目录
概述
创建 GKE 集群
配置 Service Account 权限
创建和部署初始化节点的 DaemonSet
部署业务 Deployment
测试 Deployment 和集群扩容
测试 Deployment 和集群缩容
自动清除重发污点
概述
Google Kubernetes Engine (GKE) 是谷歌云上托管的容器服务平台,帮助用户更轻松便利地创建、管理和更新 K8s 集群以及上面部署的业务。作为托管服务,GKE 会限制用户在 Node 节点上的操作,比如配置数据盘、操作系统设置、安装第三方工具等,也不支持用 startup script 来初始化节点虚机。有些用户在从自建 K8s 集群迁移到 GKE 时,会遇到一些依赖于这些设置的容器 Pod 无法正常运行,特别是在启用了 Cluster Autoscaler,而又需要对自动扩容的节点做自动设置的情况下。本文提出一种方法,利用 DaemonSet 对节点做初始化设置,并利用自定义污点 Taint 阻止业务 Pod 在初始化完成之前被调度到节点上导致运行异常。这种方法也支持打开了 Cluster Autoscaler 的集群,可以自动在扩容的新节点上进行节点初始化,然后再调度业务 Pod。下面是该方法的具体步骤。
创建 GKE 集群
点击创建一个 GKE Standard 集群
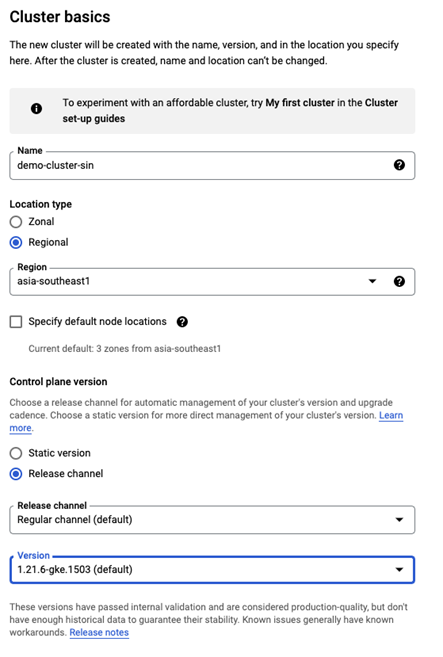
集群的 Default node pool 设置如下。

集群 default-pool 的 Node, Security, Metadata 设置采用默认值。
点击创建。
集群启动成功后,进入集群的详情页,点击 NODES 标签。然后点击上方“ADD NODE POOL”按钮。
在 Node pool details 配置中选中“Enable autoscaling”,并配置自动伸缩规模。
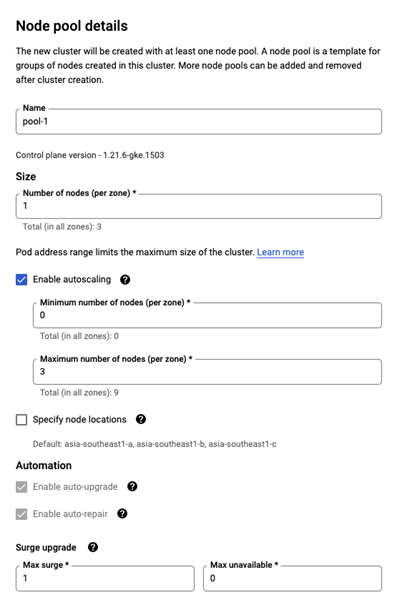
然后在 Nodes 配置中选择需要的节点虚机配置,比如选择 n1-standard-1 机型作为节点机型。
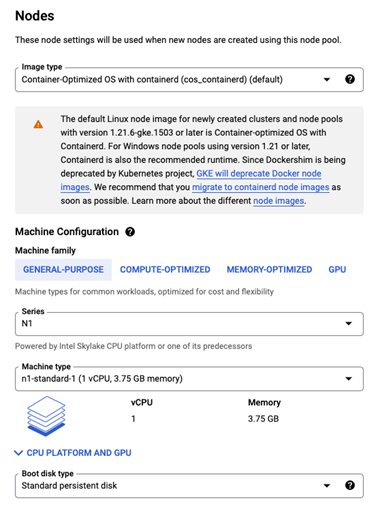
配置 Security,选择 service account 为 Compute Engine default service account,或者为 node 创建的专用 service account。Access scopes 选择 Allow full access to all Cloud APIs。这个设置是为了让 DaemonSet 中的 gcloud 利用 node 绑定的 service account 来调用 GKE API 或其它 GCP 产品 API。此外,也可以通过在 DaemonSet 中预置 SA 的 key 文件,或者用 Workloud Identity 等方式来授权和验证。

配置Metadata,选择添加Taint。
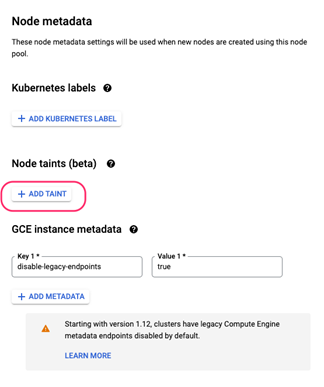
输入以下Taint设置。
Key = ignore-taint.cluster-autoscaler.kubernetes.io/mytaint
