您关注 ML 技术的发展,那么您可能会意识到 OSS ML 框架、平台和工具的生态系统不断发展。然而,没有一个开源软件库可以提供完整的 ML 解决方案,因此我们必须集成多个开源软件项目来构建 ML 平台。
要开始构建 ML 平台,您应支持从笔记本原型到扩展培训再到在线服务的基本 ML 用户旅程。如果您的组织有多个团队,您可能还需要通过基于身份的身份验证和授权来支持多用户支持的管理要求。两个流行的开源软件项目——Kubeflow 和 Ray,可以一同支持这些需求。Kubeflow 提供多用户环境和交互式笔记本管理。Ray 在整个 ML 生命周期(包括训练和服务)中编排分布式计算工作负载。
Google Kubernetes Engine(GKE)通过自动扩缩和自动配置为云中部署 OSS ML 软件提供了简化的方式。GKE 减少了大规模部署和管理底层基础设施的工作量,并提供了使用您选择的 ML 框架的灵活性。在本文中,我们将展示如何结合应用 Kubeflow 和 Ray 所带来的无缝体验。我们将演示平台构建者如何将它们部署到 GKE,以提供全面的、可用于生产的 ML 平台。
Kubeflow 与 Ray
首先,让我们了解一下这两个开源软件项目。虽然 Kubeflow 和 Ray 都解决了大规模启用 ML 的问题,但它们所关注的难题角度有所不同。
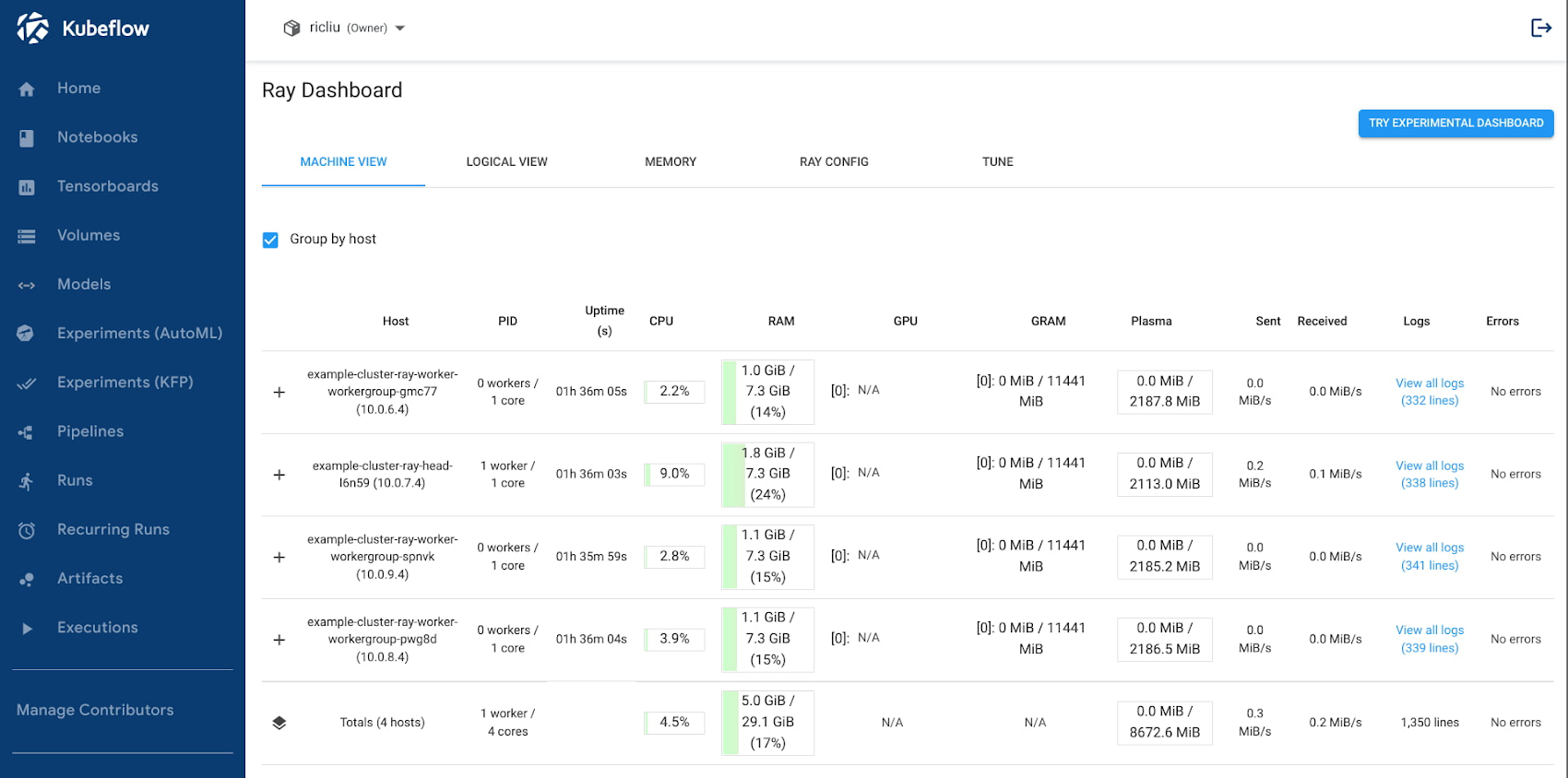
Kubeflow 是一个 Kubernetes 原生的 ML 平台,旨在简化 ML 模型的构建-训练-部署生命周期。因此,它的重点是一般 MLOps。Kubeflow 提供的一些独特功能包括:
Jupyter 笔记本内置集成以进行原型设计
多用户隔离支持
使用 Kubeflow Pipelines 进行工作流编排
通过 Istio 集成进行基于身份的认证和授权
与 GCP、Azure 和 AWS 等主要云提供商开箱即用的集成
来源:https://www.kubeflow.org/docs/started/architecture/
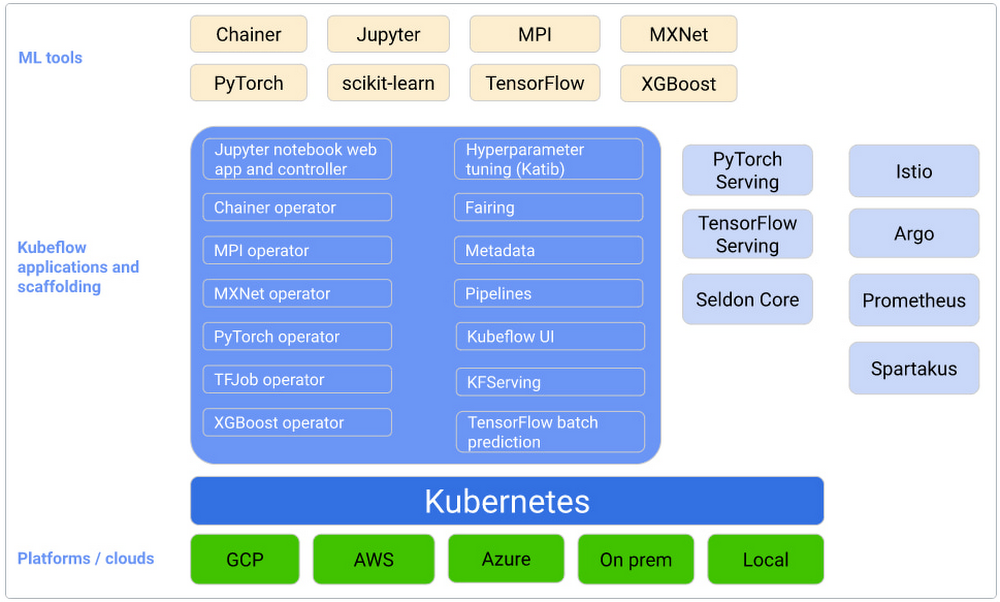
