首页 > 资源 > 文章详情
Google Cloud Platform 上最简单的实时流数据管道
“使用谷歌的技术在 GCP 上构建流管道非常简单”
目录
第 1 步:构建客户端
第 2 步:数据注入
第 3 步:数据处理
第 4 步:数据落盘
第 1 步:构建客户端
Pubsub 的客户端可以是任何数据生产者,例如移动应用程序事件、用户行为埋点、数据库更改(CDC)、传感器数据等。
Cloud PubSub 提供许多客户端库,例如 Java、C#、C++、Go、Python、Ruby、PHP 和 REST API。
可以轻松地将客户端代码集成到数据生产者中,以将数据发布到 Cloud PubSub
这是Java客户端代码的示例
该客户端代码使用 forever while 循环模拟流事件。这些事件随后被转换为字节串。
使用我们需要发布的事件创建和初始化 PubSub 消息。
最后将事件发布到指定的 PubSub 主题。
发布事件后,我们输出pubsub分配和返回的已发布消息ID。

简单的 PubSub 客户端代码
现在转到您的 pubsub 客户端根项目并执行 maven 以运行客户端。
/* export service account prior to run below command to provide access to various services export GOOGLE_APPLICATIONS_CREDENTIALS=~/service_account.json*/ |
runnig maven 执行命令后,您可以查看有关已发布 message_id 的以下日志

在控制台上发布的消息 ID
现在让我们在第2步中检查消息是否确实发布到云 pubsub
第 2 步:数据摄取
通过单击云控制台左侧的菜单导航到 Cloud Pubsub
转到 Cloud Pubsub 并单击查看消息,如下所示
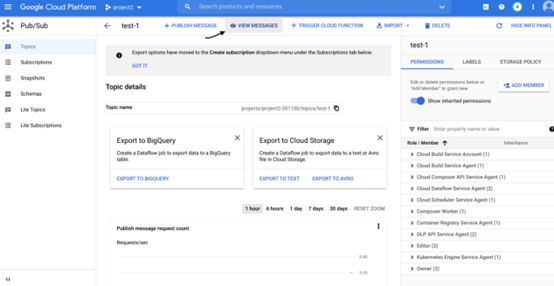
PubSub 控制台
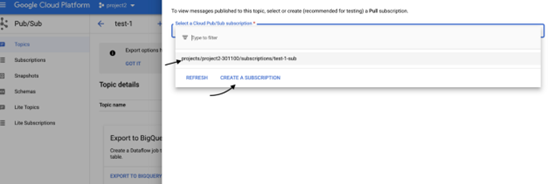
弹出弹窗供您选择订阅,如果您已有订阅,请选择订阅或为该主题创建一个。
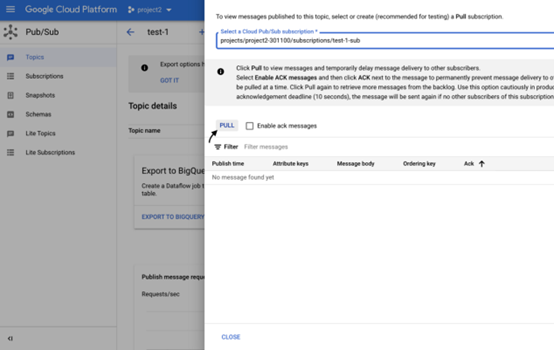
点击拉取消息,您应该可以看到发布在 Cloud Pubsub 主题中的消息
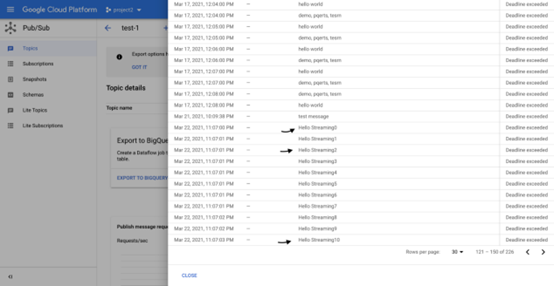
在 Cloud PubSub 中查看消息
现在我们验证了数据确实发布在 Cloud Pubsub 中。让我们在第3步中使用 dataflow 处理读取和处理记录。
第 3 步:数据处理
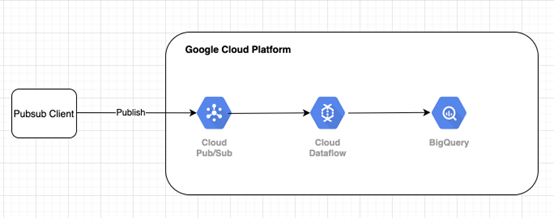
Cloud Dataflow 是统一的分布式处理引擎,它使用 apache beam sdk 来构建数据管道(批处理和实时)。
在本示例中,我们将构建实时管道。
目标是从 PubSub 读取发布的消息,验证记录并过滤“Hello Streaming”和 Interger ex。 “1”,最后写入 bigquery 中的目标表。

