首页 > 资源 > 文章详情
BigQuery 跨区域复制介绍:增强数据的地理冗余
地理冗余是在云端设计弹性数据湖架构的关键考量要素之一。客户在不同地理位置间复制数据的一些用例包括:提供低延迟读取(数据更接近终端用户)、遵守法规要求、将数据与其他服务放在同一位置、以及保持任务关键型应用程序的数据冗余。
BigQuery 已将数据副本存储在数据集地区的两个不同 Google Cloud 区域中。在所有区域中,各区域之间的复制均为同步双重写入。在发生软(电源故障、网络分区)或硬(洪水、地震、飓风)区域故障时,这可确保数据不会丢失,且能够让您几乎立即恢复运行。
随着预览版跨区域数据集复制功能的推出,我们将再向前迈进一步。这项功能支持您跨云端区域轻松复制任何数据集,包括持续更改。除现有的复制用例外,您还可以使用跨区域复制功能,将 BigQuery 数据集从一个源区域迁移至另一个目标区域。
它是如何运行的?
BigQuery 为跨区域复制提供主要配置和辅助配置:
主要区域:当您创建数据集时,BigQuery 会将选定区域指定为主副本的位置。
辅助区域:当您向选定区域添加数据集副本时,BigQuery 会将其指定为辅助副本。辅助区域可以是您选择的区域。辅助副本可以不止一个。
主副本是可写的,而辅助副本是只读的。对主副本的写入会异步复制到辅助副本。在每个区域内,数据在两个区域内冗余存储。Google Cloud 网络一直保有网络流量。
虽然副本位于不同的区域,但名称是相同的。这意味着在引用不同区域的副本时,无需对查询进行更改。
下图显示的是复制数据集时的复制过程:
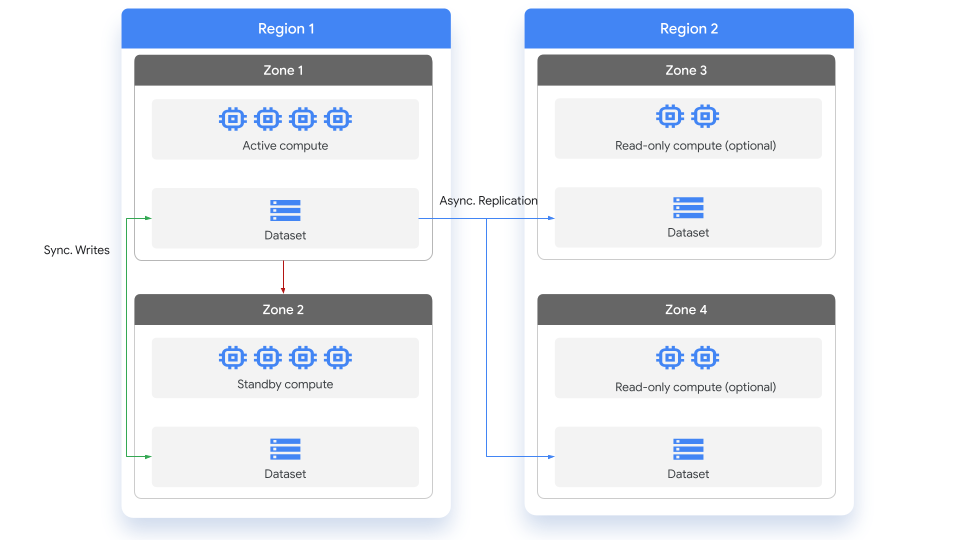
复制操作
以下工作流展示的是如何为 BigQuery 数据集设置复制。
为给定数据集创建副本
要复制数据集,请使用 ALTER SCHEMA ADD REPLICA DDL 语句。
您可以向每个区域或多区域内的任何数据集添加一个副本。添加副本后,需要一段时间才能完成初始复制操作。在复制数据的过程中,您仍然可以运行引用主副本的查询,查询处理能力不受影响。
-- Create the primary replica in the primary region. CREATE SCHEMA my_dataset OPTIONS(location='us-west1'); -- Create a replica in the secondary region. ALTER SCHEMA my_dataset ADD REPLICA `us-east1` OPTIONS(location='us-east1'); |
要确认辅助副本已成功完成创建的状态,您可以在 INFORMATION_SCHEMA.SCHEMATA_REPLICAS 视图中查询 creation_complete 列。
-- Check the status of the replica in the secondary region. SELECT creation_time, schema_name, replica_name, creation_complete FROM `region-us-west1`.INFORMATION_SCHEMA.SCHEMATA_REPLICAS WHERE schema_name = 'my_dataset'; |
查询辅助副本
完成初始创建后,即可针对辅助副本运行只读查询。为此,请在查询设置或 BigQuery API 中将任务位置设置为辅助区域。如果不指定位置,BigQuery 则自动将查询路由到主副本的位置。
-- Query the data in the secondary region.. SELECT COUNT(*) FROM my_dataset.my_table; |
如果要使用 BigQuery 的容量预留功能,则需要在辅助副本的位置进行预留。否则,将使用 BigQuery 的按需处理模式进行查询。
将辅助副本提升为主副本
要将副本提升为主副本,请使用 ALTER SCHEMA SET OPTIONS DDL 语句并设置 primary_replica 选项。必须在查询设置中将任务位置明确设置为辅助区域。
ALTER SCHEMA my_dataset SET OPTIONS(primary_replica = 'us-east1') |
几秒钟后,辅助副本变为主副本,并且可以在新位置运行读写操作。同样,主副本也变为辅助副本,且仅支持读取操作。
删除数据集副本
要删除副本并停止复制数据集,请使用 ALTER SCHEMA DROP REPLICA DDL 语句。如果想要通过复制将数据集从一个区域迁移至另一个区域,请在将辅助副本提升为主副本后删除副本。这并非必要步骤,但如果您不需要超出迁移需求的数据集副本,则这一步很有用。
ALTER SCHEMA my_dataset DROP REPLICA IF EXISTS `us-west1`; |
开始上手
我们非常高兴为 BigQuery 推出预览版的跨区域复制功能,该功能有助于增强地理冗余,并支持区域迁移用例。展望未来,我们将推出基于控制台的用户界面,用于配置和管理副本。我们还将提供跨区域灾难恢复(DR)功能,借以拓展跨区域复制,以便在全部区域均中断运行的极少数情况下保护您的工作负载。关于 BigQuery 和跨区域复制的更多信息,另请参见 BigQuery 跨区域数据集复制快速入门。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们