首页 > 资源 > 文章详情
GCP BigLake 简介

BigLake 是 Google 底层数据访问引擎的名称,该引擎用于访问存储在 BigQuery 或 Google Cloud Storage (GCS) 上的结构化数据。这个概念是数据所有者将他们的数据存储在数据仓库(例如 BigQuery)或数据湖(例如 GCS)中。 由于数据存储在不同的位置,它们的访问模式和属性也不同。例如,有些分析可以访问存储在数据仓库中的数据,而不能访问存储在数据湖中的数据。BigLake 提供了一个平台,能够通过单一的接口和语义来访问数据,无论数据物理位于何处或使用何种格式存储数据,都可以在该平台上实现统一性和通用性。
Google 于 2022 年 4 月发布了 BigLake 的初始版本。您可以通过跟踪文档来查看最新添加或更改的内容。
下图展示了我对 BigLake 的看法。 首先是存储在 BigQuery 和 GCS 中的数据。 在 GCS 中,数据应采用结构化格式,例如 CSV、JSON、Parquet、ORC 和 Avro。
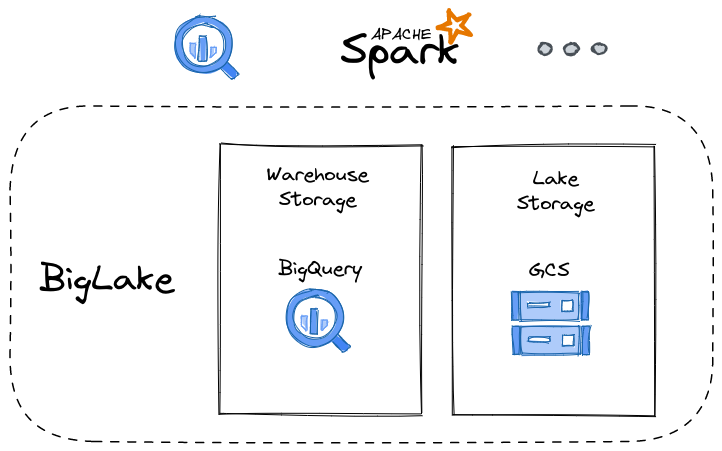
接下来,我们可以定义到底层数据的映射来通过 BigLake 公开这份数据。 映射通过 BigQuery 定义。让我们展开这个概念。 假设您有 BigQuery 表。在这种情况下,您无需再做任何事情,因为您已经可以立即访问表中的数据。现在请想象另外一种情况,您将数据存储在 GCS 中。 我们现在要做的是创建一个看起来像 BigQuery 的表,但将该表的数据源指向底层 GCS 存储。 