首页 > 资源 > 文章详情
借助 Cloud Spanner 的 Vertex AI 集成轻松将 ML 模型集成到应用程序中
Cloud Spanner 是一种完全托管的关系数据库,可在任何规模下提供行业领先的一致性和可用性。金融服务、零售和游戏等行业中各种规模的组织都依靠 Spanner 来运行其任务关键型应用程序,但高效地运行业务线应用程序通常是不够的。他们希望通过利用 ML 模型而不是依赖手动操作,以可扩展的方式更快地对业务或客户事件做出反应。欺诈检测、算法交易和机器人检测等任务对时间很敏感,并且可能具有不可预测的负载。Spanner 与 Google Cloud 的 ML 平台 Vertex AI 集成,让用户可以在 Spanner 中使用简单的 SQL 查询来利用 Vertex AI 中的 ML 模型。与 Vertex AI 的内置集成(现已提供预览版)统一了操作数据库和 AI,从而更轻松地使用已发布的 ML 模型并更快地构建 AI 驱动的应用程序。
应用程序开发人员通常只有有限的精力来将 ML 服务与应用程序集成,因为这样做需要学习曲线和长期维护开销。 这些开发人员必须在他们的应用程序中创建一个单独的模块,或者一个单独的应用程序/服务,以便与 Vertex AI 等 ML 服务进行交互。
从概念上讲,该模块会将数据发送到 Vertex AI 的预测模型,并将结果传递给,需要根据此结果做出决策的应用程序。这样的情况则会导致应用程序的扩展、决策制定的延迟增加以及需要维护的移动部分增加。相比之下,通过 Spanner Vertex AI 集成,开发人员可以轻松访问数据科学家构建的模型,并使用熟悉的 SQL 将它们应用于数据库事务。这类似于 BigQuery ML 原生支持 ML 的方式,使用户更容易在应用程序中利用 ML 模型,但有一个重要的区别:Spanner 的 Vertex AI 集成允许对实时事务进行预测,而 BigQuery ML 分析已经完成的事务存储在 BigQuery 中的数据。
