首页 > 资源 > 文章详情
使用 Google Cloud Log Analytics 进行日志分析
Google Cloud 日志服务可以自动接收和存储各种云服务比如虚机、对象存储、负载均衡、容器服务等的日志并提供方便的索引查询功能。近日,Google Cloud 日志服务推出了新的日志分析 (Log Analytics) 服务,方便用户对日志数据进行高效的 SQL 查询,可以更加方便和高效地挖掘日志数据的价值。
使用日志分析,您可以运行查询来分析日志数据以生成有用的数据洞见。例如,假设您正在排查问题,并且希望了解一段时间内发送到特定网址的 HTTP 请求的平均延迟时间。日志存储桶升级到使用日志分析后,您可以使用 SQL 查询查询存储在日志存储桶中的日志。通过对日志进行分组和汇总,您可以深入了解日志数据,这有助于减少问题排查所花的时间。
借助日志分析,您还可以使用 BigQuery 查询数据。例如,假设您希望将日志中的网址与已知恶意网址的公开数据集进行比较。要执行此分析,您必须使用存储在 Logging 之外的数据来分析日志。在升级存储桶以使用日志分析,然后创建关联的数据集后,您可以查看日志存储桶中存储的数据。通过使用链接的数据集,您可以将日志数据与 BigQuery 可访问的其他数据联接起来。例如,此数据可以是存储已知恶意网址的数据集,也可以是通过 Looker 和数据洞察等商业智能工具生成的数据。
本文主要基于实例介绍如何打开并使用 Log Analytics 日志分析服务。
升级日志服务存储桶
默认日志桶没有开通日志分析服务,需要在控制台手动升级。升级操作没有费用。
首先在控制台菜单进入日志服务,并选择导航栏中的 Logs Storage 菜单页。
