首页 > 资源 > 文章详情
凭借全球最快训练超级计算机 , Google 在 MLPerf 测试中打破 AI 性能记录

ML 模型的实际训练速度,已经成为决定前所未有的新产品能否实现、服务与研究突破能否达成的关键性因素,自然也成为研究与工程团队最关注的一项核心指标。Google近期亦推出一系列 ML 提升方案,包括实用度更高的搜索结果以及一套能够翻译上百种不同语言的 ML 模型。
在作为业界标准的 MLPerf 基准测试竞赛当中,Google又打造出全世界最快的 ML 训练超级计算机。通过这台超级计算机以及我们最新的张量处理单元(TPU)芯片,Google成功在八项 MLPerf 基准测试的六项中创下新的性能记录。
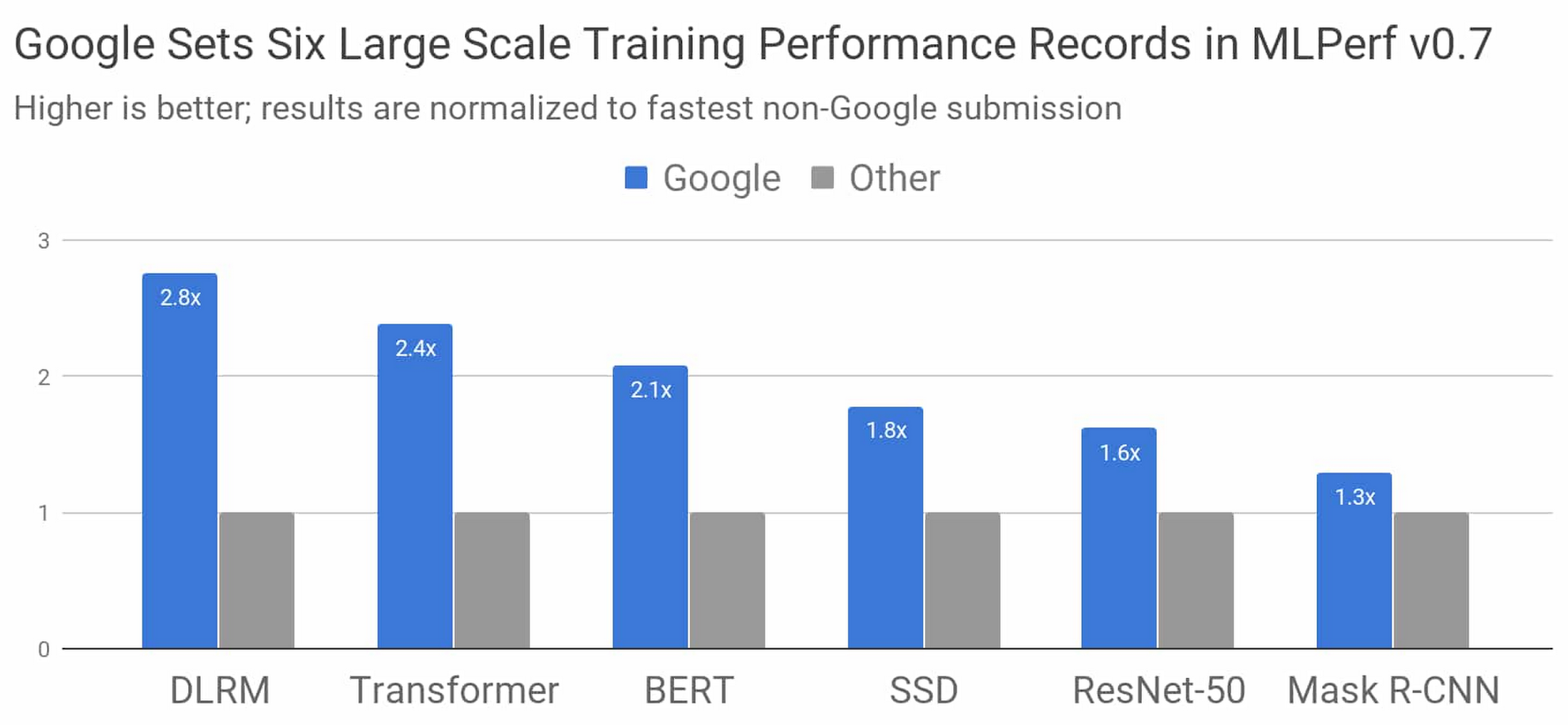
图一:与其他参与本次竞赛的提交方案相比,Google成绩最好的 MLPerf Training v-.7 Research 提交方案将速度水平提升至新的高度。在此竞赛中,无论配合何等系统规模,其总训练时间都将进行标准化比较,且赛程要求的系统规模介于8芯片到4096芯片之间。得分越高,代表成绩越好。1
我们使用TensorFlow, JAX以及Lingvo中的 ML 模型实现了这一堪称惊艳的结果。在短短30秒之内,系统即完成了八套模型中四套模型的训练作业。要对这一结果建立起直观印象,大家不妨参考2015年时的成绩——当时配合最先进的硬件加速器,单一模型的训练花掉了三个多星期。Google最新的TPU超级计算机,显然得以在五年之后将同一模型的训练速度提高近五个数量级。