Spanner 的 Vertex AI 集成,对于欺诈检测或“有毒”玩家检测等用例非常重要,在这些用例中,客户希望在交易或活动期间做出尽可能最佳的决策,而不是后续检测到错误的决策。这种与 Spanner 的直接集成的方式,降低了将 ML 集成到应用程序的进入门槛,提供了更低的延迟和更短的事务锁持有时间,使其不易受到锁争用的影响,这对于繁忙的事务系统来说是一个重要的好处。
Vertex AI 集成入门
在此版本的 Vertex AI 集成中,我们可以轻松使用已在 Vertex AI 中发布的任何现有模型。让我们通过一个示例来了解一家游戏公司如何使用 Vertex AI 与 Spanner 的集成来保护其用户和公司免受“有毒”玩家的侵害。
用例示例:“有毒”玩家检测
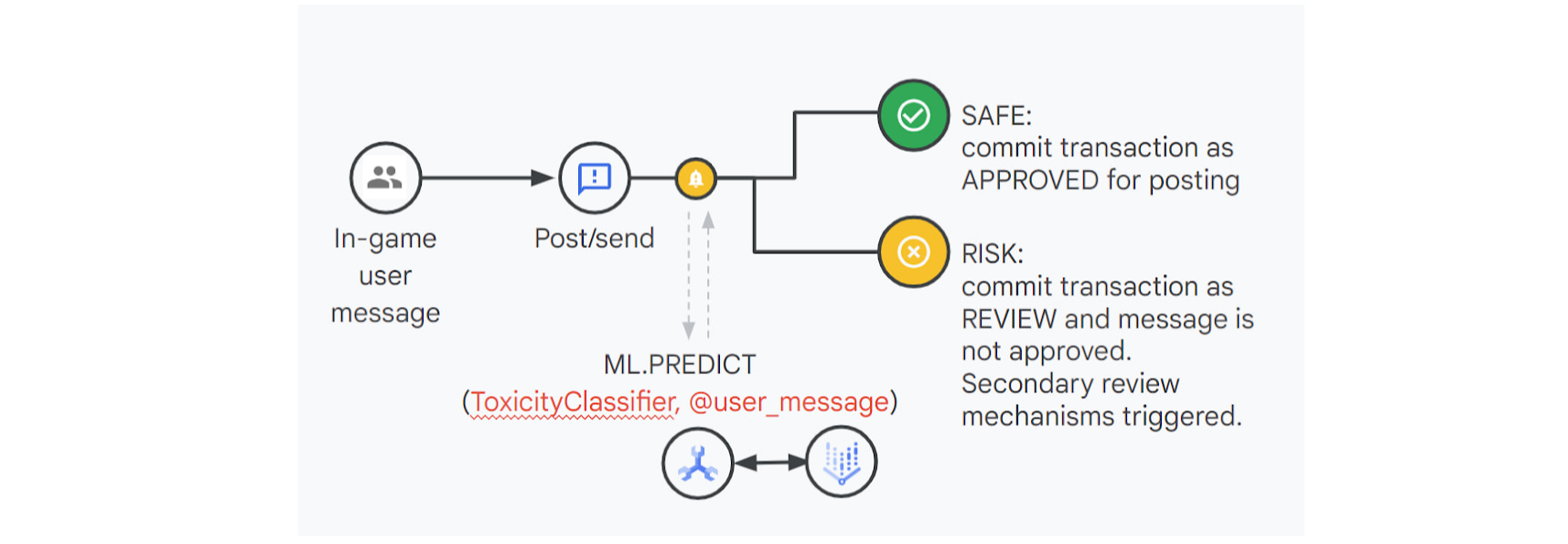
以 Cymbal Entertainment 为例,这是一家假设的游戏和社交媒体公司,它利用 Spanner 存储所有用户有关活动的信息,包括论坛中的聊天和评论。他们希望他们的系统在有害行为发生后立即自动触发对潜在用户不当行为的调查,尤其是有害的聊天/评论行为。在游戏内聊天/消息传递等情况下,他们希望在玩家提交有害内容时检测有害内容。他们必须评估被举报用户评论的恶意程度,并决定是否标记评论、暂停用户帐户或采取任何其他合理措施。
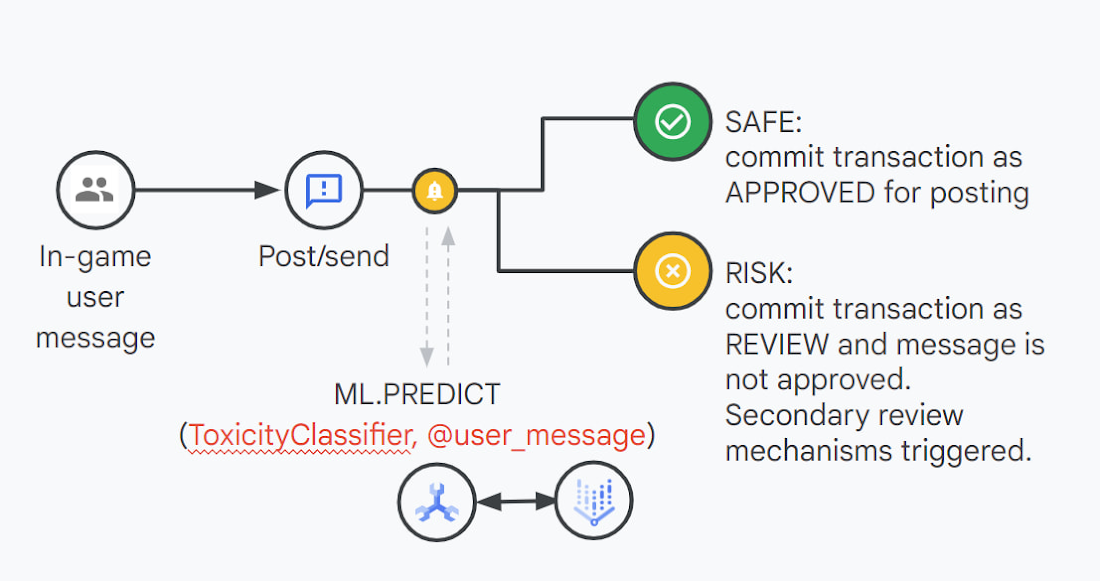
这项检测几乎必须要立即完成,否则可能会导致争吵,或更糟糕的结果,如玩家可能会完全放弃该平台。Cymbal Entertainment 因其对在线欺凌的零容忍政策而自豪,其数百万不同的用户共同见证了它的成功。不良用户可能会损害他们来之不易的声誉,并在一夜之间影响他们的业务。Cymbal 社区的规模及其用户的 24x7 活跃水平使得任何依赖人类来防止此类事件的解决方案都不可行。
为 Spanner 准备模型