Value = init

注意,上面使用的污点名是一个特殊的污点名,使用了K8s保留的前缀 ignore-taint.cluster-autoscaler.kubernetes.io/。这个前缀的污点可以让 K8s 的 Cluster Autoscaler 在创建启动新节点时,不因为节点有污点而认为其启动失败,而是认为其仍在启动中而继续等待。这样避免 CA 立即创建新的节点来满足资源需求,而新的节点也带污点,从而导致死循环。DaemonSet 做完节点初始化后会把此污点去掉,从而让业务 Pod 可以调度到节点。DaemonSet 需要在15分钟内完成这些,否则 CA 会认为节点启动超时,从而继续创建新节点替代。
点击 Create 按钮创建 node pool。
在 terminal 中用以下命令行获取集群的登录验证信息。
gcloud container clusters get-credentials demo-cluster-sin --region asia-southeast1 --project youzhi-lab |
配置 Service Account 权限
为了让 DaemonSet 可以执行相应的 gcloud 和 kubectl 命令,需要给其实用的 service account,即集群节点配置的默认 service account 以下 IAM 角色权限。
1、Kubernetes Engine Cluster Admin
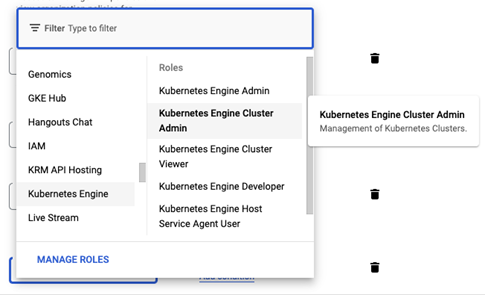
2、Kubernetes Engine Developer
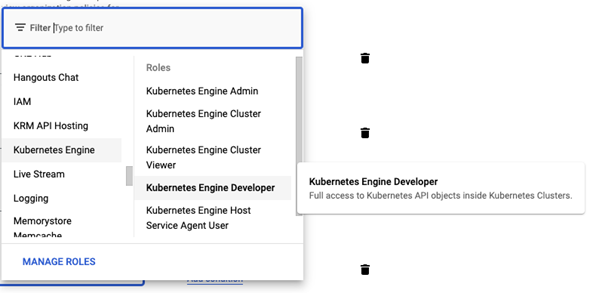
创建和部署初始化节点的 DaemonSet
首先创建 DaemonSet 脚本文件。运行以下命令新建一个文件夹。
mkdir cd ds-start-up
cd ds-start-up |
新建文件 manage-startup-script.sh,填入以下内容。该脚本是基于 https://github.com/kubernetes-retired/contrib/blob/master/startup-script/manage-startup-script.sh 脚本修改,去掉了 nsenter 执行方式,从而可以执行 Pod 环境里的 gcloud 命令。
#!/bin/bash
set -o errexit
set -o nounset
set -o pipefail
CHECKPOINT_PATH="${CHECKPOINT_PATH:-/tmp/startup-script.kubernetes.io_$(md5sum <<<"${STARTUP_SCRIPT}" | cut -c-32)}"
CHECK_INTERVAL_SECONDS="30"
# EXEC=(nsenter -t 1 -m -u -i -n -p --)
do_startup_script() {
local err=0;
bash -c "${STARTUP_SCRIPT}" && err=0 || err=$?
