首页 > 资源 > 文章详情
Google Cloud 上的 Clickhouse
概述
Clickhouse 是一个开源的、面向列的数据库,用于在线查询分析处理 (OLAP)。 自 2016 年开源以来,Clickhouse 已被 Cloudflare、Bloomberg、eBay、Spotify、CERN、字节跳动、腾讯、阿里巴巴等数百家公司所使用。 主要用例包括 Web 和应用程序分析、广告网络和 RTB、电子商务、在线游戏和物联网。
Clickhouse 如此受欢迎的关键原因之一是它的高性能。 根据 Clickhouse 社区发布的内部基准测试报告,与其他 OLAP 数据库相比,Clickhouse 的性能表现良好,因为它是面向列的,并且是用 C++ 编写的。此外,Clickhouse 还支持几个关键特性,使 Clickhouse 更适合 OLAP 工作负载,包括稀疏索引、压缩、多核并行处理和分布式查询。
为什么它对 Google Cloud 用户很重要
我们开始看到越来越多的客户有兴趣将他们现有的本地 Clickhouse 迁移到 Google Cloud 或其他公有云基础设施。 迁移到 Google Cloud 具有以下优势:
轻松部署
Google Cloud 提供自动化脚本来简化 Clickhouse 部署,而手动部署可能需要几天时间。我们还提供了推荐的硬件、软件和网络配置的部署指南。
成本优化
轻松按需手动扩容或缩容 Clickhouse 集群资源,提高资源(VM)利用率
冷数据可以被存储在更便宜的 GCS 存储中
与其他 Google Cloud 服务集成
与 BigQuery 等 Google Cloud 原生服务集成,以更好地支持分析用例。
在本篇博客中,我们将讲述在 Google Cloud 上部署 Clickhouse 的参考架构,以及与其他 Google Cloud 原生服务的集成。 我们还提供了详细的部署指南和自动化脚本来加速部署过程。
参考架构
本地 Clickhouse 迁移到 Google Cloud 有多种方法:直接原样迁移、优化选项1和优化选项2。
直接原样迁移
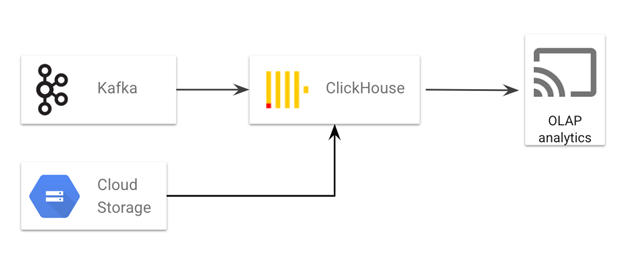
在直接原样迁移架构中,客户可以简单地将 Clickhouse 从本地迁移到 Google Cloud,而无需与其他 Google Cloud 服务进行太多集成。
批量数据在 GCS 中暂存,然后加载到 Clickhouse。GCS 还可以作为 Clickhouse 的数据导出或备份目的地
Kafka(部署在本地或云端)用于将流数据摄取到 Clickhouse
Clickhouse 部署在 Google Cloud 上,提供 OLAP 分析服务
优化选项 1

在优化选项 1 架构中,Clickhouse 专用于实时 OLAP 分析,而 BigQuery 用于更复杂的数据分析,例如多个大表连接。
