首页 > 资源 > 文章详情
使用 Google BigQuery ML 进行基于行为的广告归因
为什么要创建自定义归因工具? 因为如果使用开箱即用的工具,您会受到其在功能、数据转换、模型和启发式方法等方面的限制。
使用广告的原始数据,您可以构建最适合您的业务和专业领域的任何归因模型。 虽然很少有小公司收集原始数据,但大多数大型企业将其引入数据仓库并使用 BI 工具(如 Google Data Studio、Tableau、Microsoft Power BI、Looker 等)对其进行可视化。
Google BigQuery 是最受欢迎的数据仓库之一。 它非常强大、快速且易于使用。 事实上,您不仅可以使用 Google BigQuery 进行端到端营销分析,还可以训练 ML 模型以进行基于行为的广告归因。
简而言之,该过程如下所示:
1. 从广告平台或者第三方归因(如 Facebook Ads、Google Ads、Adjust、Appflyer 等)收集数据;
2. 从您的网站收集数据——浏览量、事件、UTM 参数、上下文(例如,浏览器、区域等)和转换;
3. 从 CRM 收集有关最终订单/潜在客户状态的数据;
4. 按会话将所有内容拼接在一起,以了解每个会话的成本;
5. 应用归因模型来理解每个会话的价值。

从开始到结束:数据收集;提取、转换和加载; Google BigQuery 处理;和应用程序 - 优化营销活动或报告。
下面,分享如何探索原始数据的全部潜力,开始使用 Google BigQuery ML 来构建复杂的归因,只需一点 SQL基础 即可——无需了解 Python、R 或任何其他编程语言。
归因的挑战
对于大多数在线广告来说,用户不太可能仅通过一次点击就完成购买。 用户在购买之前通常会从不同的来源数次访问您的网站。