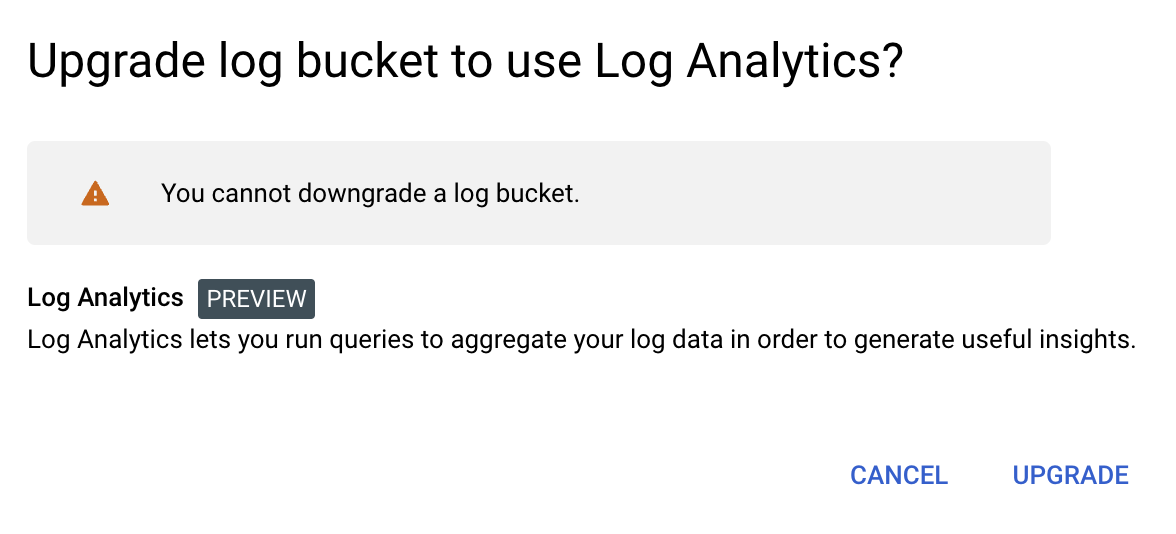
在列出的日志存储桶中,选择要升级的日志桶,并点击 UPGRADE 按钮。

在确认页面点击 UPGRADE。
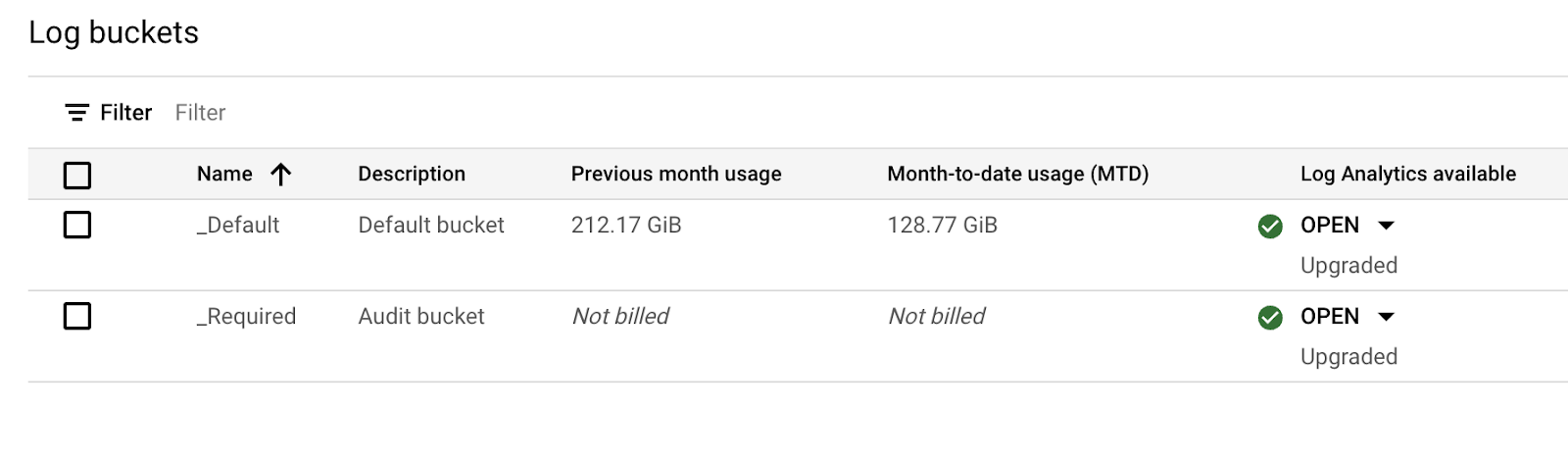
点击完成后等待大概3-5分钟,升级可以完成。完成后可以看到 Log Analytics 状态为 OPEN,并且可以从其下拉菜单中点击进入对应的 Log Analytics 查询界面。
 使用 Log Analytics 进行日志分析
使用 Log Analytics 进行日志分析
进入 Log Analytics 页面后,可以看到日志桶的列表。每个日志桶里,会有一个或多个日志表。比如下面的_Default 日志桶里,有_AllLogs 表和_Default 表。选中一个表,可以在右侧看到这个表的 Schema 表结构,了解有哪些字段,每个字段是什么数据类型。其中有一些字段是嵌入式字段,可以展开为下一级细分字段。这个表结构与日志桶里日志的 JSON 结构是相对应的。
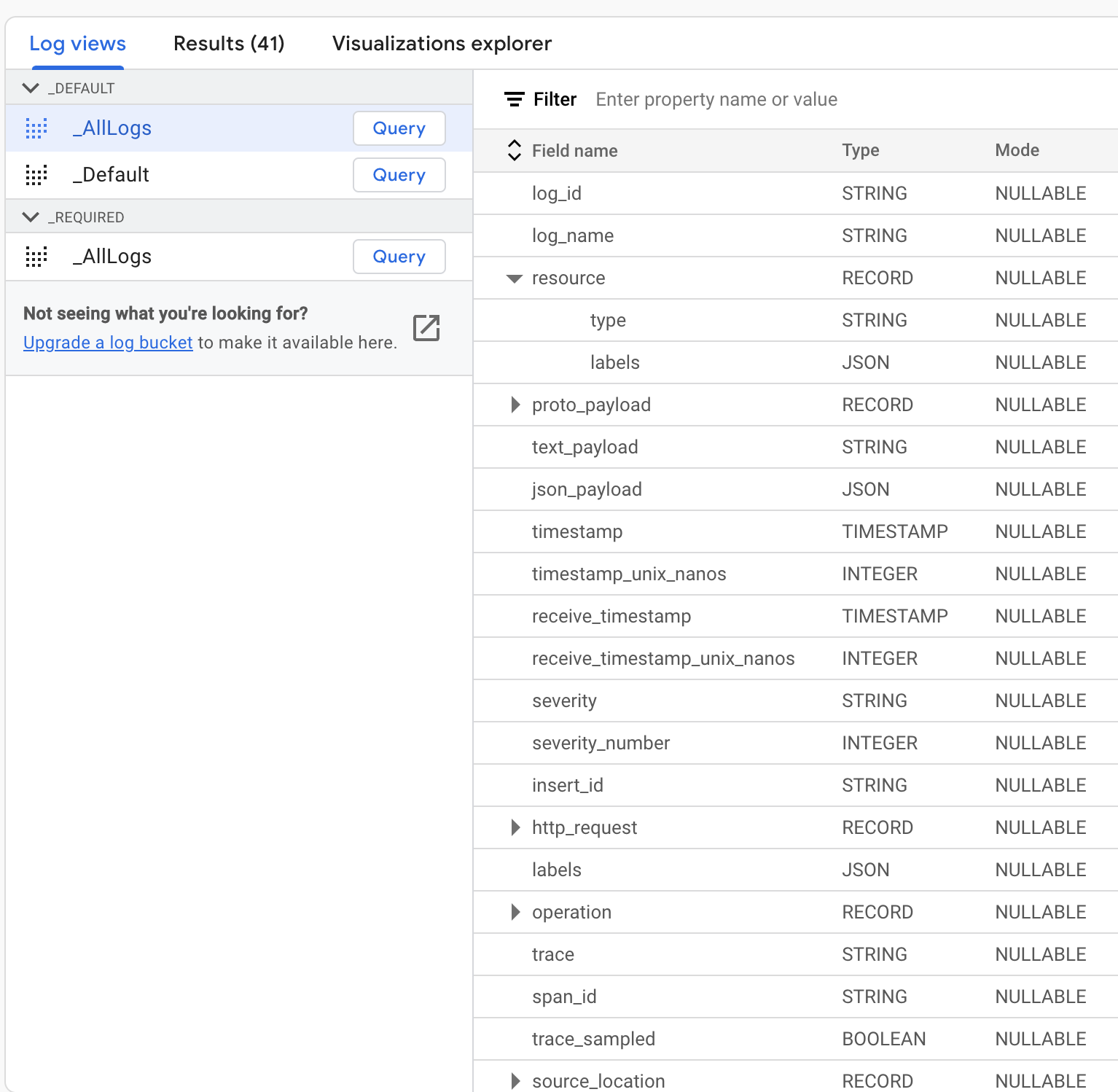
在 Log Analytics 页面的上方,是 SQL 查询编辑框。
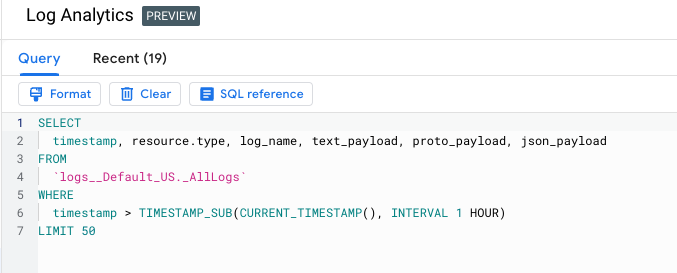
下面,我们通过一些示例来演示如何使用 SQL 对日志进行分析和统计。
请注意,Log Analytics 只能查询到日志存储桶升级完成后新增到桶里的日志,之前的日志不能用 SQL 查询,而只能在日志浏览器界面用查询表达式查询。
示例一 日志按类型统计数量
下面查询,将过去一小时内的 GKE 日志中的报错日志按照集群名字来分组统计并排序。
SELECT