完成之后,我们就可以从该 BigQuery 表中查询或检索数据,BigLake 负责检索和提供数据。我们先在这里暂停一下,现在能够看到我们可以使用 BigQuery 接口访问数据,并且不需要知道数据实际位于何处。 数据是在原生 BigQuery 表中还是存储在云存储中,这些对于我们消费者来说是隐藏的。
Apache Spark 等各种数据处理系统都具备 BigQuery 连接器。 这意味着我们可以将 BigLake 前端数据呈现给支持 BigQuery 接口的任何系统。
如果您精通 BigQuery,您现在可能会有些摸不着头脑。可能您会说“BigQuery 不是已经有外部表的这个形式的概念了吗?” 您是绝对正确的。外部表的想法已经在 BigQuery 中出现了很长一段时间。与 BigLake 一样,外部表为存储在 BigQuery 之外的底层数据提供了 BigQuery 接口,包括 GCS、Drive、Google Sheets 等。BigLake 目前提供的是一种替代接口,旨在提供统一的数据仓库/数据湖接口。 在最初的 BigLake 函数集中,我们立即获得了 BigQuery 外部表无法实现的能力……我们有机会在行和列级别执行更细粒度的安全性。为了使这个概念变得清晰,我们现在可以将结构化数据存储在 GCS 中,这样对特定行或列的访问可以限制为授权请求。此功能以前仅适用于BigQuery 管理的原生表。