这些来源可能是:
自然搜索;
社交媒体;
推荐和附属链接;
横幅广告和重定向广告。
您可以在 Google Analytics 中的热门转化路径等报告中查看所有来源:

随着时间的推移,您积累了大量的转换的流量源和流量链。 这使得各个广告渠道的绩效难以比较。 出于这个原因,我们使用特殊规则来评估每个来源的收入。 这些规则通常称为归因规则。
归因是对有助于预期”结果”的一组用户行为的识别,然后对这些事件中的每一个事件进行价值分配。
有两种类型:
1. Single Channel (单渠道);
2. Multi Channel (多渠道)。
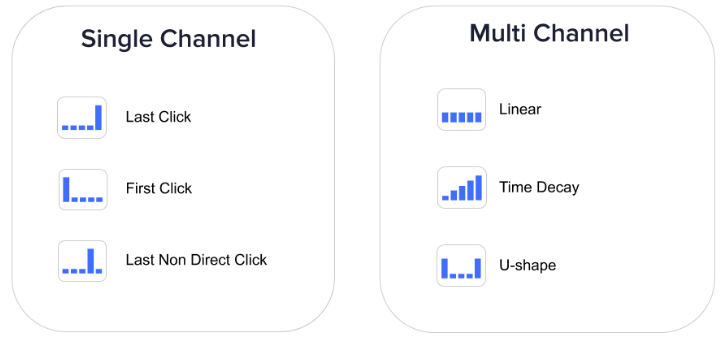
单渠道归因将 100% 的价值分配给一个来源。 多渠道归因模型使用一定的比例将转化价值分配到多个来源。对于后者,价值分配的确切比例由归因规则决定。
单渠道归因并不能反映客户广告流量之旅的真实情况,而且非常有偏见。 同时,多渠道归因也有其自身的挑战:
1. 大多数多渠道归因模型都充满了启发式——由(专家)人做出的决定。 例如,对于线性归因模型,为每个渠道分配相同的值; 在 U 形模型中,大部分价值流向第一个和最后一个渠道,其余的则分配给其他渠道。 这些归因模型基于人们发明的反映现实的算法,但现实却要比算法要复杂得多。
2. 即使是数据驱动的归因也不能解决欺诈流量,因为在大多数情况下,这种归因只考虑PV和 UTM 参数; 而不去分析流量到达客户网站和应用之后的实际行为。
3. 所有归因模型都是追溯性的。 他们告诉我们一些过去的统计数据,而我们想知道将来要做什么。
例如,让我们看一下以下数据,这些数据反映了 11 月两个广告活动的统计数据:
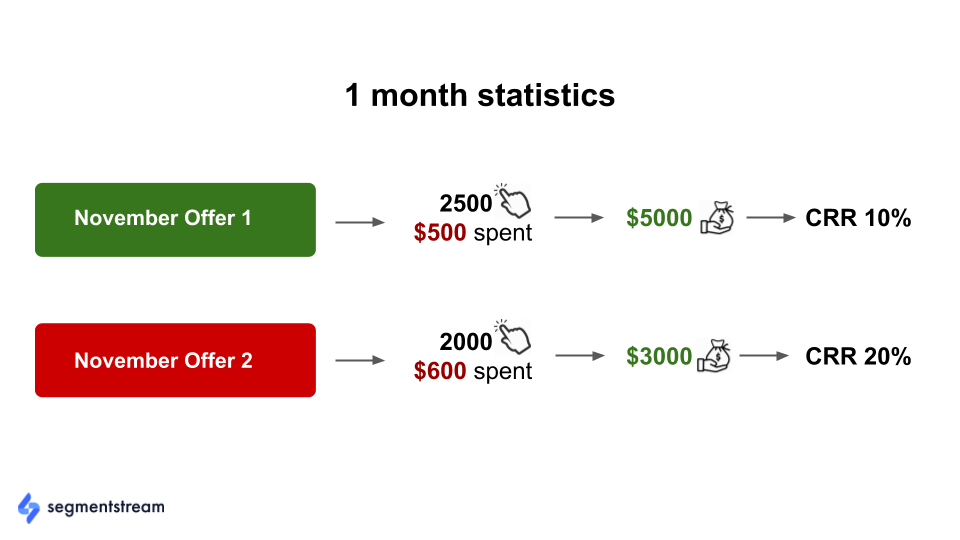
