首页 > 资源 > 文章详情
Dataflow,数据分析的支柱
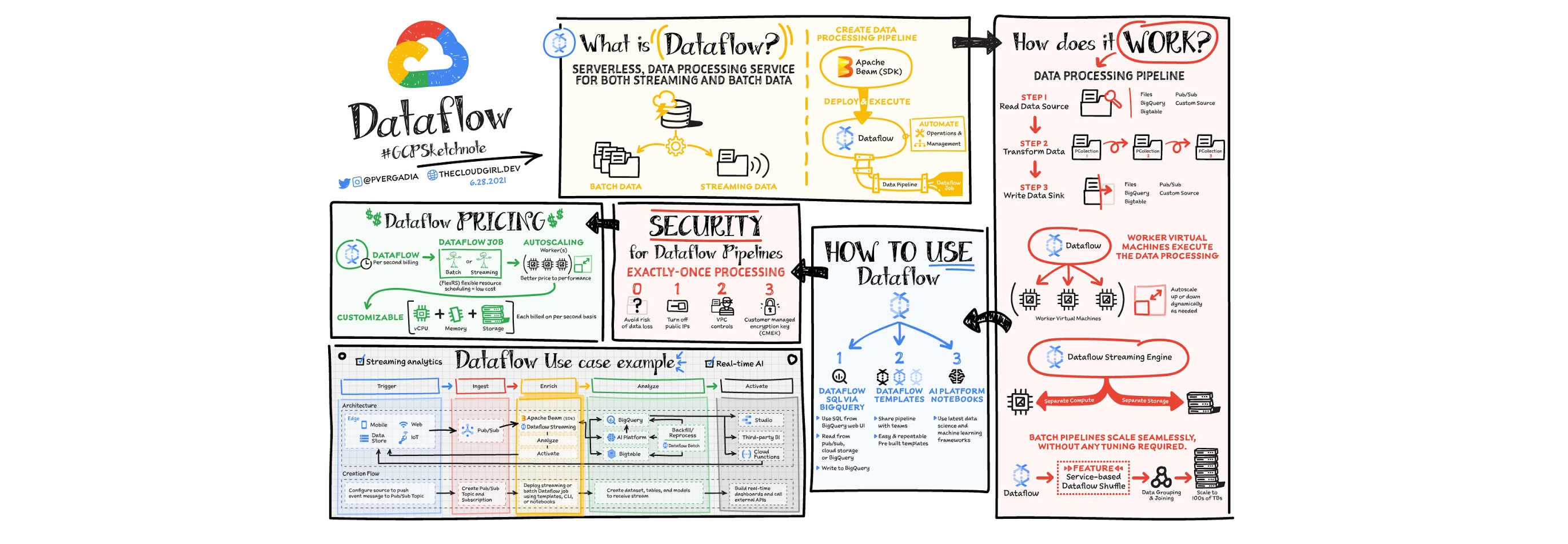
数据是从网站、移动应用程序、物联网设备和其他工作负载实时生成的。捕获、处理和分析这些数据是所有企业的首要任务。但是,来自这些系统的数据通常不是有利于下游系统分析或有效使用的格式。这就是 Dataflow 的用武之地! Dataflow 用于处理和丰富批处理或流数据,用于分析、ML 或数据仓库等用例。
Dataflow 是一种无服务器、快速且经济高效的服务,支持流式处理和批处理。它为使用开源 Apache Beam 库编写的处理作业提供了可移植性,并通过自动化基础设施配置和集群管理来消除数据工程团队的运营开销。
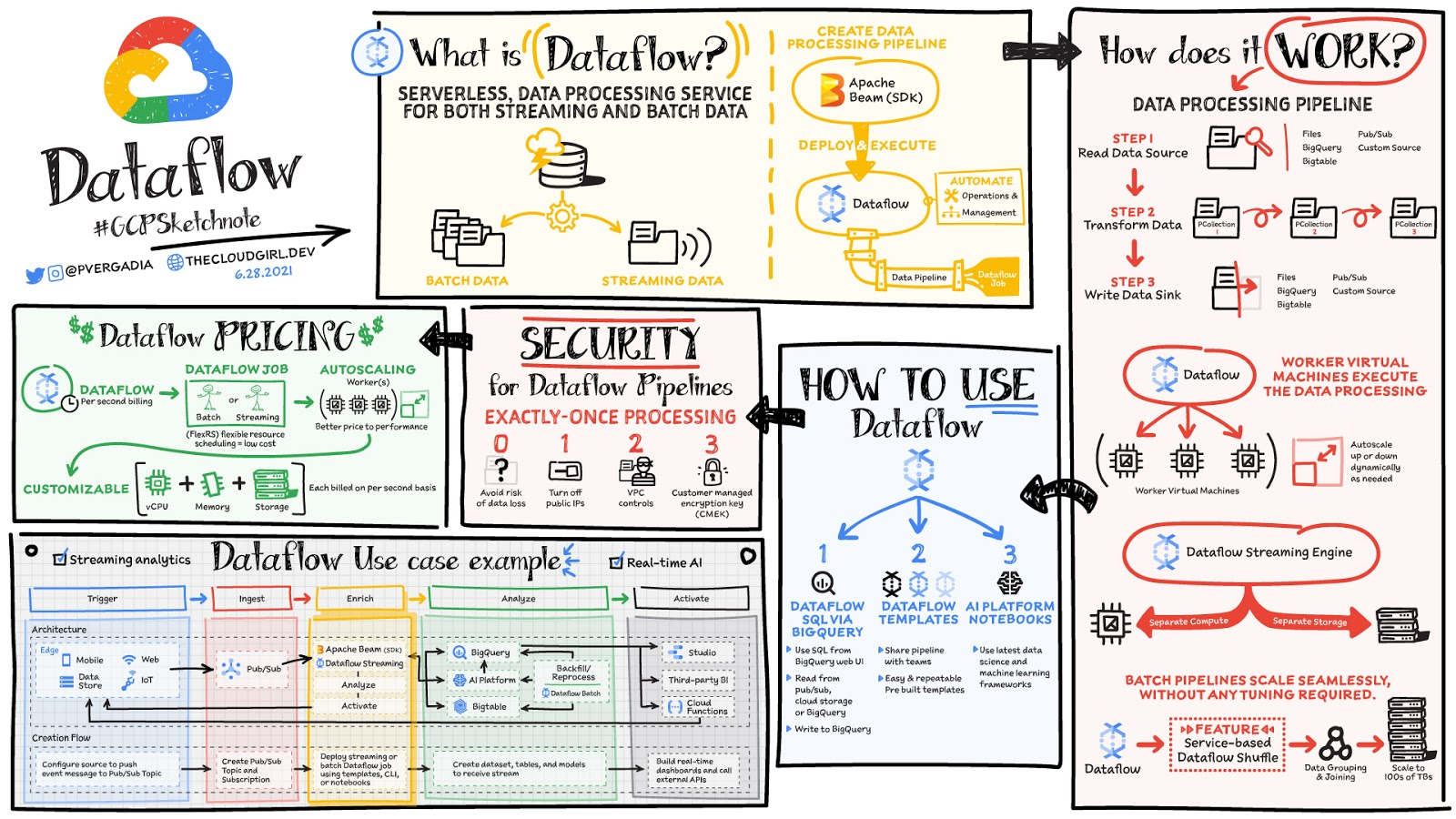
数据处理是如何工作的?
一般来说,数据处理管道包括三个步骤:从源读取数据,对其进行转换,然后将数据写回接收器。
数据从源读取到 PCollection。 “P”代表“并行”,因为 PCollection 旨在分布在多台机器上。
然后它对 PCollection 执行一项或多项操作,这些操作称为变换。每次运行转换时,都会创建一个新的 PCollection。那是因为 PCollection 是不可变的。
执行完所有转换后,管道将最终的 PCollection 写入外部接收器
使用 Apache Beam SDK 以您选择的语言(Java 或 Python)创建管道后。您可以使用 Dataflow 部署和执行称为 Dataflow 作业的管道。 Dataflow 之后分配 worker 虚拟机来执行数据处理,你可以自定义这些机器的形状和大小。而且,如果您的流量模式非常高,Dataflow 自动缩放会自动增加或减少运行您的作业所需的工作器实例的数量。 Dataflow 流引擎将计算与存储分离,并将部分管道执行移出工作虚拟机并进入 Dataflow 服务后端。这改善了自动缩放和数据延迟!
