首页 > 资源 > 文章详情
利用 GKE 上的 Cloud TPU v5e 助力大规模经济高效的 AI 推理
Google Cloud TPU v5e 是一款经济高效的专用的 AI 加速器,性能上能满足大规模模型训练和推理。借助运行于 Google Kubernetes Engine(GKE)- 业内领先的 Kubernetes 服务的 Cloud TPU,客户可经济高效地使用同类最佳的训练和推理功能,协调 AI 工作负载。长期以来,GKE 一直都是支持 GPU 处理 AI 工作负载的领导者,而现在我们将扩大支持范围,将 TPU v5e 纳入大规模推理功能。
MLPerf™ 3.1 结果
正如我们在 9 月份宣布的那样,Google Cloud 提交了 MLPerf™ Inference 3.1 基准测试结果,与 TPU v4 相比,每美元性能提高了 2.7 倍。
我们提交的 MLPerf™ Inference 3.1 结果展示了使用高性能推理系统 Saxml 和 Google AI 编译器 XLA 运行 60 亿参数的 GPT-J LLM 基准测试情况。其中所使用的一些关键优化包括:
XLA 优化和 Transformer 运算符融合。
采用 INT8 精度的训练后权重量化
使用 GSPMD 在 2x2 TPU 节点池拓扑上进行高性能分片(sharding)
在 Saxml 中分批执行前缀计算和解码
Saxml 中的动态批处理
在 GKE 集群上运行 Cloud TPU v5e 时,我们实现了相同性能,充分表明 GKE 上的 Cloud TPU 可实现 GKE 的可扩展性、编排和运行优势,同时保持 TPU 的性价比。
利用 GKE 和 TPU 实现成本效益最大化
在构建生产就绪、高度可扩展和容错的托管应用程序时,GKE 可降低在 TPU 上进行推理的总拥有成本(TCO),从而带来更多价值:
使用 Kubernetes 标准平台管理和部署 AI 工作负载。
通过自动缩放将成本降至最低,确保根据工作负载需求自动调节资源。GKE 可使用自动缩放功能,根据流量自动扩充或缩减 TPU 节点池,从而增加成本效益并提高推理的自动化程度。