与外部表的另一个区别是,要查询映射到外部源的 BigQuery 表,提交查询的身份通常需要具备对底层数据源的读取权限。 例如,映射到 GCS 对象的外部表要求执行查询的身份需要表权限和相应的 GCS 对象权限。通过使用 BigLake,我们授权 BigLake 拥有 GCS 对象权限,然后根据 BigQuery 权限唯一控制允许或拒绝运行查询的身份。
现在让我们了解一下 BigLake 的一些用法,看看实际情况是怎样的。
1. 创建一个 GCP 项目并记下它的项目号。 我们将使用它作为 GCS 存储桶的唯一 ID。
2. 启用以下 GCP API(如果尚未启用)
BigQuery Connection API
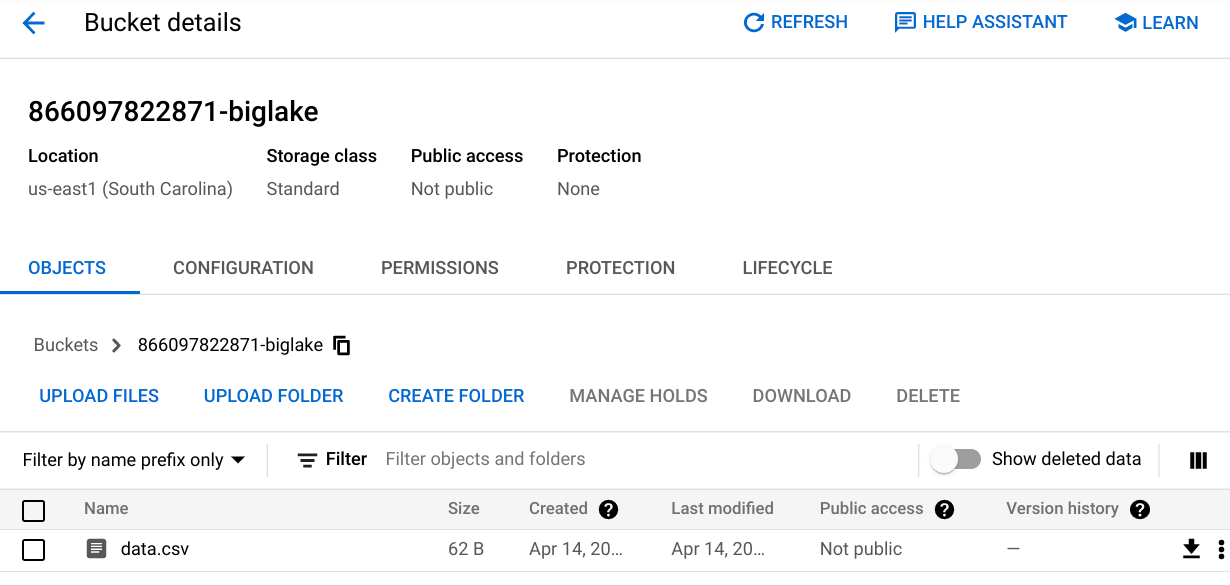
3. 创建名为 [PROJECT_NUMBER]-biglake 的GCS 存储桶, 并在 us-east1 中创建它。
4. 创建一个包含 CSV 数据的本地文件。 在这个例子中,我们的文件命名为 data.csv,它包含:
country,product,price
US,phone,100
JP,tablet,300
UK,laptop,200
将此文件上传到 GCS 存储桶中:
5. 在 GCP 控制台中打开 BigQuery 工作台
6. 点击+ 添加数据然后点击外部数据源
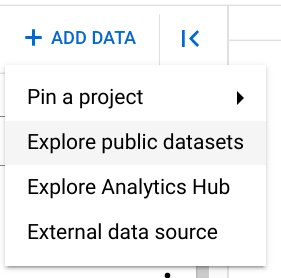
这时将在右侧弹出一个面板。
7.填写外部数据源面板

8. 打开新添加的外部连接的连接详细信息

记下生成的服务帐户(服务帐户 ID)。