JSON_VALUE(resource.labels.cluster_name) AS Cluster_Name, COUNT(*) AS Error_Total
FROM
`logs__Default_US._AllLogs`
WHERE
timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 HOUR)
AND resource.type='k8s_container'
AND severity='ERROR'
GROUP BY 1
ORDER BY 2 DESC
LIMIT 50

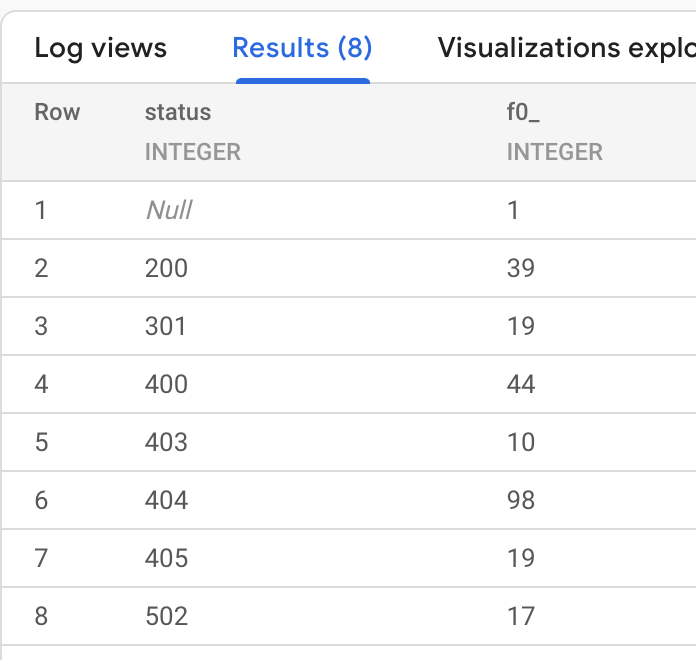
示例二 访问日志按状态码分组统计
下面查询,将一个时间段内的 HTTP 负载均衡访问日志按照返回状态码进行分组统计并排序。
SELECT
http_request.status, COUNT(*)
FROM
`logs__Default_US._AllLogs`
WHERE
timestamp >= TIMESTAMP("2022-09-19 15:00:00", "Asia/Shanghai")
AND timestamp <= TIMESTAMP("2022-09-19 17:00:00", "Asia/Shanghai")
AND resource.type = 'http_load_balancer'
AND http_request IS NOT NULL
GROUP BY 1
ORDER BY 1
LIMIT 50
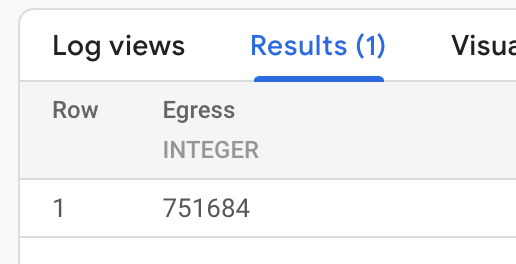
示例三 根据访问日志统计出向流量