在本文中,我们将着眼于本次竞赛中的几个重要细节,探讨我们的提交方案为何能取得如此出色的成绩,以及这一切对于您的实际模型训练速度又有何意义。
MLPerf模型简介
MLPerf 模型代表着行业及学术界所通行的顶尖 ML 类工作负载。参考上图,可以看到各MLPerf模型的详细信息:
· DLRM代表排名及推荐类模型,这类模型对媒体、旅游乃至电子商务等行业中的在线业务至关重要。
· Transformer是近期包括BERT在内的自然语言处理发展浪潮的前提与基础。
· BERT模型使Google Search迎来了“过去五年中最大的一次飞跃”。
· ResNet-50是一套广泛应用于图像分类领域的模型。
· SSD是一套对象检测模型,出色的轻量化设计使其足以运行在移动设备之上。
· Mask R-CNN是一套应用广泛的图像分割模型,可用于自主导航、医学成像以及众多其他领域(您可在Colab中亲自体验)。
除了规模庞大的行业顶尖方案之外,Google还使用Google Cloud Platform上的企业级TensorFlow服务提交MLPerf成果。
全球速度最快的 ML 训练超级计算机
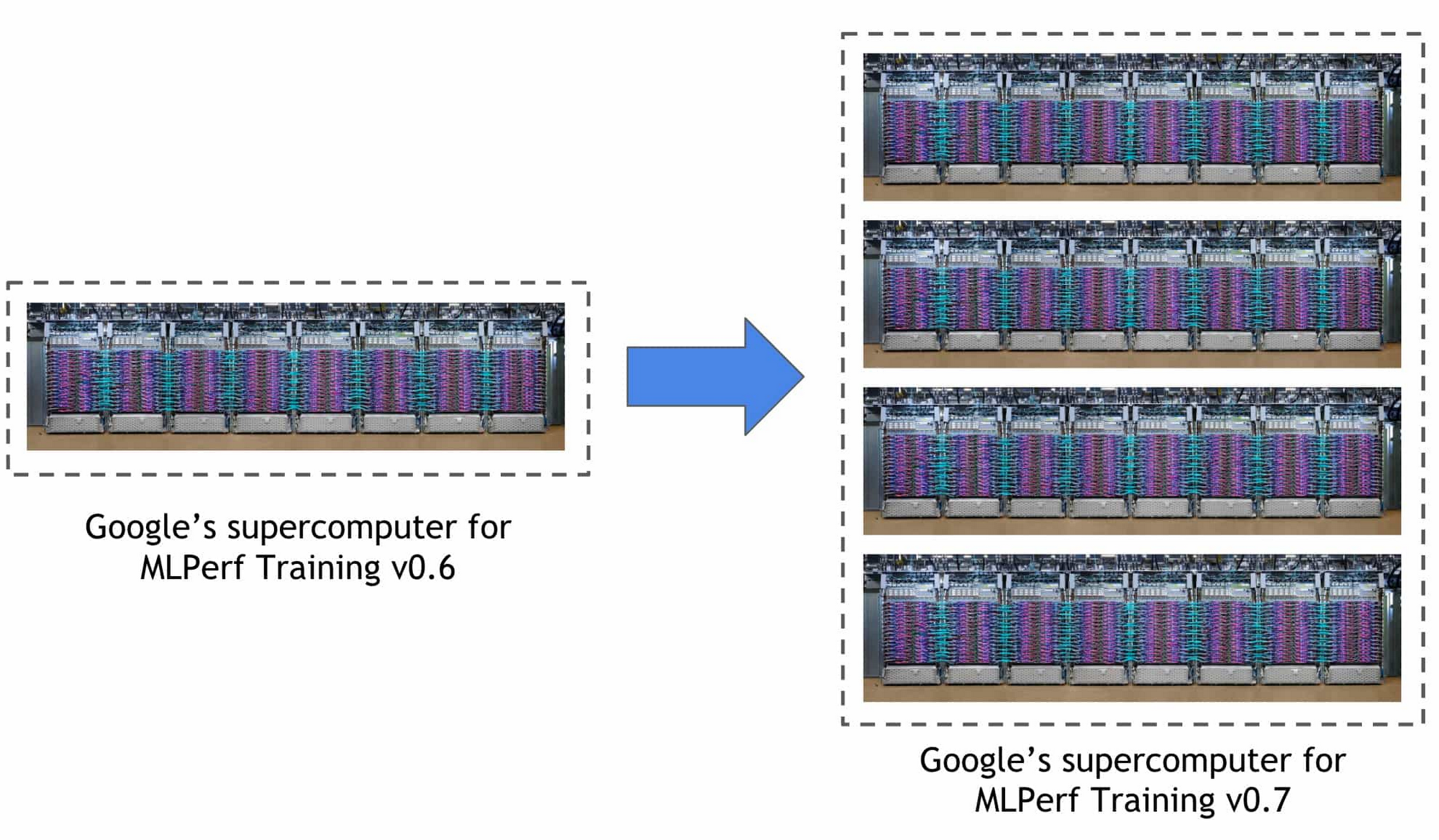
