首页 > 资源 > 文章详情
AlloyDB, 一种 PostgreSQL 兼容的数据库云服务
AlloyDB 是一个与 PostgreSQL 100% 兼容的全托管数据库,能够同时满足事务型以及分析型的工作负载,提供企业级的数据库解决方案。
与标准的开源数据库 PostgreSQL 相兼容,一方面可以使用户在数据库的使用上,快速上手,减少学习和修改 code 的成本;另外一方面,活跃的 PostgreSQL 社区可以与产品互相促进,为用户持续提供更好的数据库产品和功能。
从技术上来说,AlloyDB 建立在 Google Cloud 现有的基础架构之上。通过使用计算和存储分离的方式,使用户可以灵活的对计算和存储进行扩展;再加上智能缓存,AI/ML 驱动的自动化管理,使 AlloyDB 在 PostgreSQL 中提供了无与伦比的性价比:事务工作负载的速度提高了 4 倍,分析查询速度提高了 100 倍,而且价格简单且可预测,没有额外的 IO 费用。AlloyDB 提供广泛的数据保护和行业领先的 99.99% 可用性 SLA,包括维护。
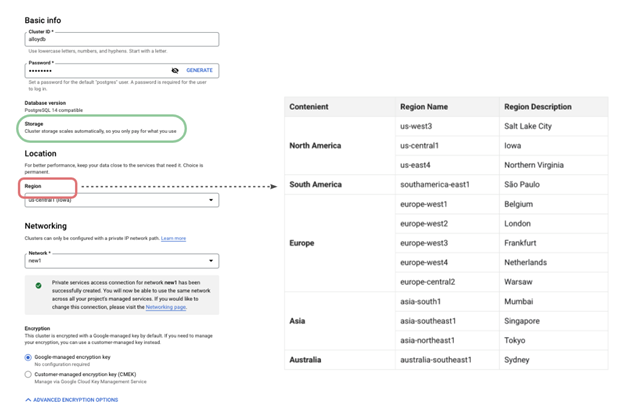
用户可以在登录到 Google Cloud 控制台后,在左侧的导航栏或者搜索栏中直接键入 ”AlloyDB“,进入到 AlloyDB 的服务页面,并进一步点击创建集群。

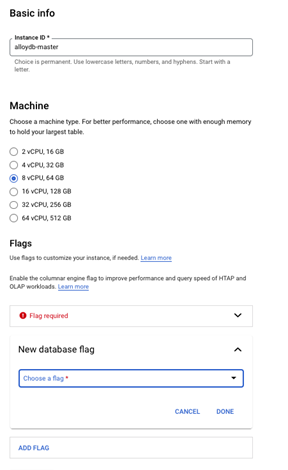
AlloyDB 提供多种集群类型。用户既可以创建单独的配置了高可用的计算实例,也可以为集群配置一个或者多个读取池节点(read pool),满足工作负载读写分离的需求。
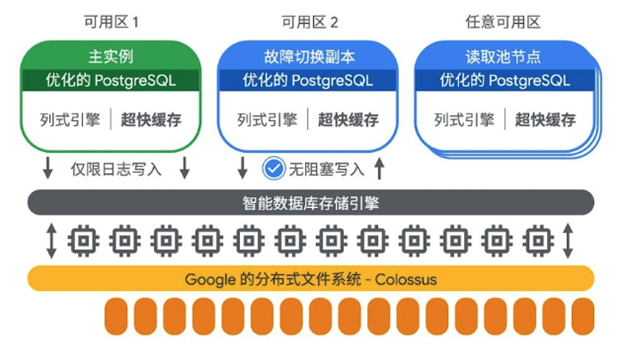
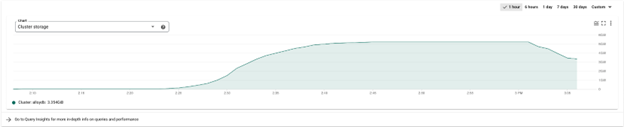
在下图所展示的 AlloyDB 架构中,主实例配备了一个独有的用于满足高可用的故障切换副本。主实例与故障切换副本分别部署在不同的可用区,在主实例出现故障或者需要维护时,或者所在的可用区出现故障时,监控系统能够在 60 秒内自动检测到故障,并进行快速切换对故障进行恢复,切换所导致的停机时间不超过 10 秒。
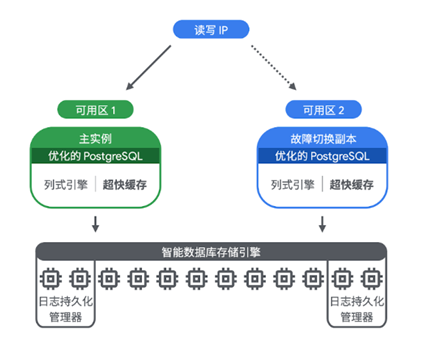
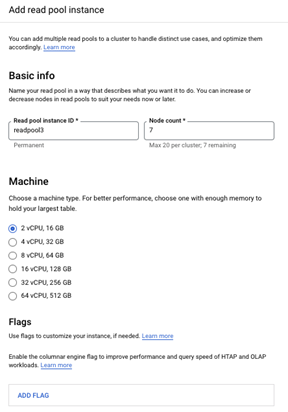
用户可以根据工作负载,创建一个或者多个读取池节点,将不同的负载指向不同的读取池,AlloyDB 支持最多 20 个读取节点。例如,创建了三个读取池,第一个读取池有 3 个节点,第二个有 10 个节点,第三个有 7 个节点,总共 20 个读取节点。
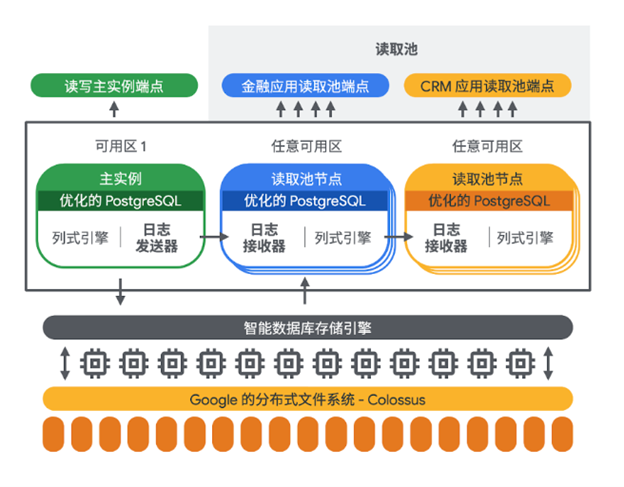