Ray 是一个通用分布式计算框架,具有丰富的库,用于大规模数据处理、模型训练、强化学习和模型服务。作为用于构建和扩展 AI 和 Python 工作负载的简单 API,它深受客户欢迎。它所关注的重点是应用程序本身,允许用户使用一组统一且灵活的 API 构建分布式计算软件。Ray 提供的一些高级库包括:
用于强化学习的 RLLib
用于超参数调整的 Ray Tune
用于分布式深度学习的 Ray Train
用于可扩展的模型服务的 Ray Serve
用于预处理的 Ray Data
来源:https://docs.ray.io/en/latest/index.html#what-is-ray
需要注意的是,Ray 并非 Kubernetes 原生项目。为了在 Kubernetes 上部署 Ray,OSS 社区创建了 KubeRay,顾名思义,它是一个在 Kubernetes 上部署 Ray 的工具包。KubeRay 提供了一套强大的工具,其中包括许多出色的功能,例如自定义资源 API 和可扩展的运算符。您可以在这里了解更多信息。
现在我们已经了解了 Kubeflow 和 Ray 之间的差异,您可能会有一个疑问,哪个平台最适合您的组织?Kubeflow 的 MLOps 功能和 Ray 的分布式计算库都是独立有用的,具有不同的优势。如果我们将这两个系统的优点结合在一起会怎样?试想一下,我们拥有以下这样一个环境:
支持 Ray Train 的自动扩缩和资源配置
集成基于身份的认证和授权
支持多用户隔离和协作
包含交互式笔记本服务器
现在让我们看看如何将这两个平台组合在一起,并利用每个平台提供的有用功能。具体来说,我们将在安装了 Kubeflow 的 GKE 集群中部署 Kuberay。该系统看起来就像这样:

在这个系统中,Kubernetes 集群被划分为逻辑上隔离的工作空间,称为“配置文件”。每个新用户都将创建自己的配置文件,该配置文件是其在 Kubernetes 集群中所有资源的容器。随后,用户可以在指定的命名空间内配置自己的资源,包括 Ray Clusters 和 Jupyter Notebooks。如果用户的资源是通过 Kubeflow 仪表板配置的,那么 Kubeflow 会自动将这些资源放置在其配置文件命名空间中。
在该设置下,每个 Ray 集群默认受到基于角色的访问控制策略(使用 Istio)的保护,以防止未经授权的访问。这允许每个用户独立地与自己的 Ray 集群交互,并允许他们与其他团队成员共享 Ray 集群。