为了使聊天或评论毒性评估过程自动化,Cymbal Entertainment 使用了 ML。他们使用系统中现有的数据或公开可用的数据集(如来自 Kaggle 的 Toxicity Comment Classification)按照 Vertex AI 文本分类指南训练模型。一旦模型被训练并部署到 Vertex AI 端点,它就可以在 Spanner 中注册:
CREATE MODEL ToxicityClassifier
INPUT (content STRING(MAX))
OUTPUT (displayNames ARRAY<STRING(MAX)>, confidences ARRAY<FLOAT64>)
REMOTE OPTIONS(
endpoint = "//aiplatform.googleapis.com/projects/$PROJECT_ID/locations/$LOCATION/endpoints/$ENDPOINT_ID"
);
ToxicityClassifier 模型将评论文本作为输入并输出两个数组:display names 和 confidences。前者包含在训练数据集中看到的所有标签。后者表示位置对应标签的置信度分数。在以下示例中,结果将指示有毒评论:
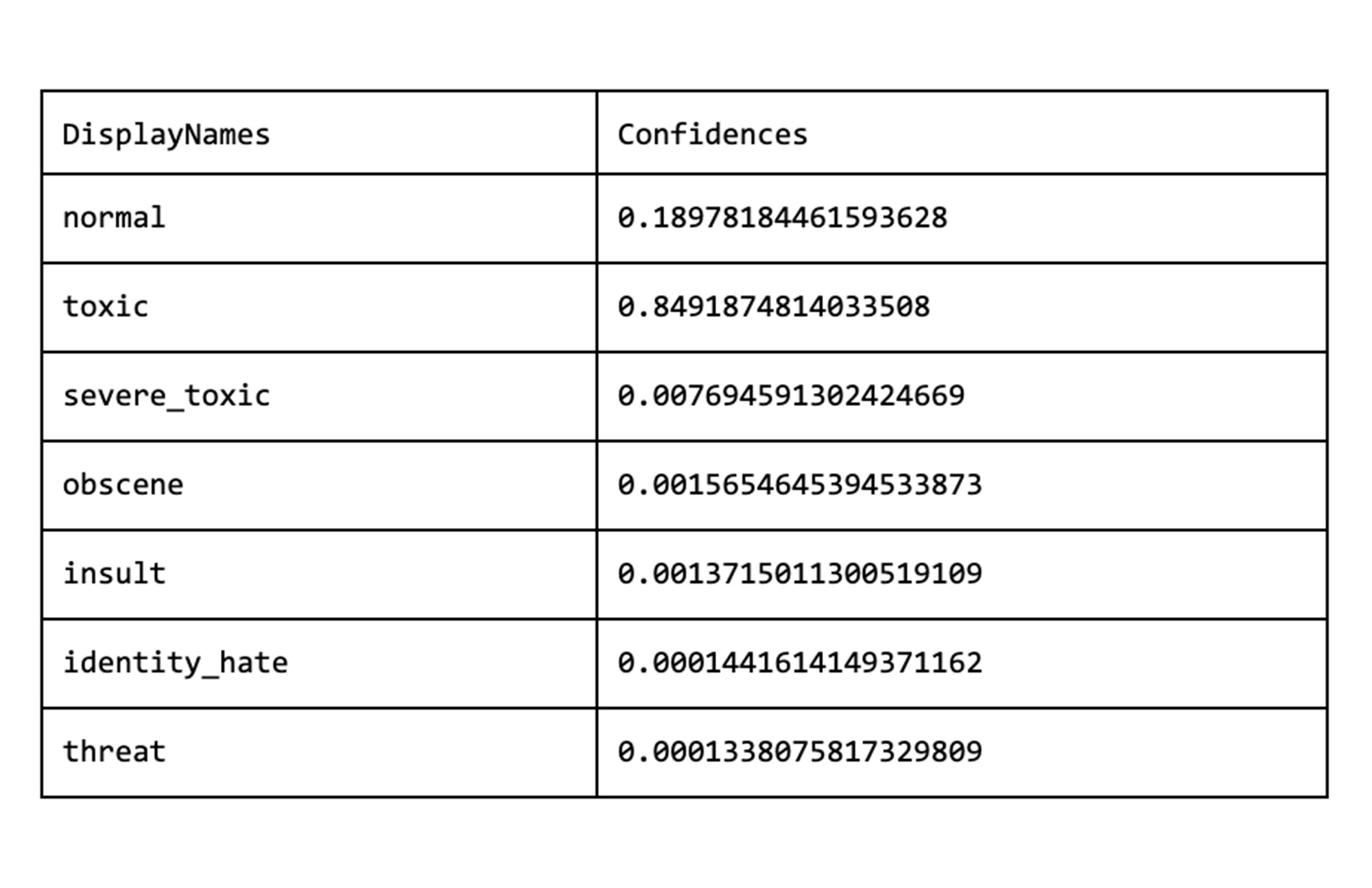
在线“毒性”预测
在 Comments 表中插入评论时,他们使用 Toxici 1.5tyClassifier 模型计算毒性评级集。根据他们的公司政策,平台不允许发布包含身份攻击、严重毒性或威胁的评论,需要通过将评论记录的 is_banned 标志设置为 true 来自动禁止。其他包含高毒性评级的评论可以标记为可疑并重新定向以进行进一步调查。可以使用以下 SQL 语句执行所描述的整个操作:
INSERT INTO Comments (user_id, comment_id, comment_text, is_banned, is_suspicious)
SELECT
user_id,
comment_id,
comment_text,
(severe_toxic OR threat OR identity_hate) AS is_banned,