如何使用 Dataflow
可以使用云控制台用户界面、gcloud CLI 或 API 创建 Dataflow 作业。 创建工作有多种选择。
Dataflow 模板提供一系列预建模板,并可选择创建您自己的自定义模板!然后,您可以轻松地与组织中的其他人共享它们。
Dataflow SQL 让您可以使用您的 SQL 技能直接从 BigQuery, 网络用户界面开发流式传输管道。您可以将来自 Pub/Sub 的流式数据与 Cloud Storage 中的文件或 BigQuery 中的表连接起来,将结果写入 BigQuery,并构建实时仪表板以进行可视化。
使用Dataflow 界面中的 Vertex AI 笔记本,您可以使用最新的数据科学和 ML 框架构建和部署数据管道。
Dataflow 内联监控使您可以直接访问作业指标,以帮助在步骤和工作人员级别对管道进行故障排除。
Dataflow 治理
使用 Dataflow 时,所有数据都在静态和传输中进行加密。为了进一步保护数据处理环境,您可以:
关闭公共 IP 以限制对内部系统的访问。
利用有助于降低数据泄露风险的 VPC 服务控制
使用您自己的自定义加密密钥客户管理的加密密钥 (CMEK)
结论
对于需要处理和丰富下游系统(如分析、ML 或数据仓库)的批处理或流数据,Dataflow 是一个很好的选择。例如:Dataflow 将流事件引入 Google Cloud 的 Vertex AI 和 TensorFlow Extended (TFX),以支持预测分析、欺诈检测、实时个性化和其他高级分析用例。如需更深入地了解 Dataflow,请查看文档。想要进一步探索? 在 Coursera 和 Pluralsight 上学习 Dataflow 专业。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们