与“11 月优惠 2”相比,“11 月优惠 1”在成本收入比 (CRR) 方面的表现要好两倍。 如果我们事先知道这一点,我们可以为 优惠 1 分配更多预算,同时减少 优惠 2 的预算。但是,改变过去是不可能的。
12 月,我们将有新的广告,因此我们将无法重复使用 11 月的统计数据和收集到的知识。

我们不想再花一个月的时间投资于低效的营销活动。 这就是 ML 和预测分析的用武之地。
ML 带来了哪些变化
ML 使我们能够将归因和分析方法从算法(即数据 + 规则 = 结果)转变为监督学习(即数据 + 期望结果 = 规则)。
实际上,归因的定义(左)符合 ML 方法(右):

因此,ML 模型具有几个潜在优势:
1. 识别欺诈流量;
2. 能够重用获得的知识;
3. 能够在多个渠道之间重新分配值(无需手动算法和预定义系数);
4. 不仅要考虑 PV 和 UTM 参数,还要考虑实际的用户行为。
下面,我将描述我们如何构建这样一个模型,使用 Google BigQuery ML 来完成繁重的工作。
使用 Google BigQuery ML 构建归因模型的四个步骤
第1步:特征挖掘
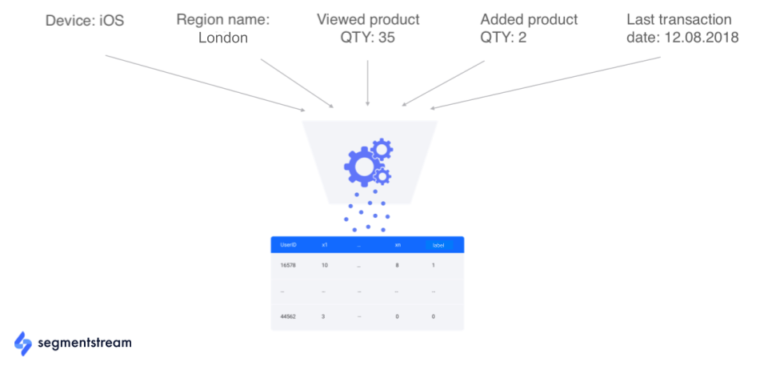
如果没有适当的特征挖掘,就不可能训练任何 ML 模型。 我们决定收集以下类型的所有可能特征:
新近特征。在某个时间范围内发生的事件或微转换的时间;
频率特征。在某个时间范围某个事件或微转发生的频率;
货币特征。在特定时间范围内发生的事件或微转换的货币价值;
用户上下文特征。用户设备、地区、屏幕分辨率等信息;
特征排列。上述所有特征的排列以预测非线性相关性。
在比较简单的算法归因模型时,收集和分析成百上千的不同事件非常重要。 例如,以下是可以在时尚网站的电子商务产品页面上收集的不同微转化:
图片展示;
图片点击;
查看服装尺寸;
选择服装尺寸;
阅读更多细节;
查看尺寸图;
添加到愿望清单;
添加到购物车等。
一些微转换的预测能力比您预期的要强。 例如,在构建我们的模型之后,我们发现查看产品页面上的所有图像对未来的购买具有巨大的预测能力。
而在标准的电子商务漏斗中,查看一张图片的产品PV分析与查看一张所有图片的产品PV相同。 对我们前文提到的对微转换的全面分析是大相径庭。
我们使用电商平台的一部分 JavaScript SDK 来收集所有可能的交互和微转换,并将它们直接存储在 Google BigQuery 中。 但是,如果您通过 Google Analytics API 将命中级数据导出到 Google BigQuery,或者如果您拥有内置导出到 BigQuery 的 Google Analytics 360,您也可以这样做。
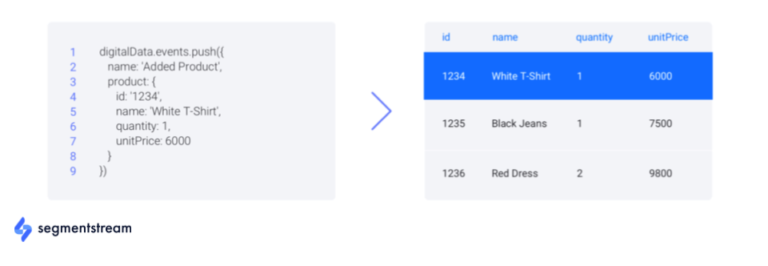
收集原始数据后,应将其聚合处理为归因原始数据,其中每个会话都有一组特征(例如,设备类型)和标签(例如,未来 7 天内的购买):
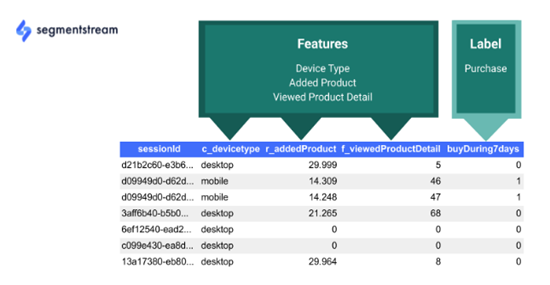
该数据集现在可用于训练一个模型,该模型将预测未来 7 天内购买的概率。
第 2 步:训练模型
在 Google BigQuery ML 之前的日子里,训练模型是一项复杂的数据工程任务,特别是如果你想每天重新训练你的模型。
您必须将数据从数据仓库来回移动到 Tensorflow 或 Jupyter Notebook,编写一些 Python 或 R 代码,然后将模型和预测上传回数据库:
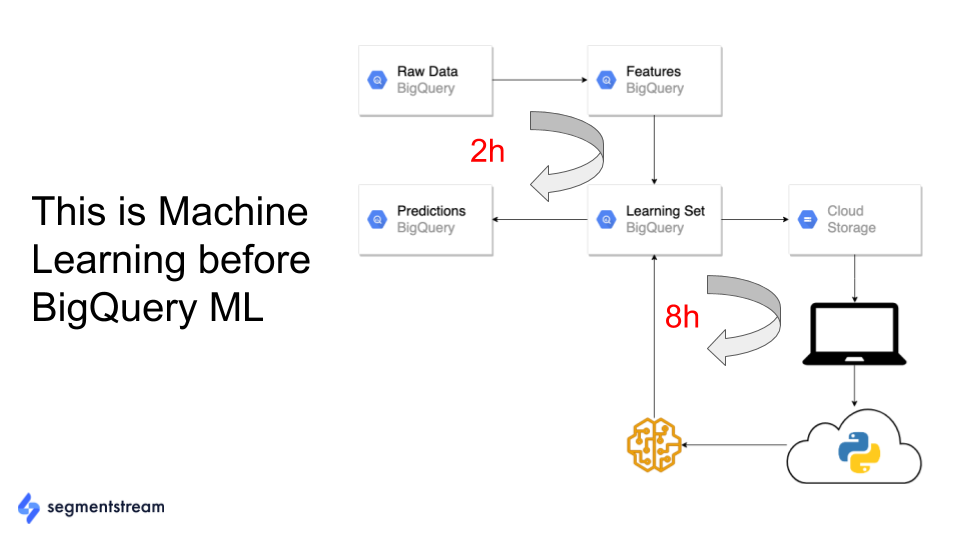