在该设置钟,我使用了以下版本:
Google Kubernetes Engine 1.21.12-gke.2200
Kubeflow 1.5.0
Kuberay 0.3.0
Python 3.7
Ray 1.13.1
可以在此处找到用于此部署的配置文件。
部署 Kubeflow 和 Kuberay
为了部署 Kubeflow,我们将在此处使用 GCP 指令。为简单起见,我主要使用默认配置设置。您可以在部署之前自由尝试自定义,例如,您可以按照这些说明启用集群中的 GPU 节点。
export KUBERAY_VERSION=v0.3.0 kubectl create -k "github.com/ray-project/kuberay/manifests/cluster-scope-resources?ref=${KUBERAY_VERSION}" kubectl apply -k "github.com/ray-project/kuberay/manifests/base?ref=${KUBERAY_VERSION}" |
这将在集群中的“ray-systems”命名空间中部署 KubeRay operator。
创建您的 Kubeflow 用户配置文件
在 Kubeflow 中部署和使用资源之前,您需要先创建用户配置文件。如果您按照 GKE 安装说明进行操作,您应该能够在浏览器中导航到 https://[cluster].endpoints.[project].cloud.goog/,其中[cluster]是您的 GKE 集群的名称,[project]是您的 GCP 项目名称。
此时应该会将您重定向到一个网页,您可以在其中使用 GCP 凭据对自己进行身份验证。
按照对话框的提示进行操作,Kubeflow 将以您作为管理员创建一个命名空间。我们将在本文后面讨论如何邀请其他人加入您的工作区。
构建 Ray Worker 容器镜像
接下来,让我们构建将用于 Ray 集群的容器镜像。Ray 对版本兼容性非常敏感(例如 head 节点和 worker 节点必须使用相同版本的 Ray 和 Python),因此强烈建议准备自己的 worker 容器镜像并对其进行版本控制。从这里的 Docker 页面查找您想要的基础容器镜像:rayproject/ray - Docker Image。