(toxic OR obscene OR insult) AS is_suspicious
FROM
(SELECT
user_id,
comment_id,
content AS comment_text,
confidences[OFFSET(0)] > 0.5 AS normal,
confidences[OFFSET(1)] > 0.5 AS toxic,
confidences[OFFSET(2)] > 0.5 AS severe_toxic,
confidences[OFFSET(3)] > 0.5 AS obscene,
confidences[OFFSET(4)] > 0.5 AS insult,
confidences[OFFSET(5)] > 0.5 AS identity_hate,
confidences[OFFSET(6)] > 0.5 AS threat
FROM
ML.PREDICT(MODEL ToxicityClassifier,
(
SELECT
@user_id AS user_id,
@comment_id AS comment_id,
@comment_text AS content
)));
这种方法除了简单和更好的整体查询性能外,数据、决策和推理都在同一步骤中存储在数据库中。使用外部函数完成相同的操作将需要多个步骤和数据库事务。
如您所见(并亲自尝试之后),使用 ML 功能丰富 Cymbal Entertainment 应用程序所需的所有工作都是通过向其现有代码添加一些 SQL 命令来完成的。订阅和支付处理团队还可以以同样的方式轻松添加用于检测支付欺诈的 ML 功能。
可用性和定价
Vertex AI 与 Spanner 的集成目前处于预览阶段,可在所有区域使用 Spanner。使用此功能,Spanner 不收取额外费用。客户将需要访问 Vertex AI 模型,并根据使用类型遵循 Vertex AI 定价。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们