使用 Google BigQuery ML,情况不再如此。 现在,您可以在 Google BigQuery 数据仓库中收集数据、挖掘特征、训练模型和进行预测。 您不必在任何地方移动数据:
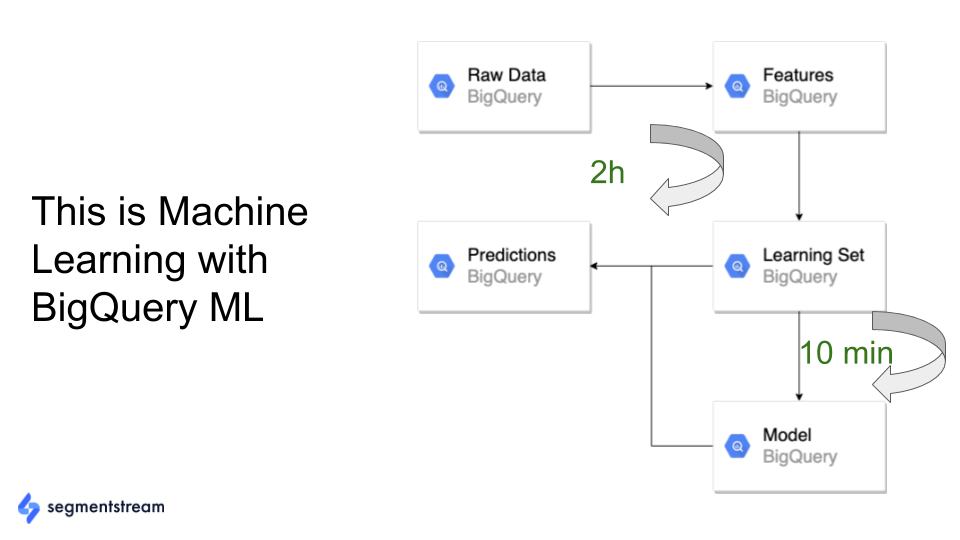
所有这些都可以使用一些简单的 SQL 代码来实现。
例如,要创建一个基于一组行为特征预测未来 7 天购买概率的模型,您只需运行如下 SQL 查询*:
CREATE OR REPLACE MODEL `projectId.segmentstream.mlModel` OPTIONS ( model_type = 'logistic_reg')AS SELECT features.* labels.buyDuring7Days AS labelFROM `projectId.segmentstream.mlLearningSet`WHERE date BETWEEN 'YYYY-MM-DD' AND 'YYYY-MM-DD'*用自己的 Google Cloud 项目 ID 代替 projectId,用自己的数据集名代替 segmentstream,用自己的模型名代替 mlModel; mlLearningSet 是包含您的特征和标签的表的名称,labels.buyDuring7Days 只是一个示例。
就是这样!在 30-60 秒内,你就有了一个训练有素的模型,其中包含所有可能的非线性排列、学习和验证集拆分等。最令人惊奇的是,这个模型可以每天毫不费力地重新训练。
第 3 步:模型评估
Google BigQuery ML 具有用于模型评估的所有内置工具。 您可以通过一个简单的查询来评估您的模型(用您自己的数据替换占位符值):
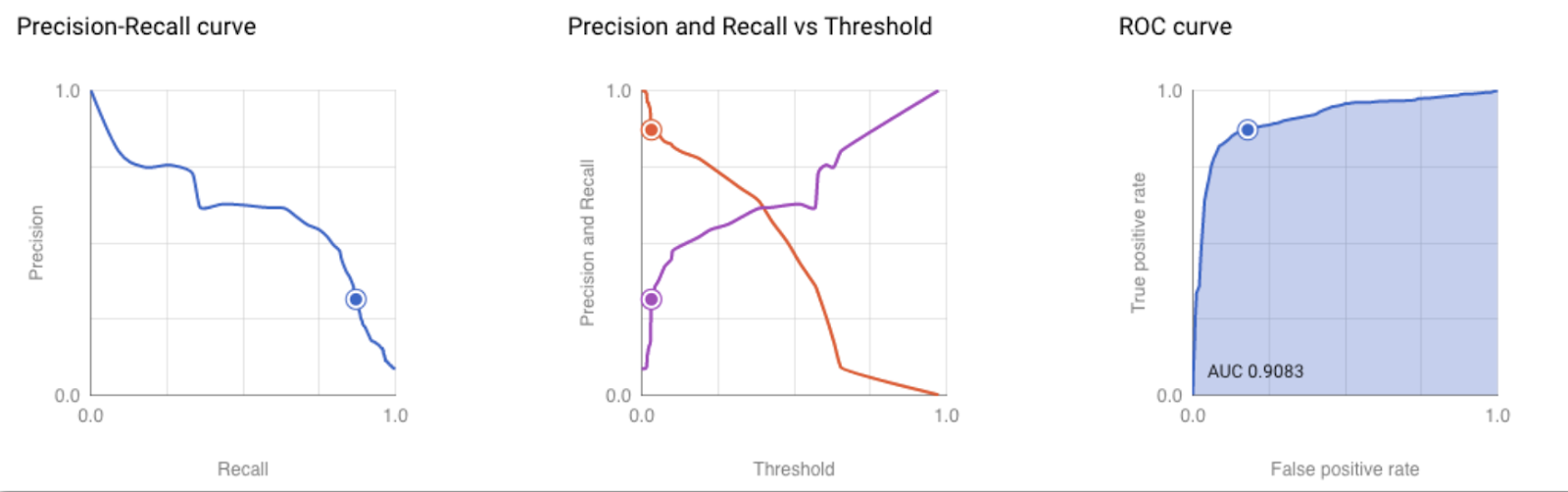