Google在本次 MLPerf 训练竞赛中使用的超级计算机,在规模上达到上届竞赛中所使用的Cloud TPU v3 Pod的四倍(上代系统在上届竞赛中创下三项性能记录)。这套新系统包含4096块TPU v3芯片以及成百上千台CPU主机设备,所有计算单元皆通过超快速、超大规模定制化互连体系实现对接。这套系统可实现超过430千万亿次(PFLOPs)的峰值计算性能。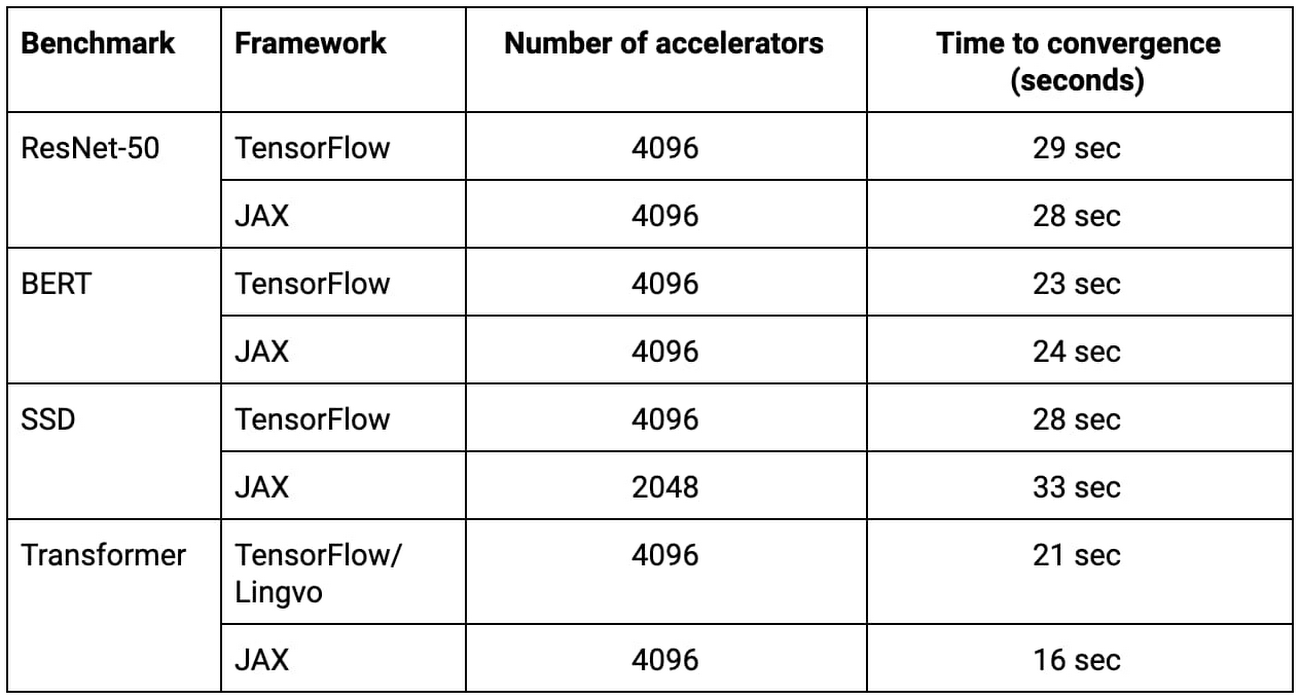
表一:此次提交的全部MLPerf模型训练方案皆在Google全新 ML 超级计算机上从零开始训练完成,且整个训练周期不超过33秒。2
使用TensorFlow, JAX, Lingvo以及XLA进行大规模训练
要使用数千块TPU芯片训练如此复杂的 ML 模型,自然要求我们在TensorFlow、JAX、Lingvo以及XLA当中结合多种算法技术与优化手段。这里首先介绍一点背景信息,XLA是用于支持本次全部Google MLPerf提交方案的基础编译器技术;TensorFlow是Google打造的端到端开源 ML 框架;Lingvo是一套使用TensorFlow构建而成的序列模型高级框架;JAX则是一套以研究为核心用途的组合式函数转换框架。之所以能够在本届竞赛中取得破记录成绩,应当归功于Google提交方案中采用的模型并行处理、大规模批次规范化、高效计算图启动以及基于树的权重初始化等方法。
上表中列出的所有TensorFlow、JAX以及Lingvo提交方案(包括ResNet-50、BERT、SSD以及Tranformer的对应实现)在2048或4096 TPU芯片配置下完成训练,且各项训练作业皆在33秒内实现。