下面查询,将一个时间段内所有 HTTP 负载均衡访问日志的响应字节数进行统计。
SELECT
SUM(http_request.response_size) AS Egress
FROM
`logs__Default_US._AllLogs`
WHERE
timestamp >= TIMESTAMP("2022-09-19 15:00:00", "Asia/Shanghai")
AND timestamp <= TIMESTAMP("2022-09-19 17:00:00", "Asia/Shanghai")
AND resource.type = 'http_load_balancer'
AND http_request IS NOT NULL
LIMIT 50
使用 BigQuery 分析日志桶里的日志
如果有需要对日志桶里的数据做深入的 SQL 分析,并且联合查询 BigQuery 中的其它表,比如关于业务或者用户的维度表,可以基于日志存储桶创建 BigQuery 的链接数据集 Linked Dataset,之后再在 BigQuery 的查询界面或者 API 来查询分析日志。创建链接数据集并不会使日志数据从存储桶导入 BigQuery,因此不会有数据导出导入的费用和延时。
下面介绍如何打开这个功能并做示例查询。
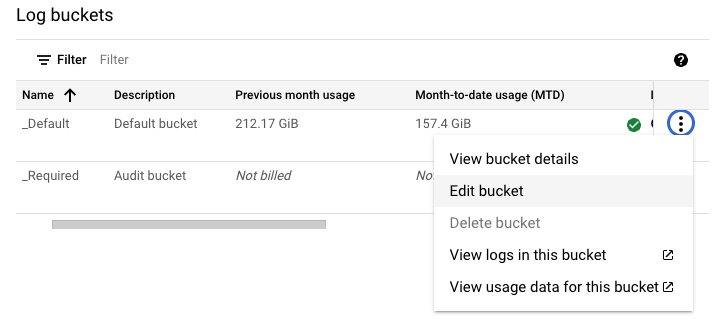
首先在日志桶列表界面,选择要创建链接数据集的桶,并在菜单中选择编辑桶。
在编辑详情页中勾选 Create a linked dataset in BigQuery,并提供一个数据集名字。这个名字不能与已有的 BigQuery 数据集重合。
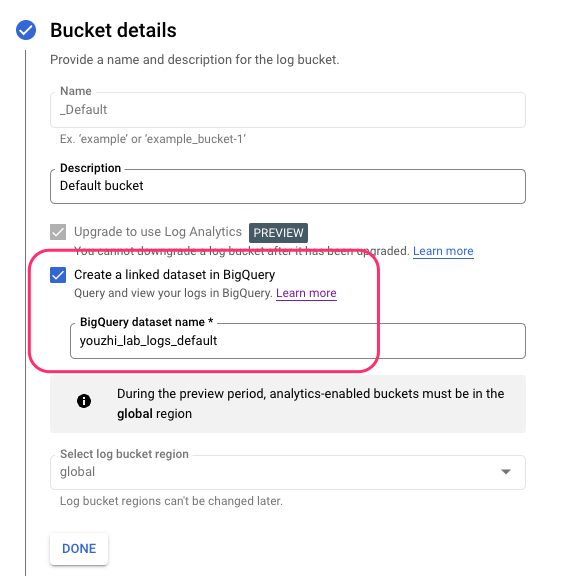