批量数据在 GCS 中暂存,然后加载到 BigQuery。GCS 还可以作为 Clickhouse 数据导出或备份的目的地。
Kafka(部署在本地或云端)用于将流数据摄取到 Clickhouse。Kafka 中的流式数据也被复制到 Google Cloud 原生消息传递服务 Cloud PubSub,然后加载到 BigQuery
Clickhouse 专门用于实时 OLAP 分析,这是 Clickhouse 的主要用例之一
BigQuery 适用于更一般的数据分析用例
这种架构的好处是 Clickhouse 和 BigQuery 的结合提供了一个支持实时数据仓库的现代化数据平台。此外,将批处理工作负载从 Clickhouse 转移到 BigQuery 将降低总体成本,因为 BigQuery 存储比使用永久性磁盘底层的 Clickhouse 存储便宜得多。
优化选项 2
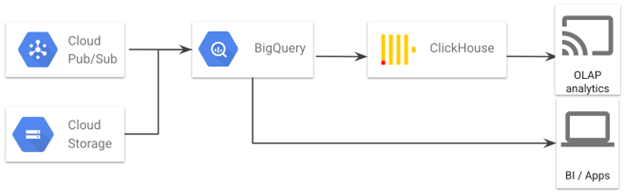
在优化选项 2 架构中,BigQuery 是集中式数据平台,而 Clickhouse 是下游数据集市平台之一,支持特定的 OLAP 分析用例。
批量数据在GCS 中暂存,然后加载到BigQuery。GCS 还可以作为 Clickhouse 的数据导出或备份目的地。
Cloud PubSub 用于将流式数据提取到 BigQuery 中
BigQuery 是集中的数据平台,承担了大部分的数据转换工作
处理后的数据从 BigQuery 加载到 Clickhouse,Clickhouse 为特定的 OLAP 分析用例提供服务
种架构的好处是 BigQuery 完成了所有数据处理工作,包括流式处理和批处理,而 Clickhouse 专门用于 OLAP 分析工作负载。采用这种架构,数据平台的运营成本将大幅降低,因为 BigQuery 承担了大部分工作,而且 BigQuery 是无服务器的,不需要维护。
部署指南
我们创建了一个自动化参考部署来帮助希望在 Google Cloud 上部署 Clickhouse 的客户。 参考部署提供默认配置,但客户可以配合提供的 Terraform 脚本来定义所需的集群节点和设置。
架构
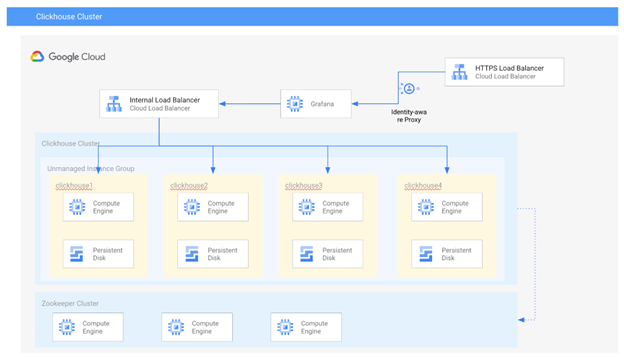
如上图架构所示,参考部署包括以下组件:
4节点 Clickhouse 集群,每个节点默认使用 n2-standard-16 实例类型和 2500GB PD-SSD
3节点 Zookeeper 集群,用于存储 Clickhouse 副本的元数据,每个节点使用 n1-standard-1 实例类型
1个安装了 Clickhouse 客户端和 Grafana 的管理节点,让管理员可以连接到 Clickhouse 集群进行监控和查询
1 个内部负载平衡,允许用户向 Clickhouse 集群提交查询
部署步骤
您需要按照以下步骤设置环境:
- 打开 Cloud Shell.