管道代码结构

数据处理逻辑
现在我们可以使用 maven 命令执行上述数据流管道
/* export service account prior to run below command to provide access to various services export GOOGLE_APPLICATIONS_CREDENTIALS=~/service_account.json*/$mvn -Pdataflow-runner compile exec:java -Dexec.mainClass=org.apache.beam.examples.PubsubToBQ -Dexec.args="--project=$PROJECT_ID --inputTopic=projects/$PROJECT_ID/topics/$TOPIC_NAME --stagingLocation=$CLOUD_STPRAGE_BUCKET --tempLocation=$CLOUD_STPRAGE_BUCKET/temp --runner=DataflowRunner --region=us-central1" |
执行此命令后,让我们检查 Dataflow 控制台以查看我们的管道
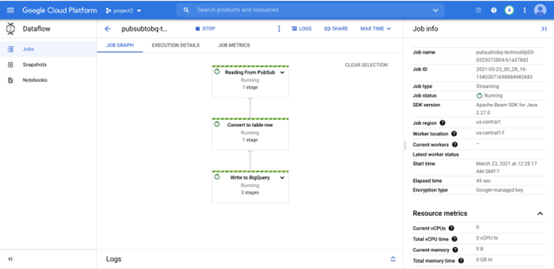
现在让我们从我们在第1步中构建的 pubsub 客户端生成一些消息
所有成功的消息都应该能够通过数据流流作业处理。 如果您单击 DAG 中的“Reading From PubSub”步骤,您可以看到它到目前为止已读取 218 个元素。

现在让我们进入下一步以验证数据流是否成功处理数据并将其写入 BigQuery。
第 4 步:数据落盘
通过单击 Google Cloud 控制台中的菜单并单击左侧菜单栏中的 BigQuery 转到 BigQuery。
如果我们导航到我们的目标表 hello_string ,我们将看到确实有 218 个元素流式传输到 BigQuery 的字符串缓冲区,这验证了发布到 pubsub 的所有元素都已成功写入 BigQuery。

现在让我们深入了解表格以查看数据。
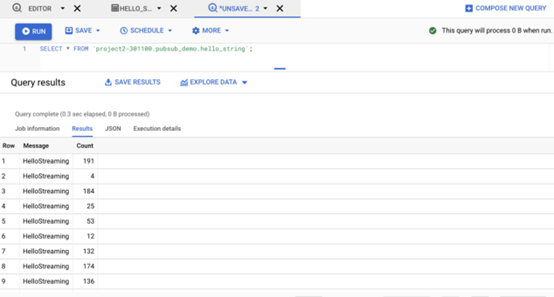
数据已成功写入 BigQuery。 您还可以通过运行以下查询来验证最大计数为 217(因为消息计数为 0 索引)
SELECT max(Count) FROM `$PROJECT_ID.$TABLE_NAME.hello_string`; |
结论
在 GCP 中编写实时流式传输管道并不困难。 由于我们在演示中使用的所有服务都是无服务器的,因此无需安装即可轻松开始构建 POC。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们