SELECT * FROM ML.EVALUATE(MODEL `projectId.segmentstream.mlModel`, ( SELECT features.*, labels.buyDuring7Days as label FROM `projectId.segmentstream.mlTrainingSet` WHERE date > 'YYYY-MM-DD' ), STRUCT(0.5 AS threshold) )这个模型评估将对模型的所有特征进行可视化:
精确召回曲线;
精度和召回率与阈值;
ROC 曲线。
第 4 步:构建归因模型
一旦你有一个模型可以预测每个用户在未来 7 天内的购买概率,你如何将它应用到归因中?
基于行为的归因模型:
为每个流量来源分配价值;
预测在交易时段开始和结束时买入的概率;
计算两者之间的“增量”。
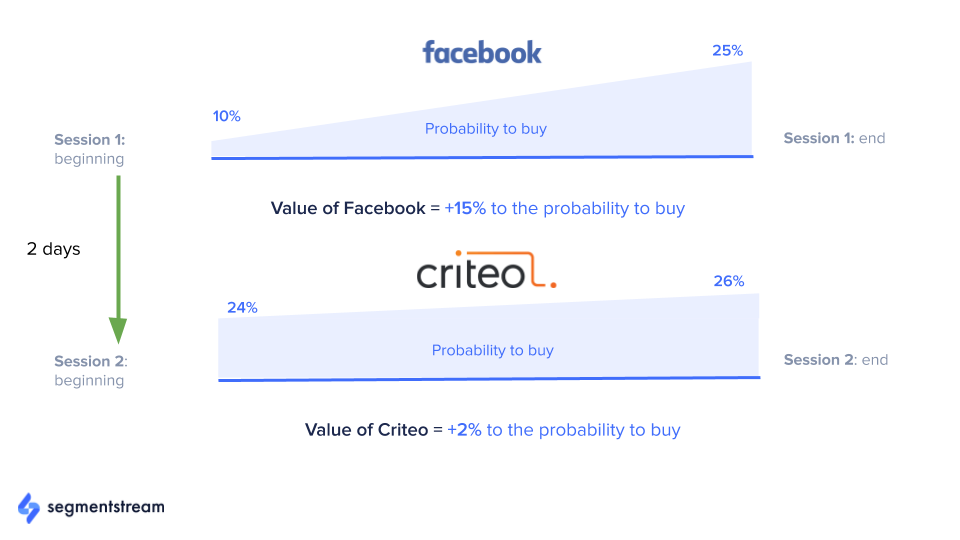
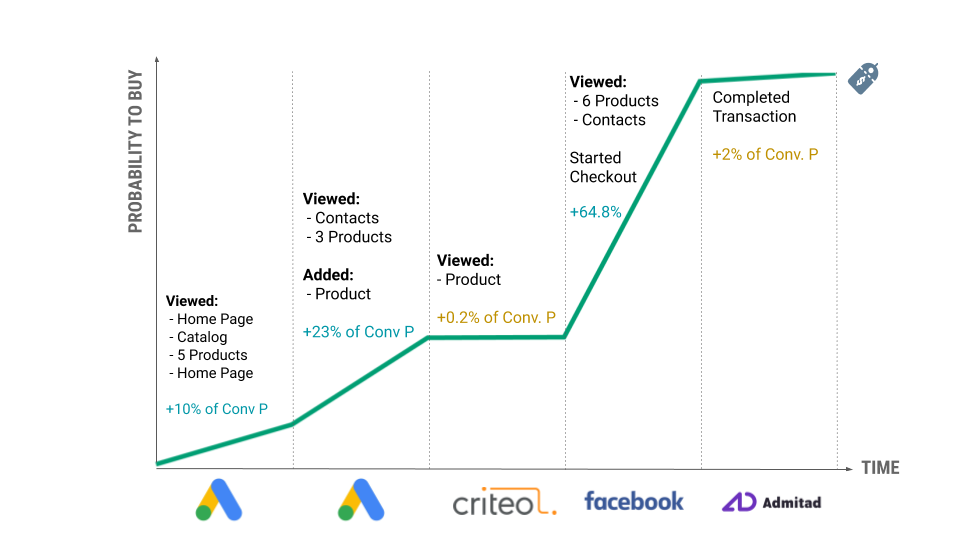
让我们考虑上面的例子:
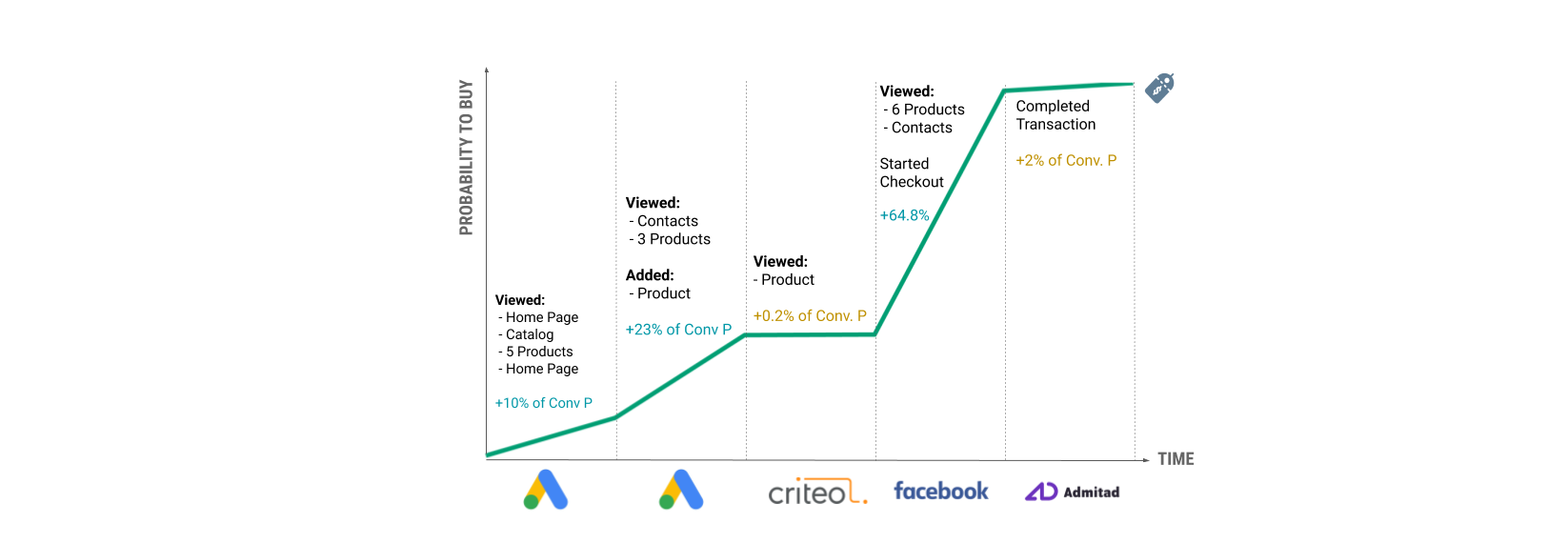
1. 用户第一次访问该网站。 该用户购买的预测概率为 10%。 (为什么不为零?因为它永远不会为零。即使基于区域、浏览器、设备和屏幕分辨率等上下文特征,用户进行购买的概率也不为零。)
2. 在会话期间,用户点击产品,将一些产品添加到他们的购物车,查看联系页面,然后没有购买就离开了网站。 在会话结束时计算出的购买概率为 25%。
3. 这意味着 Facebook 发起的会话将用户购买的概率从 10% 提高到了 25%。 这就是为什么 15% 分配给 Facebook。