if [[ ${err} != 0 ]]; then
echo "!!! startup-script failed! exit code '${err}'" 1>&2
return 1
fi
touch "${CHECKPOINT_PATH}"
echo "!!! startup-script succeeded!" 1>&2
return 0
}
while :; do
stat "${CHECKPOINT_PATH}" > /dev/null 2>&1 && err=0 || err=$?
if [[ ${err} != 0 ]]; then
do_startup_script
fi
sleep "${CHECK_INTERVAL_SECONDS}"
done |
新建文件 Dockerfile,填入以下内容。
FROM google/cloud-sdk:latest
RUN apt update &&
apt install -y curl &&
curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl &&
chmod +x ./kubectl &&
mv ./kubectl /usr/local/bin/kubectl
ADD manage-startup-script.sh /
RUN chmod 755 /manage-startup-script.sh
CMD /manage-startup-script.sh |
新建文件 ds-startup-script.yaml,填入以下内容。注意 STARTUP_SCRIPT 环境变量的内容为需要每个 Node 在启动时需要执行的脚本。本例中该脚本不断检查 Node 的污点,并在 mytaint 出现时删除该污点。
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: startup-ds
labels:
app: startup-ds
spec:
selector:
matchLabels:
app: startup-ds
template:
metadata:
labels:
app: startup-ds
spec:
hostPID: true
nodeSelector:
cloud.google.com/gke-nodepool: pool-1
tolerations:
- effect: NoSchedule
key: ignore-taint.cluster-autoscaler.kubernetes.io/mytaint
operator: Equal
value: init
containers:
- name: startup-ds
image: gcr.io/youzhi-lab/my-ds-startup:v1.5
imagePullPolicy: Always
securityContext:
privileged: true
env:
- name: MY_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: STARTUP_SCRIPT
value: |
#!/bin/bash
gcloud container clusters get-credentials demo-cluster-sin --region asia-southeast1 --project youzhi-lab
# Customize the node
EXEC=(nsenter -t 1 -m -u -i -n -p --)
node_folder_ls_result=`"${EXEC[@]}" ls -l /mnt/disks/data`
if [[ -z "$node_folder_ls_result" ]]; then
zone_name=`gcloud compute instances list --filter="name=${MY_NODE_NAME}" --format "get(zone)" | awk -F/ '{print $NF}'`
diak_name=pd-data-${MY_NODE_NAME}
gcloud compute disks create ${diak_name} --size 100 --zone ${zone_name} --type https://www.googleapis.com/compute/v1/projects/youzhi-lab/zones/${zone_name}/diskTypes/pd-standard
gcloud compute instances attach-disk ${MY_NODE_NAME} --disk ${diak_name} --zone ${zone_name}
"${EXEC[@]}" mkfs.ext4 -m 0 -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb
"${EXEC[@]}" mkdir -p /mnt/disks/data
"${EXEC[@]}" mount -o discard,defaults /dev/sdb /mnt/disks/data
"${EXEC[@]}" chmod a+w /mnt/disks/data
fs_uuid=$("${EXEC[@]}" blkid -o value -s UUID /dev/sdb)
"${EXEC[@]}" echo "UUID=$fs_uuid /mnt/disks/data ext4 discard,defaults,nofail 0 2" >> /etc/fstab
fi
while :; do
echo "${MY_NODE_NAME}"
is_tainted=`kubectl describe node ${MY_NODE_NAME} |grep -A 5 "Taints:"|grep mytaint`
echo "is_tainted = ${is_tainted}"
if [[ ! -z "${is_tainted}" ]]; then
kubectl taint nodes ${MY_NODE_NAME} ignore-taint.cluster-autoscaler.kubernetes.io/mytaint=init:NoSchedule-
echo "untaint node ${MY_NODE_NAME}"
fi
sleep 60
done |
运行以下命令创建 DaemonSet 映像并部署到集群。
gcloud builds submit --tag gcr.io/youzhi-lab/my-ds-startup:v1.5 .