以下是使用 Ray 1.13 和 Python 3.7 运行的 worker 容器镜像:
FROM rayproject/ray:1.13.1-py37 RUN pip install numpy tensorflow CMD ["bin/bash"] |
如果您更喜欢 GPU 而不是 CPU,那么这里是在 GPU 上运行的 worker 容器镜像的相同 Dockerfile:
FROM rayproject/ray:1.13.1-py37-gpu RUN pip install numpy tensorflow CMD ["bin/bash"] |
使用 Docker 构建两个容器镜像并将其推送到您的容器镜像存储库:
$ docker build -t <path-to-your-image> $ docker push <path-to-your-image> |
构建 Jupyter 笔记本容器镜像
同样,我们需要构建我们将要使用的笔记本容器镜像。因为我们要使用这个笔记本与 Ray 集群交互,所以我们需要确保它使用与 Ray Worker 相同的 Ray 和 Python 版本。
Kubeflow 示例 Jupyter 笔记本可以在示例笔记本服务器中找到。对于此示例,我将 Components/example-notebook-servers/jupyter/Dockerfile 中的 PYTHON_VERSION 更改为以下内容:
ARG MINIFORGE_VERSION=4.10.1-4 ARG PIP_VERSION=21.1.2 ARG PYTHON_VERSION=3.7.10 |
使用 Docker 构建笔记本容器镜像并将其推送到容器镜像存储库,与上一步类似:
$ docker build -t <path-to-your-image> $ docker push <path-to-your-image> |
记住您将笔记本容器镜像推送到的位置,我们稍后将使用它。
部署 Ray 集群
现在我们已准备好配置和部署 Ray 集群。
1. 从 GitHub 复制以下示例 yaml 文件:
curl https://github.com/richardsliu/ray-on-gke/blob/main/manifests/ray-cluster.serve.yaml -o ray-cluster.serve.yaml |
