首页 > 资源 > 文章详情
从 SRE 到 Anthos DevOps 的工具与实践

写在前面
系统可靠性工程(Site Reliability Engineering),简称SRE,是在Google实践了有15年以上的DevOps工程实现。
“DevOps是一种重视「软件开发人员(Dev)」和「IT运维技术人员(Ops)」之间沟通合作的文化、运动或慣例。透过自动化「软件交付」和「架构变更」的流程,来使得构建、测试、发布软件能够更加地快捷、频繁和可靠。” -- 维基百科对DevOps的定义。而Google定义SRE是DevOps的一种实现(软件工程意义上的实现,implement),SRE满足了DevOps的五个核心要求:
1. 减低组织隔阂,特别的,指开发部门和运维部门的隔阂
○ SRE工程师与开发人员共担责任
○ SRE工程师和开发人员使用同样的工具
2. 接受“系统失效是常态”这一事实
○ SRE拥抱风险
○ SRE用服务等级指标(SLI)和服务等级目标(SLO)来量化系统失效和可用性
○ SRE要求“不指责(Blameless)”的故障分析(Postmortem)
3. 实现渐次发布
○ SRE鼓励开发者和产品经理通过提高发布频率的方式来减少发布带来的失效
4. 大规模使用工具和自动化
○ SRE的工作之一就是开发自动化工具
5. 度量一切
○ SRE有一整套度量系统的方法
○ 从根源上,SRE认为运维是一个软件开发问题
Anthos是Google Cloud开发的基于Kubernetes的现代化应用平台。起初,Google的工程师开发了Borg来帮助SRE工程师们运维数以万计的服务器。2014年Google发布了Kubernetes,并称之为开源版本的Borg。自此,Google不断地将SRE的经验通过Kubernetes向外输出,这些输出的集大成即为Anthos平台。
从本篇开始,我们将通过一系列文章,讲述SRE的实践以及运用Anthos简化SRE的落地过程。并且希望能回答企业IT运维中两个直击灵魂的问题:
● 我的系统到底可靠性如何
● 开发要发新版本,到底是保我的可靠性是让他们发新版本
SRE的实践(一)
SRE围绕可用性进行运维,从业务需求的角度来感知可用性并管理可用性是SRE实践的重要部分。所以SRE天生就对系统可靠性有全面的掌握。SRE同时认为,更新系统带来的风险是可控的,而使用一个已经无人维护的依赖组件带来的风险是不可控的,因此,通过持续的更新才能保证系统的可用性。
虽然已经有很多文章和书籍对SRE进行了论述,但作为本系列文章的开端,我们还是想先从实践的角度,讲一讲我们在做SRE的咨询过程中发现的问题以及得到的经验。
改变
我们发现,SRE的落地往往会在这三个方面对现有的IT运维部门提出改变:
● 从组织上,SRE需要建立一个有开发能力的运维团队,这个团队的多数精力都应该放在开发上,用开发的运维工具来实现运维。剩下的精力应在响应运维事件(On-call)和帮助业务开发人员评审软件架构之间分配。这三部分的时间分配常常为5:2:3
● 从流程上,SRE的运维以服务等级目标(SLO)为导向。SRE认为100%的可靠性是不存在的,承认系统存在失效的风险然后量化和管理风险才是SRE的工作目标。在与其他部门对接时,定义并协商SLO是讨论的重点;于日常工作时,管理和使用错误预算(在一个时间段内,可以发生故障并且不影响SLO达成的时间)则是工作核心
● 在运维工具上,需要有工具来收集数据来实现“度量”从而满足SLO的量化计算,也需要有工具来实现自动化。现有的工具往往需要改造以适应SRE,选择一个合适的起点可以事半功倍