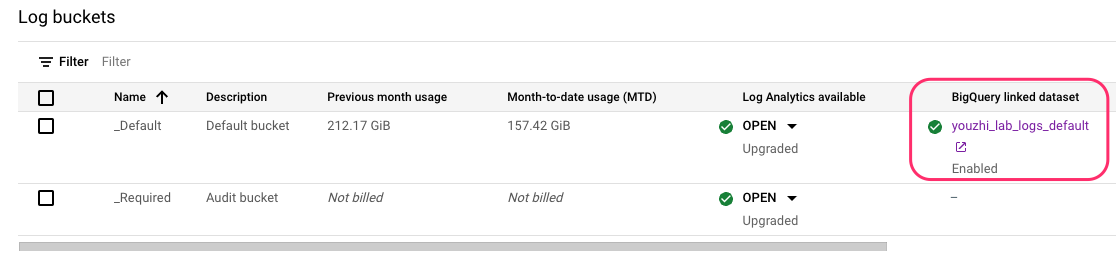
点击提交后,稍等一分钟然后刷新,可以看到日志桶的信息中新增了一个 BigQuery 数据集的访问链接。点击此链接,可以进入 BigQuery 页面对其进行查询分析。
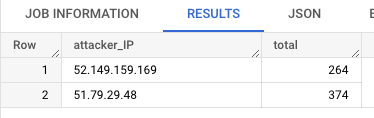
下面的示例查询,将日志桶里的日志表与 BigQuery 中的一个恶意客户端表做 JOIN,使用已知恶意客户端的 IP 对日志进行筛选,并根据恶意客户端 IP 进行日志分组统计。
注意,日志桶创建的链接数据集的默认区域为 US,因此只能与同为 US 区域的数据集的表做 JOIN。
SELECT
JSON_VALUE(json_payload.remoteIp) AS attacker_IP, COUNT(*) AS total
FROM
`youzhi_lab_logs_default._AllLogs` AS t1 JOIN `youzhi-lab.helpdesk.bad_clients` AS t2
ON JSON_VALUE(t1.json_payload.remoteIp) = t2.IP
WHERE
timestamp > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 24 HOUR)
AND resource.type = 'http_load_balancer'
AND http_request IS NOT NULL
GROUP BY 1
ORDER BY 2
LIMIT 50
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们