TPU v4: Google的第四代张量处理单元芯片
Google的第四代TPU ASIC能够将矩阵乘法TFLOP提升至TPU v3的两倍以上,同时显著增加了内存带宽并改进了互连技术。Google在TPU v4 MLPerf提交方案中充分利用到这些新的硬件功能,同时发挥了编译器与建模层面的补充性优势。从结果来看,与上一届 MLPerf 训练竞赛相比,新一代TPU v4在同等规模下较TPU v3的平均性能增量高达2.7倍。我们后续还将发布更多关于TPU v4的详细信息,敬请期待!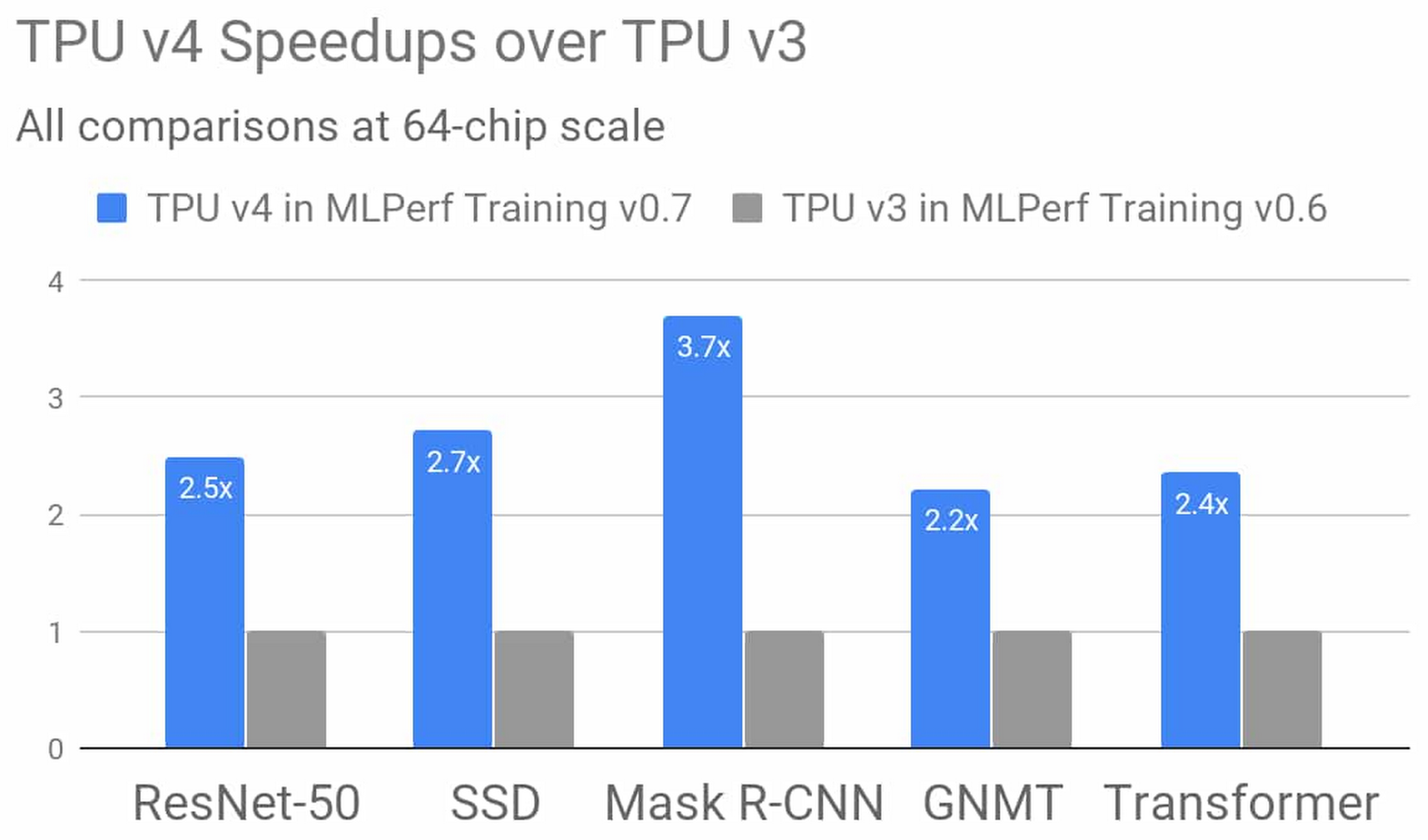
图二:在Google MLPerf Training v0.7 Research提交方案中,TPU v4将平均训练性能提升至TPU v3的2.7倍(比较对象为论文中描述的TPU v3的Google MLPerf Training v0.6 Available提交结果,且同样使用64芯片规模)。这一优异成绩,归功于TPU v4的硬件创新与软件改进。3
快速发展,持续发展
Google的MLPerf Training v0.7提交方案再次证明,我们一直致力于推动 ML 的规模化研究与工程探索,同时也通过各类开源软件、Google产品以及Google Cloud服务将发展成果回馈给各位用户。