为工作负载配置所需要的必要计算资源:可利用 GKE 的节点自动预配功能,根据 TPU 工作负载需求自动配置 TPU 节点池。
通过 GKE 上的内置 TPU 虚拟机节点池健康监测确保应用程序的高可用性。如果 TPU 节点变得不可用,GKE 将执行节点自动修复,避免发生中断。
通过 GKE 对维护事件的主动处理和平稳地终止工作负载,最大限度减少因更新和硬件故障而导致的中断。
利用 GKE 成熟可靠的指标和日志功能,全面了解您的 TPU 应用程序。
GKE TPU 推理参考架构
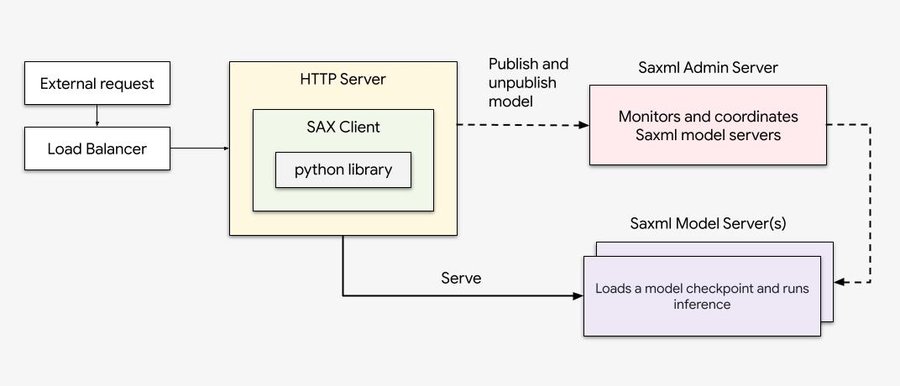
为了利用上述所有优势,我们创建了概念验证,使用 GPT-J 6B LLM 模型和单主机 Saxml 模型服务器演示 TPU 推理。
下图:Saxml 工作流
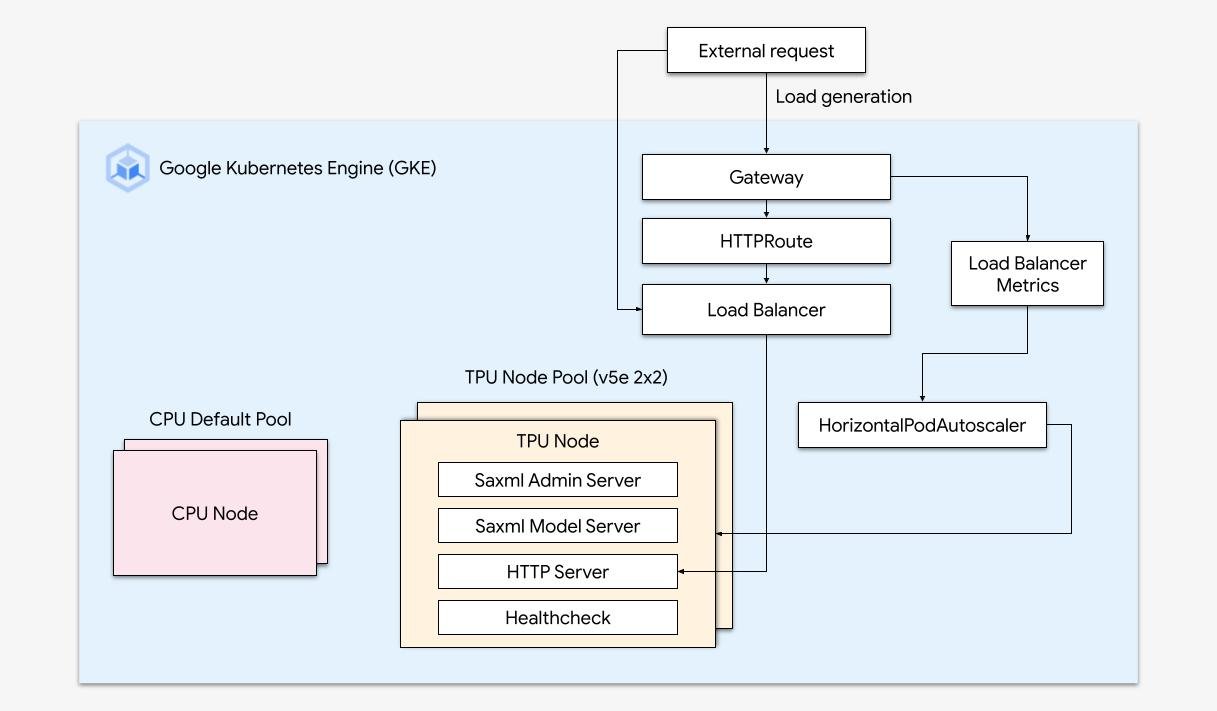
我们创建了一个拥有以下架构的 GKE 集群:
我们创建了一个带有 TPU v5e(2x2)节点池的 GKE 集群。
我们启用了 Gateway API,其能够暴露不同的 HTTP 端点,并提供健康检查。
我们开发了一个简单的 HTTP 服务器,将其作为 Saxml 前端。该服务器将终端用户的请求代理至 Saxml。
我们开发了一套 Kubernetes 部署,服务于两个容器:Saxml 部署和 HTTP 服务器。这确保了 HTTP 服务器以随航(sidecar)方式运行,并与 Saxml 按比例缩放。
我们为部署配置了必要的 Gateway API 配置,包括 HTTP 路由、健康检查和基于 k8s 负载均衡器的后备服务。
最后,我们添加了 HorizontalPodAutoscaler,它可以根据负载均衡器的流量,动态地缩放部署的副本数量。
在通过使用 GKE 实施 TPU v5e 时,该参考架构演示了如何让大规模 AI 推理实现最佳性价比。如欲了解集群的运行情况,请观看以下演示!
演示
关于所述参考架构的更多示例和详细信息,请参见我们的 Github!
欢迎尝试一下,如果您对 GKE 上的 Saxml 有任何疑问,请留下评论。我们期待您的反馈!
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们