4. 然后,两天后,用户通过点击 Criteo 重定向广告返回到该网站。 在会话期间,用户的概率没有太大变化。 根据该模型,购买的概率仅改变了 2%,因此 2% 分配给了 Criteo。
5. 等等…
在我们的 Google BigQuery 数据库中,每个用户会话都有下表:
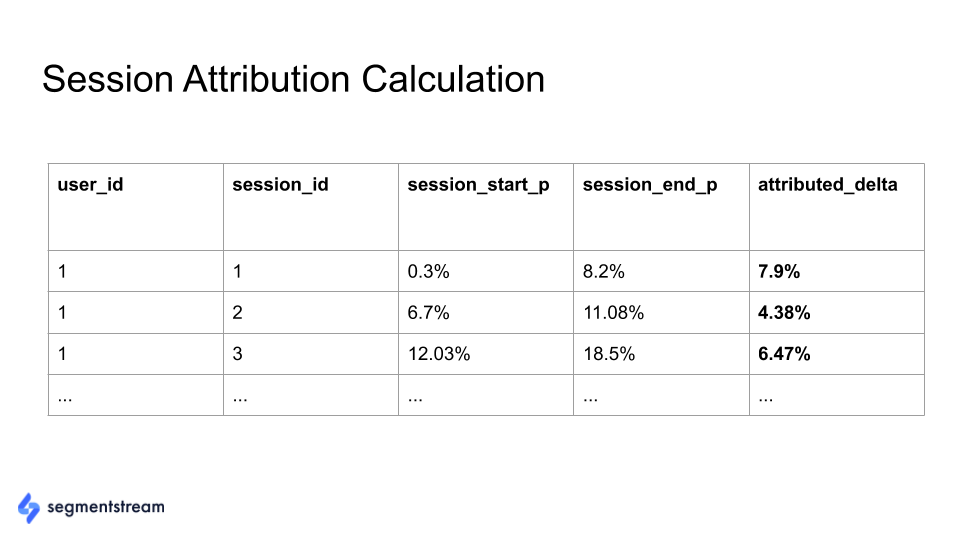
字段:
session_start_p 是在会话开始时预测的买入概率。
session_end_p 是会话结束时的预测买入概率。
attributes delta 是分配给会话的值。
最后,我们根据所有渠道/活动如何影响会话期间未来 7 天的购买概率来确定所有渠道/活动的值:
基于行为的归因的优缺点
优点
处理数百个特征而不是归因算法。
营销人员和分析师能够选择特定领域的Feature。
预测非常准确(高达 95% ROC-AUC)。
每天对模型进行再培训,以适应季节性和用户体验变化。
能够选择任何标签(预测的LTV、X 天内购买的概率、当前会话购买的概率)。
没有手动设置。
缺点
需要在网站或移动应用程序上设置SDK收集事件。
需要 4-8 周的历史数据。
不适用于每月用户数少于 50,000 的项目。
模型再训练的额外费用。
在没有网站访问的情况下,无法分析后视图。
结论
ML 仍然依赖于人脑的分析能力。 尽管 Google BigQuery ML 的数据处理能力无与伦比,但它会评估用户选择的因素——根据以往的经验,这些因素被认为对他们的业务至关重要。
算法可以用于证明或反驳营销人员的假设,并允许他们调整模型的特征以将预测推向所需的方向。 Google BigQuery ML 可以大大提高该过程的效率。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们