另外,“不指责”文化也与企业中现有的“背锅/甩锅”文化不太兼容。当我的同事听说我要参加一个给传统企业做的SRE咨询项目时,告诉我,如果能让客户接受“不指责”的文化,就可以算做成功了。
流程
SRE围绕SLO展开工作。SRE认为100%的可靠性是不存在的,量化风险并管理风险才是正确的目标。实际工作时,SRE会将SLO转化更易管理的指标:错误预算,如下公式
100% - SLO=错误预算
SRE会监控度量系统实际正常运行的时间,只要正常运行的时间高于目标,或者说错误预算还有剩余,SRE就可以做一些可能影响可用性的操作,如发布新版本等。
如下图所示,在不同的SLO目标下,错误预算也有很大的区别:

更进一步,当SRE工程师们可以对错误率进行控制时,他们将可以获得更大的错误允许时间。
SLO是SRE与其他部门对接时协商确定的。一个常见的争论是"我们不接受任何的宕机时间”或者是“我们要确保100%在线”。但是当讨论深入的时候,却发现这些100%在线,是指去掉例行维护时间之后的在线时间,更进一步,如果被讨论的系统是建设有高可用(HA)的设施的,HA切换所花的时间,也会算作在线时间。然而在SRE看来,这些例行维护时间和HA切换时间都应该被计入错误预算。
当转为SLO模式后,运维人员可以更灵活的使用这些错误预算,并且可以更合理的规划和设计发布流程,最终实现在不改变SLO的前提下,增加发布频率。举例来说,灰度发布可以把错误率控制在一个很小的程度,如果在发布过程中,监控错误预算的消耗,并在错误预算消耗到一定程度时,暂停发布或者中止发布,就可以实现以可控的错误预算消耗来完成发布这一目标,从而实现更多的版本发布。更进一步,如果把上面的 “发布-监控-控制” 的过程进行自动化,则可以实现无人值守的自动发布,解除开发人员和运维人员之间的隔阂,提高生产效率。在之后的文章中,我们也会讲述一个自动化发布的案例,本篇按下不表。
对于企业管理者来说,全面部署SLO模式,还能帮助管理者对IT系统整体的健康状态有一个更全面精确的认识。进一步,通过识别薄弱环节,管理者会更清楚的知道如何投入资源以获得更好的健康状况。
SLO的确定
当我们讲确定SLO的时候,其实是在讲两个问题:首先,用什么指标来定义我们的SLO,然后,这个SLO应该定义为多少,即错误预算有多少。
让我们先来看看跟SRE有关的几个术语:
● CUJ – 核心用户旅程
● SLI - 服务等级指标
● SLO - 服务等级目标
● SLA - 服务等级协议
这些定义有些抽象,我们用一个实际的例子来解释,以内存缓存服务为例,提供数据的读写即构成其CUJ,针对这两个CUJ,它们的操作成功率和操作延迟,我们就获得了四个SLI,针对这几个SLI,我们就有讨论SLO的依据。SLO和SLA之间的区别在于,SLO应用于企业内部部门之间,而SLA是企业与其客户签订的协议,因此SLA会引入罚则。所以SLA从数值上往往低于SLO。
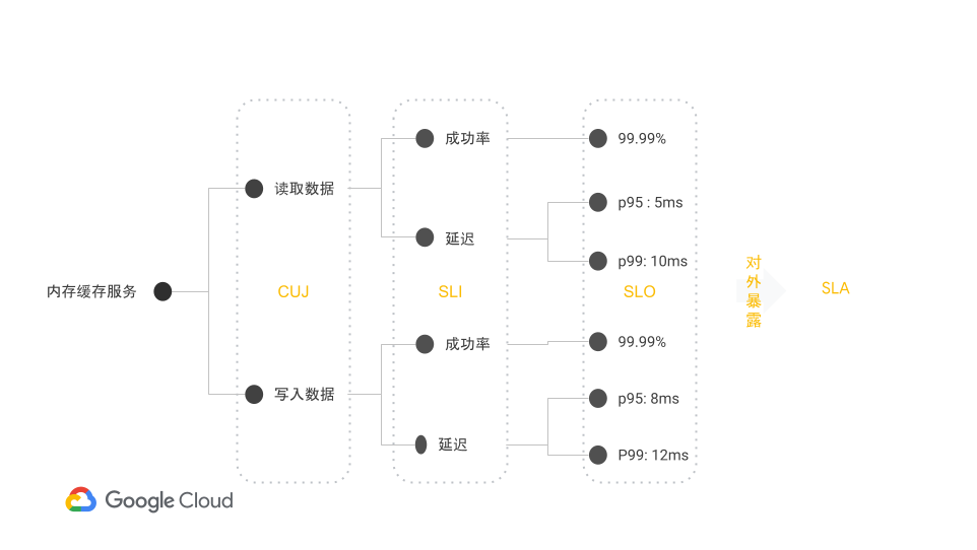
而当我们要确定内存缓存服务的SLO时,我们知道网站应用的用户不会直接访问内存缓存,用户只感受到网站本身的可用性:操作是否成功,操作是不是很慢:
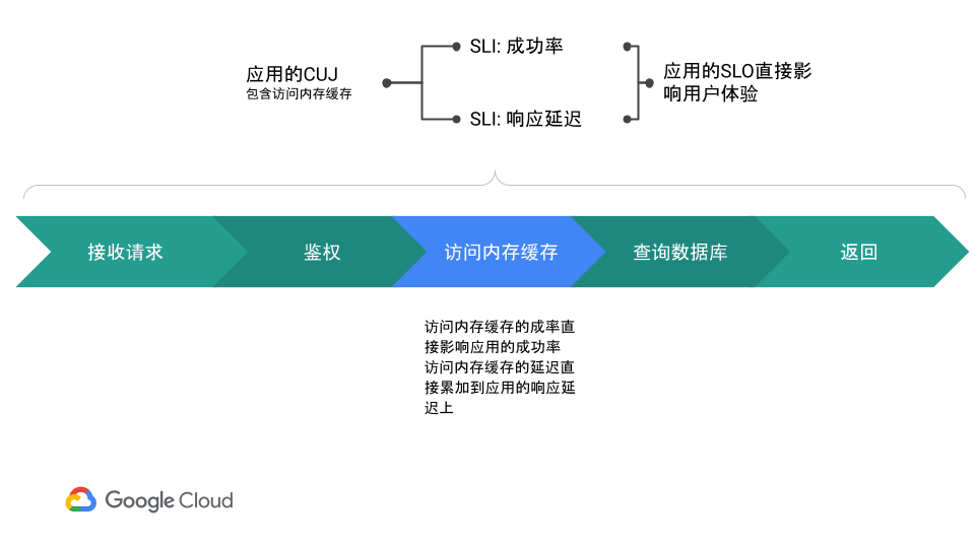
通过这种方式,应用的SRE工程师和内存缓存服务的SRE工程师就可以分别确定自己的SLO需求和对对方的SLO的期望,从而协商出各自的SLO。
小结
本篇介绍了在SRE实践过程中对运维部门的改变,以及从流程的上如何建立SRE体系核心的SLO协商。在以后的文章中,我们会讨论SRE在组织上如何改变运维,以及SRE对工具提出的要求。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们