2. 编辑文件中的设置:
a. 对于用户命名空间,更改值以与您的 Kubeflow 配置文件名称匹配:
namespace: %your_name% |
b. 对于 Ray head 和 worker 设置,将值更改为指向您之前构建的容器镜像:
image: %your_image% |
c. 根据需要编辑资源请求和限制。例如,您可以在此处更改 worker 节点的 CPU 或 GPU 要求:
resources: limits: cpu: 1 requests: cpu: 200m |
3. 部署集群:
kubectl apply -f raycluster.serve.yaml |
4. 您的集群应该已准备就绪,可以立即运行。如果您在 GKE 集群上启用了节点自动配置,您应该能够看到集群根据使用情况动态扩展和缩减。您可以通过执行以下操作来检查集群的状态:
$ kubectl get pods -n <user name> NAME READY STATUS RESTARTS AGE example-cluster-head-8cbwb 1/1 Running 0 12s example-cluster-worker-large-group-75lsr 1/1 Running 0 12s example-cluster-worker-large-group-jqvtp 1/1 Running 0 11s example-cluster-worker-large-group-t7t4n 1/1 Running 0 12s |
您还可以验证服务端点是否已创建:
$ kubectl get services -n <user name> NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE example-cluster-head-svc ClusterIP 10.52.9.88 <none> 8265/TCP,10001/TCP,8000/TCP,6379/TCP 18s |
记住这个服务名称 - 我们稍后会再讨论它。
现在我们的 ML 平台已全部设置完毕,我们准备开始训练模型。
训练 ML 模型
我们将使用笔记本来安排我们的模型训练。我们可以从 Jupyter 笔记本会话访问 Ray。