下载本教程的源代码,在 Cloud Shell 中运行:
转到 clickhouse-in-gce/terraform/clickhouse 文件夹:
创建 terraform.tfvars 文件, 将以下文本放入该文件中以设置您的项目 ID
运行以下命令初始化 Terraform:
应用更改,部署可能需要 10 分钟。
确认部署已成功执行。
您应该会在控制台中看到负载均衡器的域名和 IP 地址,如下例所示:
将 load_balancer_ip_address 和 service_account_email 的值保存到环境变量中:
访问 Clickhouse
访问 Clickhouse 的用户名是 default,密码存储在密钥 ch-default-pass-fb6fa0fb3c91 中。要连接到数据库,首先 ssh 进入其中一个数据库节点,在 Cloud Shell 中运行:
然后运行:
您将看到 clickhouse 问候消息和提示:
Grafana 集成
Grafana 是一个交互式可视化 Web 应用程序。我们将 Grafana 与 Clickhouse 集成,以提供 Web 界面来查询和监控 Clickhouse。
您可以按照以下步骤部署 Grafana。
在Cloud Shell中,转到 grafana-example 文件夹:
创建 terraform.tfvars 文件,放入以下文本并根据您的需要进行调整:
在Cloud Shell中运行
运行成功后,会看到如下输出:
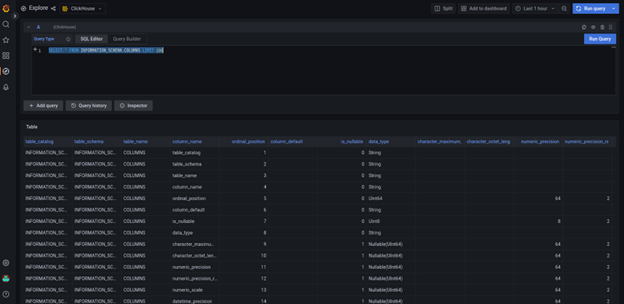
从浏览器的输出中打开 grafana_url,您将被带入 grafana 仪表板。您的角色应该是 grafana 的“管理员”。这个 Grafana 实例中已经有一个“Clickhouse”数据源。您可以使用它来查询数据库。例如,在左侧面板中选择“Explore”,然后选择“Clickhouse”作为数据源,在“SQL Editor”中输入以下 SQL:
Click "Run Query", you will the output as following:
与 Google Cloud 服务集成
我们有两个优化选项供您将 ClickHouse 与 BigQuery 一起使用。您还可以利用其他 Google Cloud 服务,例如,使用 GCS 进行数据暂存/导出,使用云监控进行 GCE 监控。
基本上,为了在您的数据管道中同时使用 ClickHouse 和 BigQuery,我们需要将数据从 ClickHouse 导出到 GCS,然后将它们导入 BigQuery。为了获得更快的查询速度,我们建议您在 BigQuery 中使用物化视图而不是表。如下图所示:
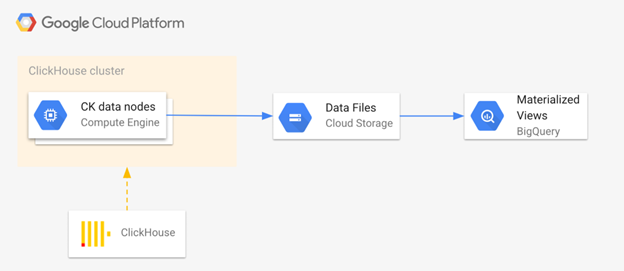
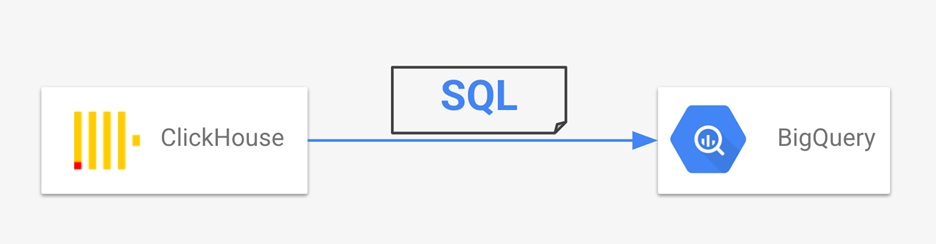
ClickHouse SQL语言大部分兼容ANSI SQL,而 BigQuery 完全兼容 ANSI SQL。因此,当我们将 ClickHouse 工作负载迁移到 BigQuery 时,所需的 SQL 翻译工作非常有限。