9. 授予服务帐号读取 GCS 存储桶的权限,授予它 Storage Object Viewer 角色。

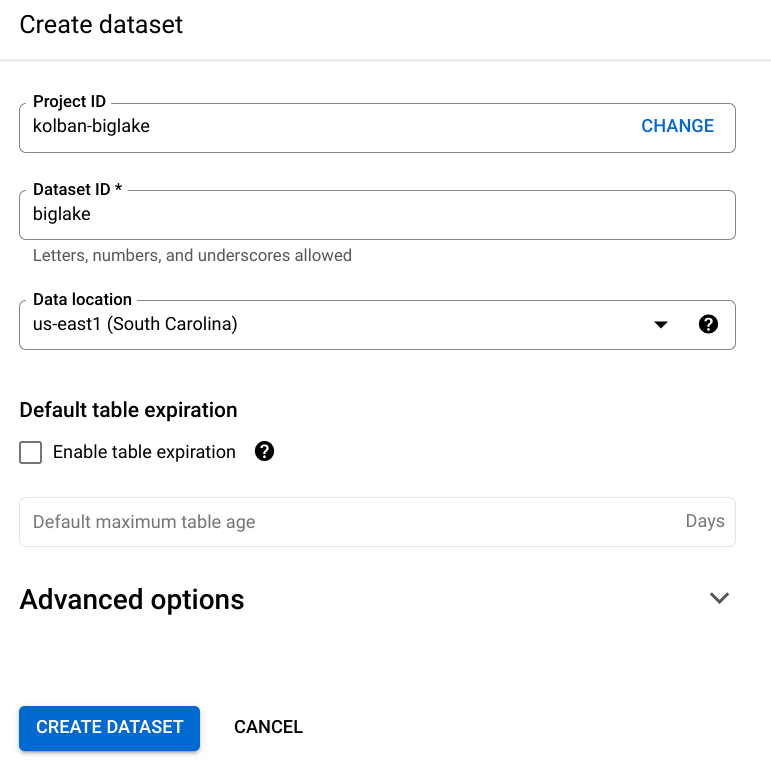
10. 创建 BigQuery 数据集:
11.在新数据集中创建一个 BigLake 表:
我们选择数据集,然后从其菜单中选择创建表:

在出现的面板中,我们选择:
数据来源应为 Google Cloud Storage
应从中检索数据的 GCS 对象
文件格式为 CSV
我们希望创建的 BigQuery 表的名称。在这个例子中,我们称之为 biglake
用于创建基于 BigLake 的表并使用连接 ID 的复选框。这是核心概念。
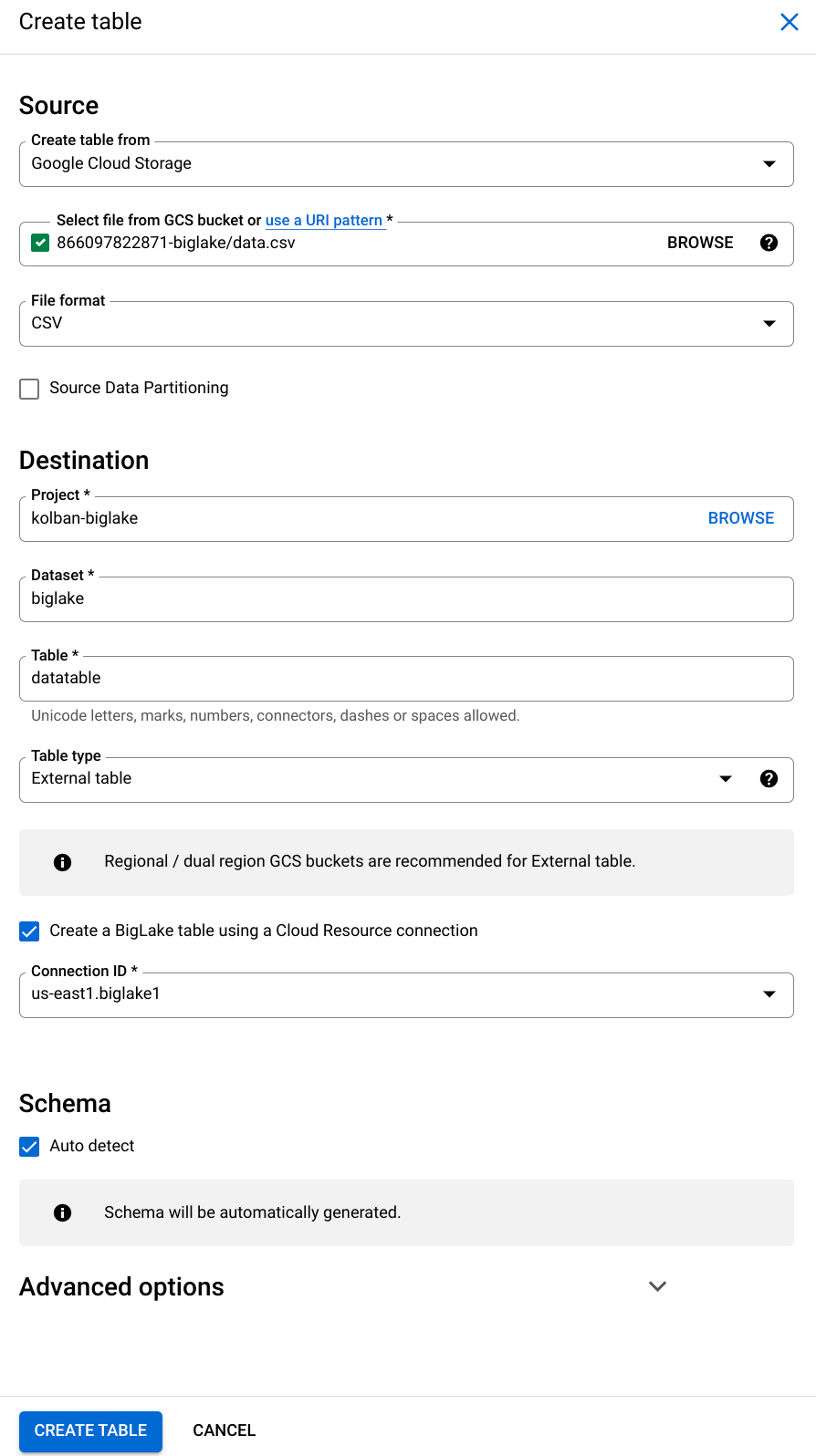
创建表后,我们可以看到它的定义。 请注意,它被标记为 BigLake。
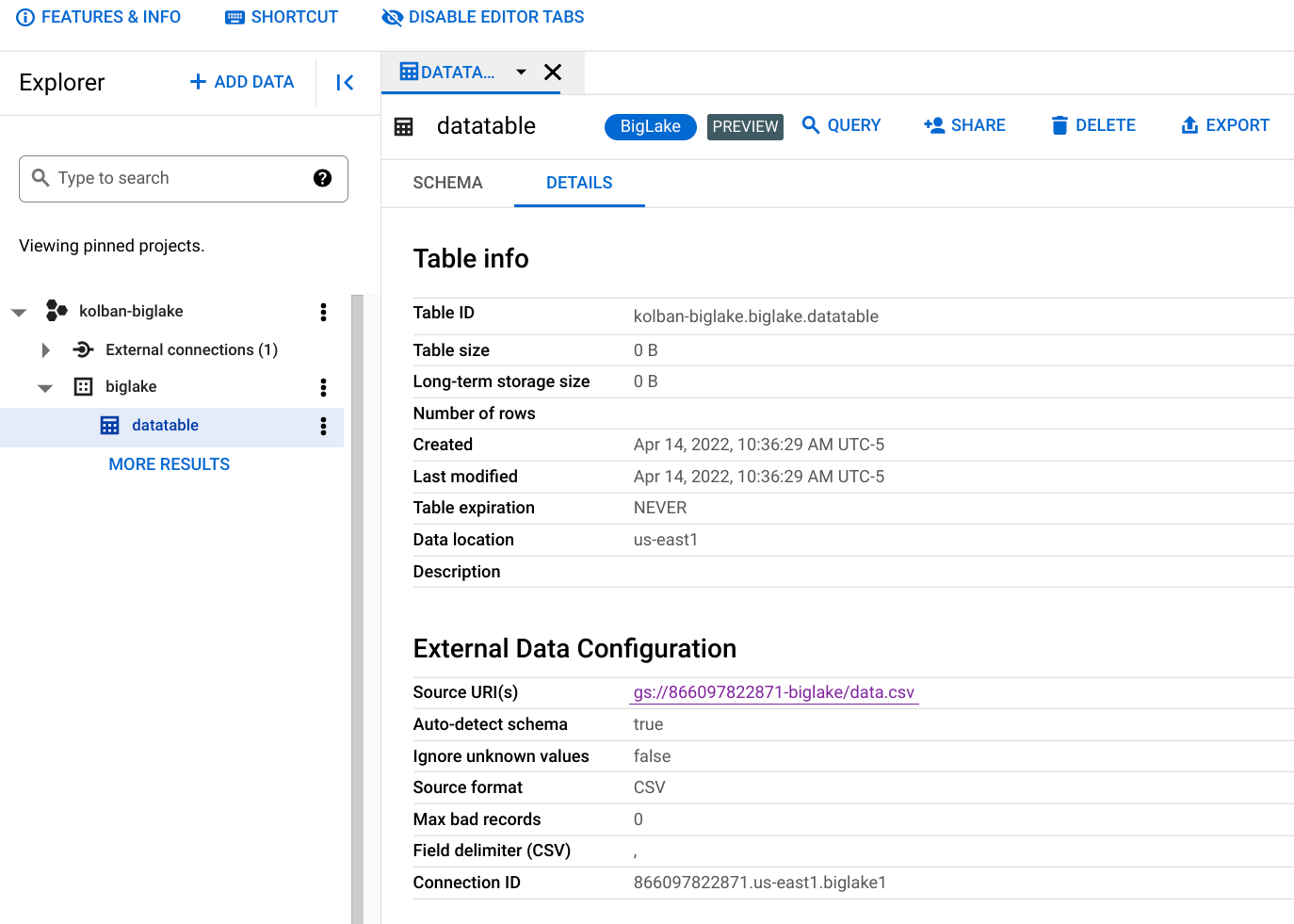
12.运行一个简单的查询
如果我们现在从 BigQuery 工作台中运行查询,我们会看到我们返回了数据。 如果我们要更改 GCS 中的 CSV 文件,我们会发现后续查询将返回最新数据。
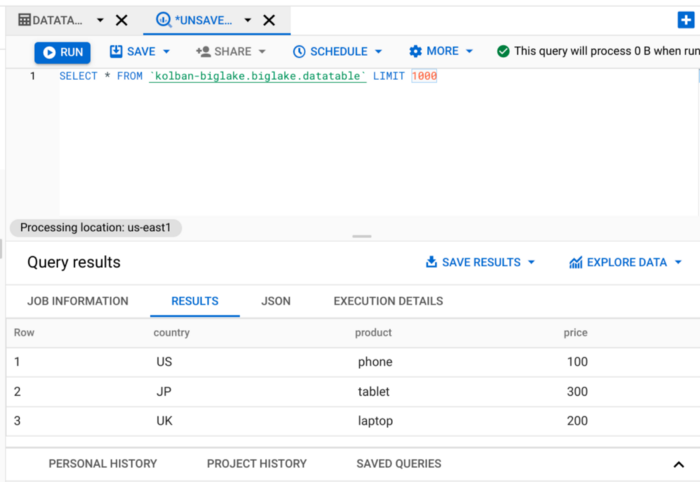
13.应用行级安全策略。
我们想测试行级安全性。 为此,我们运行以下 SQL 语句:
CREATE OR REPLACE ROW ACCESS POLICY mypolicy ON biglake.datatableGRANT TO ("user:[YOUR IDENTITY]")FILTER USING (country = "US");您必须在 GRANT TO 部分更改您自己的身份。