1. 在 Kubeflow 仪表板中,导航到“Notebooks”选项卡。
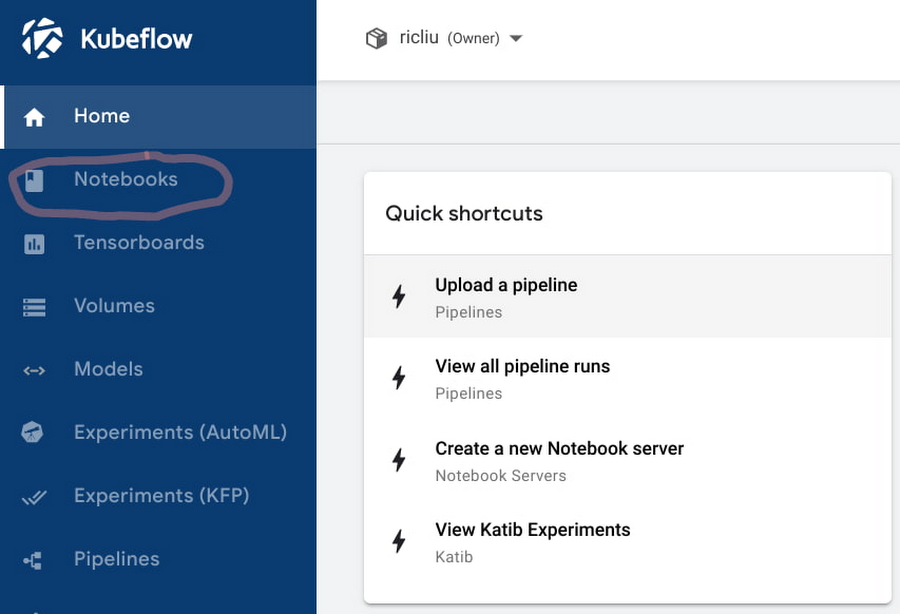
2. 单击“New Notebook”。
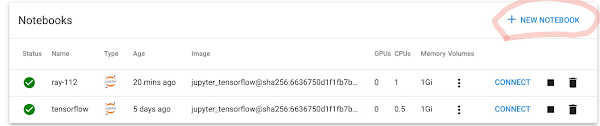
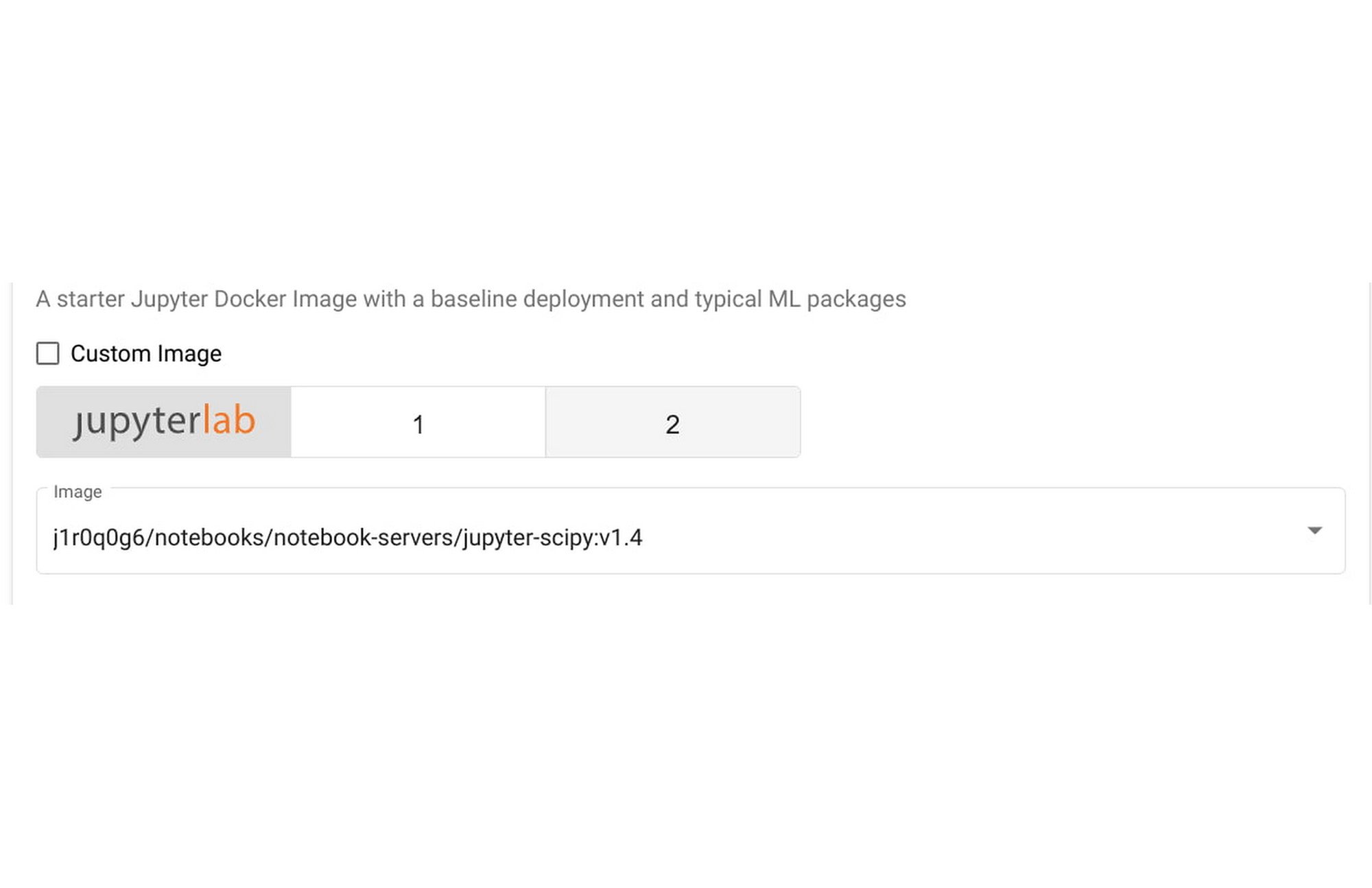
3. 在“Image”部分,单击“Custom Image”,然后输入您在上一步中构建的 Jupyter Notebook 容器镜像的路径。
4. 根据需要配置 Notebook 的资源要求。默认 Notebook 使用半个 CPU 和 1 G 内存。请注意,这些资源仅适用于笔记本会话,不适用于训练资源。随后,我们使用 Ray 在 GKE 上大规模编排资源。
5. 点击“LAUNCH”。
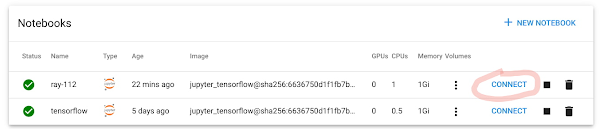
6. 笔记本完成部署后,单击“Connect”以启动新的 Notebook 会话。
7. 在笔记本中,单击“File”->“New”->“Terminal”打开终端。
8. 在终端中安装 Ray 1.13:
pip install ray==1.13 |
9. 现在,您已准备好使用此笔记本和上一节中刚刚部署的 Ray 集群来运行实际的 Ray 应用程序。我使用此处的规范 Ray 训练器示例制作了一个 .ipynb 文件。
10. 遍历笔记本中的单元格。连接到 Ray 集群的方式是:
ray.init("ray://example-cluster-head-svc:10001") |
这应该与您之前创建的服务端点匹配。如果您有多个不同的 Ray 集群,您只需在此处更改端点即可连接到不同的集群。
11. 接下来的几行将在集群上启动 Ray Trainer 进程:
trainer = Trainer(backend="tensorflow", num_workers=4) trainer.start() results = trainer.run(train_func_distributed) trainer.shutdown() |
请注意,这里我们指定了 4 个 worker,这与 Ray 集群的副本数量相匹配。如果我们更改这个数字,Ray 集群将根据资源需求自动扩展或缩小。