GCS 集成
用户可以将基于 GCS 的数据插入 ClickHouse,并通过 S3 表功能将 GCS 作为导出目的地。这是步骤:
设置 GCS 存储桶。
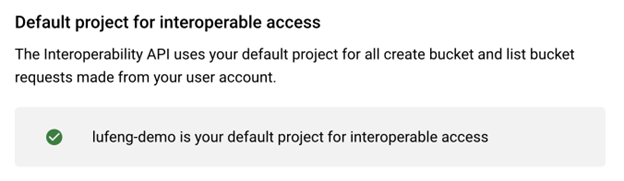
您必须为 GCS 互操作访问设置一个默认项目。此配置可在 GCS 设置 -> 互操作性中找到。
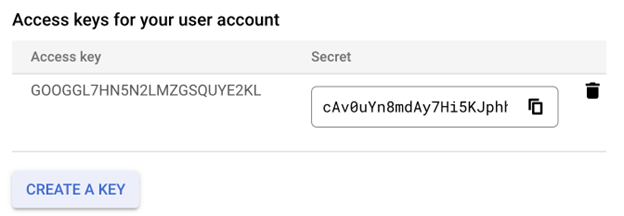
为帐户创建 HMAC 密钥。这可以在 GCS 设置 -> 互操作性中的用户帐户访问密钥部分中完成。
在 ClickHouse 中,将 S3 存储桶端点替换为 GCS 存储桶端点。这必须通过路径样式的 GCS 端点完成:https://storage.googleapis.com/BUCKET_NAME/OBJECT_NAME。
将 aws access key id 和 aws secret access key 替换为HMAC 密钥的相应部分。
下面是从 GCS 将数据导入 Clickhouse 的示例代码:
以下是将数据从 Clickhouse 导出到 GCS 的示例代码:
BigQuery 集成
当你把 Clickhouse 数据导出并存储在 Google Cloud Storage 后,您可以通过多种方式将这些数据导入 BigQuery。以 CSV 文件格式为例
手动导入
您可以按照本指南将 CSV 文件导入 BigQuery:
https://cloud.google.com/bigquery/docs/loading-data-cloud-storage-csv?hl=zh_cn
自动(计划)导入
如果您想定期(每年、每月、每天等)导入数据,您可以配置存储传输服务: https://cloud.google.com/bigquery/docs/cloud-storage-transfer
导入前进行转换
如果您需要在将数据提取到 BigQuery 之前进行一些数据转换(例如删除 NULL、将字符串转换为日期等),您可以利用 Google Cloud Dataflow 模板,可按照此处的指南进行操作:https://cloud.google.com/dataflow/docs/guides/templates/provided-batch#cloud-storage-text-to-bigquery
Cloud Monitoring 集成
我们可以利用 Google Cloud Monitoring 服务来监控 VM(ClickHouse 数据节点和 Zookeeper)的状态,包括 CPU、内存、磁盘和网络 IO。
在 Google Cloud 控制台的左侧窗格中选择 Monitoring,然后在主窗格中选择 VM Instance:
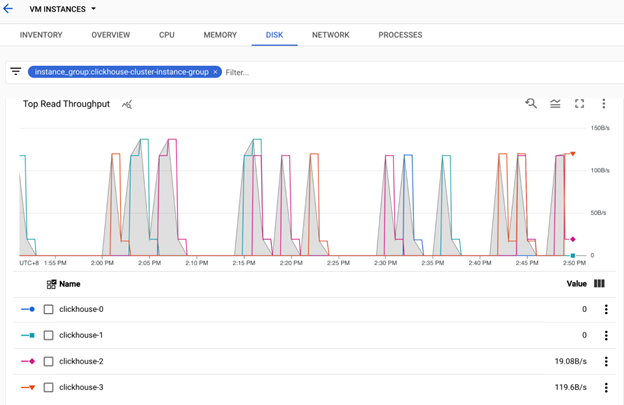
在这里,您将看到预先构建的报告和仪表板。您可以过滤 VM 列表以仅显示 ClickHouse 集群中使用的 VM。 下面是一些例子:

文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们