首页 > 资源 > 文章详情
OPPO 如何借助 Google Vertex AI NAS 为移动设备增强 AI 能力
作为一家全球领先的科技公司,OPPO 一直致力于为终端使用者提供最佳的使用体验。为实现这一目标,我们不断探索能够更好地利用最新技术(包括云与 AI)的方法。其中一个典型的例子是 OPPO 提出的 AndesBrain 战略,在移动设备上的 AI 模型开发过程中通过将云工具与移动硬件集成在一起,让终端设备变得更加智能。
OPPO 之所以采用这种策略,是因为 OPPO 相信 AI 能够释放移动设备的潜力。一方面,在终端设备上运行 AI 模型可以将用户数据保留在移动硬件上,而不是将它们发送到云端,这样可以更好地保护用户隐私。另一方面,移动芯片的计算能力正在快速提升,能够支持更加复杂的 AI 模型。通过将云平台与移动芯片结合进行 AI 模型训练,我们可以利用云计算资源开发出能够适应不同移动硬件的高性能 ML 模型。
2022年,OPPO 开始在 StarFire 上实施 AI 工程战略,StarFire 是我们自研的 ML 平台,该平台把云端和终端设备相结合,也是 AndesBrain 的六大核心能力之一。 通过 StarFire,我们能够利用各种先进的云技术来满足我们的开发需求。为加速 AI 模型的开发过程并增强移动设备的 AI 能力,我们与谷歌和高通进行了相关的技术合作,并应用了 Google Vertex AI 神经架构搜索 (Vertex AI NAS)。
在移动设备上开发 AI 模型所面临的挑战
在移动设备上开发 AI 模型的其中一大瓶颈是,与计算机所采用的芯片相比,移动芯片的计算能力依然是有限的。 在使用 Vertex AI NAS 之前,OPPO 的工程师主要使用两种方法来开发移动设备可支持的 AI 模型。 一种是通过网络剪枝或模型压缩以简化在云平台上训练的神经网络,使其可以适用于移动芯片。另一种是采用由深度可分离卷积等技术构建的更轻型神经网络架构。
而这两种方法有三大挑战需要克服:
1. 漫长的开发周期:要验证 AI 模型能否在移动设备上流畅运行,需要进行反复测试,并根据硬件特性手动调整模型。由于每个移动设备具有不同的计算能力和内存,AI 模型的定制需要大量的人力成本并且导致开发周期过长。较低的准确率:受限于计算能力,移动设备仅支持较轻的 AI 模型。但是,在云平台上训练的 AI 模型经过裁剪或压缩后,模型的准确率会下降。我们或许能够在云环境中开发出准确率达到 95% 的 AI 模型,但它将无法良好运行在终端设备上。
2. 较低的准确率:受限于计算能力,移动设备仅支持较轻的 AI 模型。但是,在云平台上训练的 AI 模型经过裁剪或压缩后,模型的准确率会下降。我们或许能够在云环境中开发出准确率达到 95% 的 AI 模型,但它将无法良好运行在终端设备上。
3. 性能妥协:对于移动设备上的每个 AI 模型,我们需要在准确率,延迟和功耗之间取得平衡。无法同时实现高准确率、低延迟和低功耗。因此,性能妥协是不可避免的。
Vertex AI NAS 针对 AI 模型开发所提供的优势
神经架构搜索技术最早由 Google Brain 团队于 2017 年开发,旨在创建经过训练的 AI,并根据开发人员的需求优化神经网络的性能。通过针对特定任务自动发现和设计神经网络的最佳架构,神经架构搜索技术让开发人员能够更轻松地实现更好的 AI 模型性能。
Vertex AI NAS 是目前唯一在公有平台上可用的完全托管的神经架构搜索服务。由于 OPPO 的 ML 平台 StarFire 是基于云的,我们可以轻松地将 Vertex AI NAS 与我们的平台进行连接并开发 AI 模型。 最重要的是,我们选择采用 Vertex AI NAS 进行设备端 AI 模型开发,是因为它可以提供以下四大优势:
1. 自动化的神经网络设计:如上所述,在移动设备上开发 AI 模型可能需要大量人力和时间。由于神经网络设计通过 Vertex AI NAS 实现了自动化,开发时间可以大大缩短,我们可以毫不费力地让 AI 模型去适应不同的移动芯片。
2. 自定义奖励参数:Vertex AI NAS 支持自定义奖励参数,这在 NAS 工具中是非常少见的。这意味着我们可以自由添加我们所需要优化 AI 模型的搜索约束。通过利用这一功能,我们将功耗添加为搜索约束,并成功地在移动设备上将我们的AI模型的能耗降低了 27%。
3. 无需为移动设备压缩 AI 模型:Vertex AI NAS 可以根据连接的移动芯片传回的实时奖励,直接设计适合移动设备的神经网络架构。最终结果无需被进一步处理即可在终端设备上运行,从而节省了 AI 模型适配所需的时间和精力。
OPPO 如何使用 Vertex AI NAS 提升移动设备上 AI 模型的能效
降低功耗是为移动设备上的 AI 模型提供卓越用户体验的关键工作,尤其那些是与多媒体和图像处理相关的计算密集型模型。 如果 AI 模型耗电过多,移动设备可能会过热并迅速耗尽电池电量。 这就是为什么需要将 Vertex AI NAS 用于 OPPO 的场景中,其主要目的是为了提高移动设备上 AI 处理的能效。
为实现这一目标,我们首先将功耗为自定义搜索约束添加到 Vertex AI NAS,默认情况下它仅支持延迟和内存奖励。通过这种方式,Vertex AI NAS 能够根据功率、延迟和内存的回报来搜索神经网络,并降低我们 AI 模型的功耗,同时达到我们所期望的延迟和内存消耗水平。
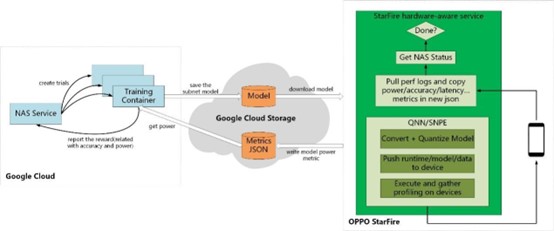
之后,我们通过 Cloud Storage 将 StarFire 平台与 Vertex AI NAS 连接到一起。 同时,StarFire 通过高通提供的 SDK 与搭载高通骁龙 8 Gen 2 芯片组的智能手机相连。在这种架构下,Vertex AI NAS 可以不断地将最新的神经网络架构通过 Cloud Storage 发送给 StarFire,再由 StarFire 将模型导出到芯片组进行测试。 测试结果通过 StarFire 和 Cloud Storage 再次回传给 Vertex AI NAS,让它根据奖励进行下一轮的架构搜索。
这个过程不断地重复,直到达到我们的目标。最终,我们将 AI 模型的功耗降低了 27%,计算延迟降低了 40%,同时将准确率保持在优化前的水平。
拓宽应用范围
通过 Vertex AI NAS 进行 AI 模型优化的首次成功让我们倍感鼓舞。我们计划在未来推出的智能手机上部署这种节能 AI 模型,并在我们其他 AI 产品的算法开发中实施由 Vertex AI NAS 支持的相同模型训练过程。除了功率之外,我们还希望将带宽和算子友好度等其他奖励参数作为搜索约束添加到 Vertex AI NAS 中,以进行更全面的模型优化。
Vertex AI NAS 极大地提升了我们在智能手机上优化 AI 能力,但我们依然相信还有很大的潜力可以被挖掘。我们将继续与 Google Cloud 合作,扩大对 Vertex AI NAS 的使用范围。对于有兴趣采用 Vertex AI NAS 的开发者,我们建议在启动开发过程之前针对相关的硬件设置奖励参数,如果需要自定义搜索约束,请先熟悉有关构建搜索空间的方法。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们