提供 ML 模型服务
在本节中,我们将了解如何为上一节刚刚训练的 ML 模型提供服务。
1. 使用同一笔记本,等待训练步骤完成。您应该会看到一些输出日志,其中包含我们训练过的模型的指标。
2. 运行下一个单元:
serve.start(detached=True, http_options={"host": "0.0.0.0"}) TFMnistModel.deploy(TRAINED_MODEL_PATH) |
这将开始使用我们之前创建的相同服务端点为我们刚刚训练的模型提供服务。
3. 要验证推理端点现在是否正常工作,我们可以创建一个新笔记本。您可以在这里使用这个。
4. 请注意,我们调用与之前相同的推理端点,但使用不同的端口:
resp = requests.get( "http://example-cluster-head-svc:8000/mnist", json={"array": np.random.randn(28 * 28).tolist()}) |
5. 您应该会在笔记本会话中看到显示的推理结果。
与他人共享 Ray Cluster
现在,您已经拥有一个带有交互式笔记本和 Ray 集群的功能工作区,让我们邀请其他人进行协作。
1. 在 Cloud Console 上,在此处授予用户最小集群访问权限。
2. 在 Kubeflow 仪表板的左侧面板中,选择“Manage Contributors”。
3. 在“Contributors to your namespace”部分中,输入您要授予访问权限的用户的电子邮件地址。按回车键。
4. 该用户现在可以选择您的命名空间并访问您的笔记本,包括您的 Ray 集群。
使用 Ray Dashboard
最后,您还可以使用 Istio 虚拟服务调出 Ray Dashboard。使用以下步骤,您可以在 Kubeflow 中央仪表板控制台内打开仪表板 UI:
1. 创建 Istio Virtual Service 配置文件:
apiVersion: networking.istio.io/v1alpha3 kind: VirtualService metadata: name: example-cluster-virtual-service Namespace: kubeflow spec: gateways: - kubeflow-gateway hosts: - '*' http: - match: - uri: prefix: /example-cluster/ rewrite: uri: / route: - destination: host: example-cluster-head-svc.$(USER_NAMESPACE).svc.local port: number: 8265 |
将 $(USER_NAMESPACE) 替换为您的用户配置文件的命名空间。将其保存到本地文件。
2. 部署 virtual service:
kubectl apply -f virtual_service.yaml |
3. 在您的浏览器窗口中,导航到 https://<host>/_/example-cluster/。Ray dashboard 应当显示在窗口中:
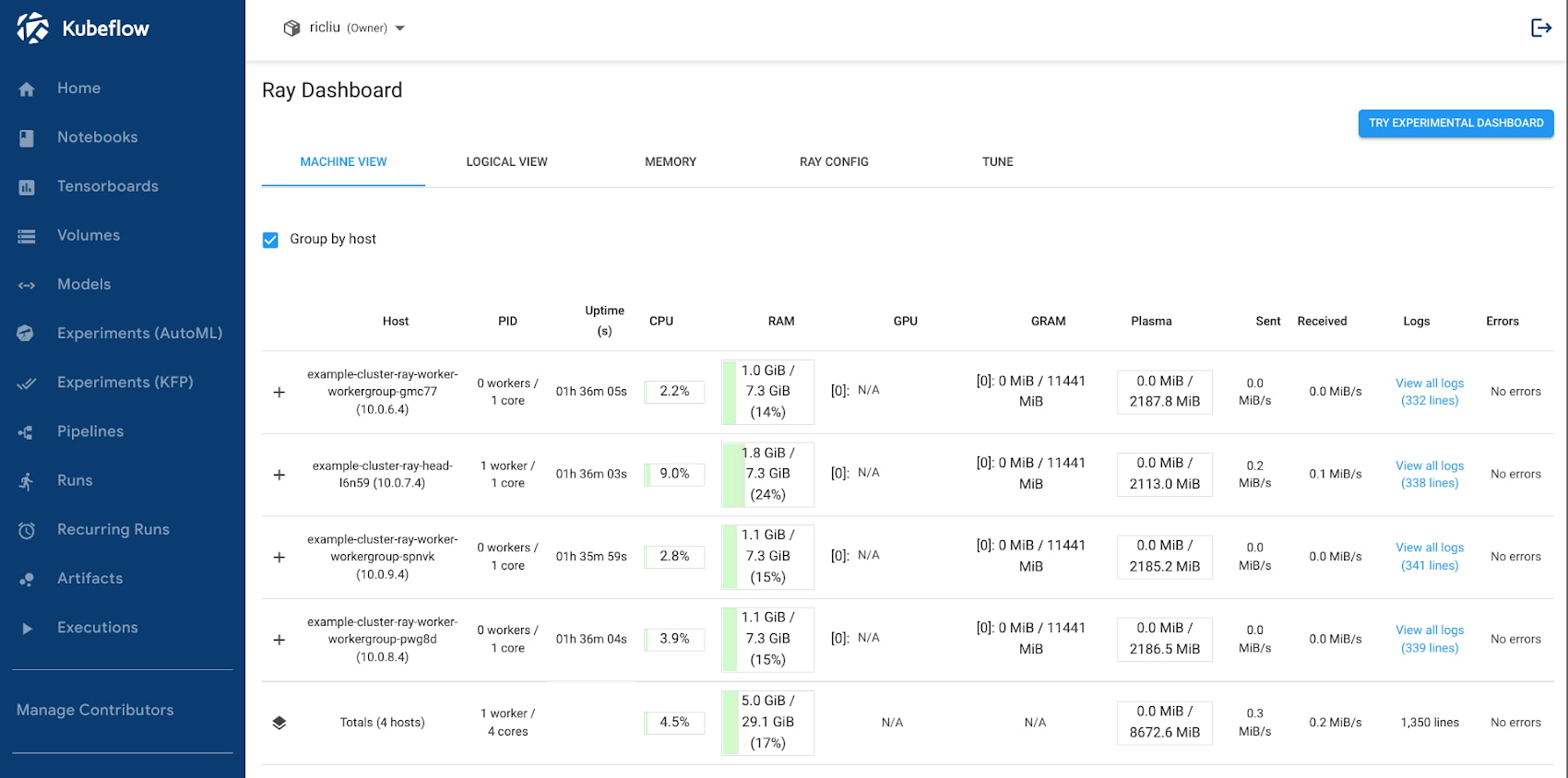
总结
让我们花一点时间来回顾一下我们所做过的事情。在本文中,我们演示了如何在同一个 GCP Kubernetes 集群中部署两个流行的 ML 框架 Kubeflow 和 Ray。该设置还利用 IAP(身份感知代理)等 GCP 功能进行用户身份验证,从而保护您的应用程序,同时简化云管理员的体验。最终得到的结果是一个集成良好且可投入生产的系统,它整合了每个系统所提供的有用功能:
使用 Ray API 编排分布式计算工作负载;
使用 Kubeflow 进行多用户隔离;
使用 Kubeflow 笔记本的交互式笔记本环境;
使用 Google Kubernetes Engine 进行集群自动扩缩和自动配置
我们仅触及到了可能性的表面,您还可以从这里进行扩展:
与其他 MLOps 产品集成,例如顶点模型监控;
通过 Artifact Repository,更快、更安全的容器镜像存储和管理;
使用 GCSFuse 对非结构化数据进行高吞吐量存储;
通过 NCCL Fast Socket 提高集体通信的网络吞吐量。
我们期待您的 ML 平台的发展以及您的团队如何通过 ML 进行创新。请留意未来有关如何启用其他 ML 平台功能的文章。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们