kubectl apply -f ds-startup-script.yaml |
运行以下命令查看 DaemonSet 的运行状态,应该为 Running。注意节点因为没有足够的 Pod 申请资源,会在一定时间内缩容,所以看到的节点数可能会是0-3个。
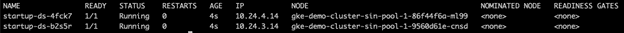
现在运行下面命令,查看所有节点的污点,确认 mytaint 已经被移除,输出结果为空。
kubectl describe nodes |grep -A 5 "Taints:"|grep mytaint |
部署业务 Deployment
新建文件 nginx-deployment.yaml,填入以下内容。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.16.1
resources:
requests:
memory: "64Mi"
cpu: "500m"
ports:
- containerPort: 80
nodeSelector:
cloud.google.com/gke-nodepool: pool-1 |
其中每个 replica 会申请 500mCPU,本例中每个节点只能容纳一个 replica。而且容器默认不容忍任何污点,只有在节点的污点被清除后才会调度到节点上。此外该 deployment 使用 nodeSelector 选择了部署在特定标签的节点上,即之前设置过 Label 的 pool-1 的节点上。
部署该 Deployment。
kubectl apply -f ./nginx-deployment.yaml |
查看 Pod 部署情况,可以看到每个节点上都有一个 DaemonSet 和一个 Nginx Pod 在运行。

测试 Deployment 和集群扩容
现在进行扩容,运行以下命令。
kubectl scale --replicas=6 deployment/nginx-deployment |
再查看 Pod 列表,可以看到多了 4 个 Pending 状态的 Pod。

查看其中一个 Pending 的 Pod 描述,可以看到其触发了集群扩容。
kubectl describe pod nginx-deployment-74f89f4cb6-4h95m |
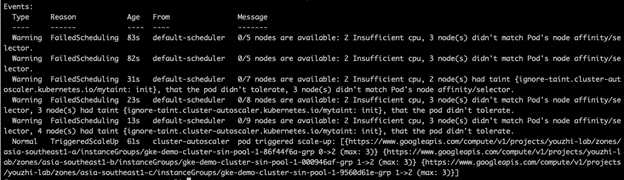
在谷歌云控制台的 Logging 日志服务的 Logs Explorer 页面,通过以下查询可以看到该集群的扩容日志记录。
resource.type="k8s_cluster"
resource.labels.project_id="youzhi-lab"
resource.labels.location="asia-southeast1"
resource.labels.cluster_name="demo-cluster-sin" severity>=DEFAULT
logName="projects/youzhi-lab/logs/container.googleapis.com%2Fcluster-autoscaler-visibility"

等待几分钟,再查看 Pod 列表,可以看到所有之前 Pending 的 Pod 都已经调度到节点上,并更新为 Running 状态。
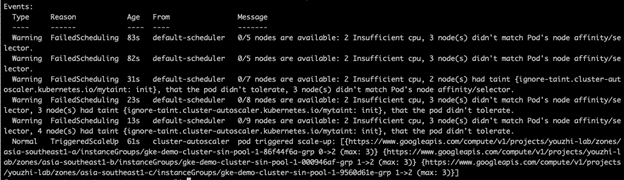
用以下命令查看 Node 数量和描述,可以看到 Node 数量增加到6个,而且 Node 的 Taint 为 None。
kubectl get nodes
kubectl describe node gke-demo-cluster-sin-pool-1-9560d61e-8sp2 |
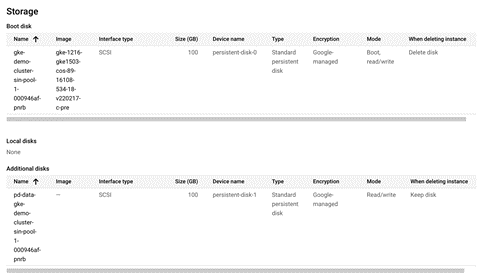
此外,在控制台查看新增的节点虚机的详情,可以看到它们都成功添加了数据盘。说明 DaemonSet 的定制节点初始化成功。
测试 Deployment 和集群缩容
再运行以下命令对 deployment 进行缩减,缩减后观察集群的缩容情况。
kubectl scale --replicas=1 deployment/nginx-deployment |
大约10分钟后,Cluster Autoscaler 会触发缩容命令。12-15分钟后,集群缩容完成。

自动清除重发污点
在更新 node pool 的 metadata 比如 labe l时,之前配置的初始化污点 mytaint 会再次更新到所有节点上。这时需要 DaemonSet 自动发现并再次去除该污点,防止新的 pod 无法调度到节点上。在上面的 DaemonSet 的脚本设置中已经考虑并实现了这个功能。下面进行验证。
首先关掉节点池 pool-1 的 Autoscaling 功能,以便更新其 Tag。

首先在本地 terminal 中运行以下命令,轮询 Pod 状态和节点上的污点信息。
while true; do kubectl describe nodes |grep -A 5 "Taints:"|grep mytaint; kubectl get pods -o wide; sleep 2; done |
然后在另一个 terminal 窗口中,运行以下命令来给 node pool 加一个 label。