现在,您已经可以通过Google Cloud直接使用Google的第二代与第三代TPU超级计算机。请访问Cloud TPU主页与说明文档以了解更多详细信息。Cloud TPU支持TensorFlow 与 PyTorch,我们还提供JAX Cloud TPU 预览版供您体验。
1.所有结果由2020年7月29日从www.mlperf.org网站检索得出。MLPerf名称与徽标为注册商标,关于更多详细信息,请参阅www.mlperf.org网站。图表比较结果: 0.7-70 v. 0.7-17, 0.7-66 v. 0.7-31, 0.7-68 v. 0.7-39, 0.7-68 v. 0.7-34, 0.7-66 v. 0.7-38, 0.7-67 v. 0.7-29.
2. 所有结果由2020年7月29日从www.mlperf.org网站检索得出。MLPerf名称与徽标为注册商标,关于更多详细信息,请参阅www.mlperf.org网站。图表比较结果: 0.7-68, 0.7-66, 0.7-68, 0.7-66, 0.7-68, 0.7-65, 0.7-68, 0.7-66.
3. 所有结果由2020年7月29日从www.mlperf.org网站检索得出。MLPerf名称与徽标为注册商标,关于更多详细信息,请参阅www.mlperf.org网站。图表比较结果: 0.7-70 v. 0.6-2.
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们