14.重新运行数据访问
次我们看到我们被限制只能看到我们有权看到的行。这表明行级安全性现在生效。
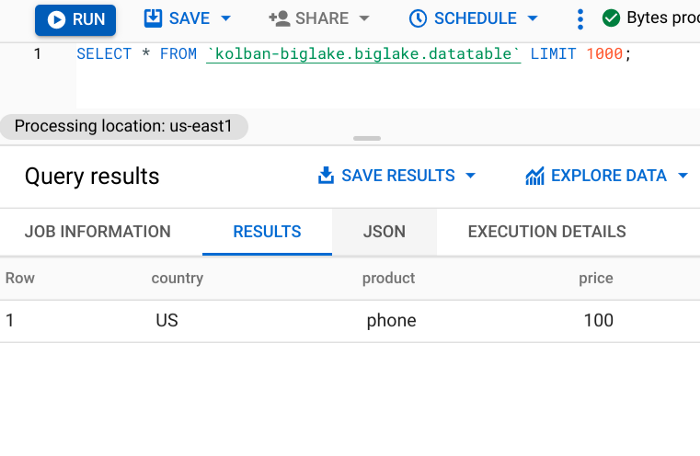
这不是 BigQuery 外部表提供给我们的选项; 我们只能使用 BigLake 技术来实现这一点。
如果我们要在 GCS 中的 CSV 文件中添加一个允许我们查询它的新行,它确实会被返回:
到目前为止,我们已经展示了通过 BigQuery 查询访问 BigLake 表,但我们也可以通过 Spark 等其他技术访问 BigLake 表。 例如,这里是一个查询 BigLake 表的 Spark 片段:
from pyspark.sql import SparkSessionspark = SparkSession.builder .appName('BigLake Query') .config('spark.jars','gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12–0.24.2.jar') .getOrCreate()df = spark.read .format('bigquery') .load('biglake.datatable') df.show()文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们