gcloud beta container node-pools update pool-1 --node-labels=label1=1, --cluster=demo-cluster-sin --region asia-southeast1 |
回到之前的 terminal 窗口,可以观察到以下输出。
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74f89f4cb6-rnbsr 1/1 Running 0 4h 10.24.3.3 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
startup-ds-w86hn 1/1 Running 0 3h59m 10.24.3.2 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74f89f4cb6-rnbsr 1/1 Running 0 4h 10.24.3.3 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
startup-ds-w86hn 1/1 Running 0 3h59m 10.24.3.2 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
Taints: ignore-taint.cluster-autoscaler.kubernetes.io/mytaint=init:NoSchedule
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74f89f4cb6-rnbsr 1/1 Running 0 4h 10.24.3.3 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none> startup-ds-w86hn 1/1 Running 0 3h59m 10.24.3.2 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
Taints: ignore-taint.cluster-autoscaler.kubernetes.io/mytaint=init:NoSchedule
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74f89f4cb6-rnbsr 1/1 Running 0 4h 10.24.3.3 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none> startup-ds-w86hn 1/1 Running 0 3h59m 10.24.3.2 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
Taints: ignore-taint.cluster-autoscaler.kubernetes.io/mytaint=init:NoSchedule
......
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74f89f4cb6-rnbsr 1/1 Running 0 4h5m 10.24.3.3 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none> startup-ds-w86hn 1/1 Running 0 3h59m 10.24.3.2 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
Taints: ignore-taint.cluster-autoscaler.kubernetes.io/mytaint=init:NoSchedule
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74f89f4cb6-rnbsr 1/1 Running 0 4h5m 10.24.3.3 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
startup-ds-w86hn 1/1 Running 0 6s 10.24.3.4 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-deployment-74f89f4cb6-rnbsr 1/1 Running 0 4h5m 10.24.3.3 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none>
startup-ds-w86hn 1/1 Running 0 18s 10.24.3.4 gke-demo-cluster-sin-pool-1-9560d61e-jfxv <none> <none> |
以上输出说明,label 更新后,之前去除的 mytaint 污点也重新添加到了节点上。过了大概1分钟,该污点被 DaemonSet 去除。此外,该过程中已经运行在节点上的 Nginx pod 不会因为新增的 taint 而停止运行。
测试完成后,可以把节点池的 Autoscaling 再打开。