为了最大程度优化数据库架构,提供更好的性能,AlloyDB 在架构上做了非常深层的计算存储分离。这种架构不仅是计算层和存储层能够各自根据负载进行扩展,还进一步通过构建智能数据库存储引擎,利用日志处理系统(Log Processing System, LPS)将操作卸载到存储层,从而消除 I/O 瓶颈。而日志处理系统本身也会根据负载做自动扩展,从而提供快速、可预测的性能。同时为了减少主实例与读取池节点之间的延迟,主实例除了会将日志通过智能数据库存储引擎持久化到 Google 的分布式文件系统 Colossus 之外,还会将 PostgreSQL 中的 Write-Ahead Logging (WAL)同步传输到读取池节点,方便读取池根据 WAL 及时快速地更新内存中的缓存,在保证数据一致性,提供给终端用户最新的正确结果的同时,减少从存储层更新缓存的消耗。
AlloyDB 提供完全自动扩展的存储。数据库的存储会随着使用自动进行扩展和收缩,无论是扩展亦或是收缩,都不会产生 downtime。从架构图我们也可以看到,所有的 AlloyDB 实例,主实例或者读取池的节点,都指向同一个集群存储,而该集群存储会将数据在三个可用区中完整备份,保证数据的可用性和持久性。
AlloyDB 提供从 2 vCPU, 16GB 到 64 vCPU, 512GB 的机型选择,同时提供多达 20 个读节点的读取池配置,因此,您可以自由扩展到一个最多超过 1000 vCPU 的超大数据库集群。除此之外,由于 AlloyDB 完全兼容 PostgreSQL,在公测版本中,AlloyDB 支持超过 175 个 PostgreSQL Flag 以及超过 50 个 PostgreSQL 扩展。不同的读取池分配不同的 IP 连接地址,可以配置不同的 Flag,精准适配不同的工作负载。
在现代数据库使用中,除了纯事务性的工作负载,越来越多的用户需要在数据库上进行分析查询。这些查询操作涉及大量数据的扫描、不同表之间的连接,以及复杂的聚合操作。 在数据库上同时满足事务性和分析性的需求一直是 DBA 们需要谨慎平衡的事情,一方面需要创建索引,优化语句来确保足够的查询性能,另一方面,这些索引不仅会增加管理的复杂性,还会影响事务的处理性能。在分析上缓慢的查询性能导致终端用户无法及时得洞察数据的变化,进而阻碍业务上的快速调整反应。
AlloyDB 中内嵌的列式引擎,对这一困境给出了更好的解决方法。该技术将频繁查询的数据保存在内存中的列格式中,以实现更快的扫描、连接和聚合。而 AlloyDB 中的嵌入式 AI/ML 技术,可以自动感知工作负载的变化,将数据在行格式与列格式之间自动组织转化。查询计划器在基于列和基于行的执行计划之间进行智能选择,从而保持事务性能。这使 AlloyDB 能够以最小的管理开销为各种查询提供出色的性能,同时也能够使用户在不需要更改架构,应用程序或者 ETL 的前提下,将分析查询的速度相对于标准 PostgreSQL 提高 100 倍。
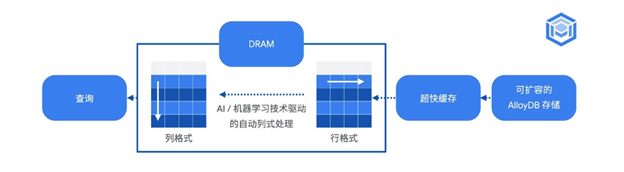
列式引擎是以读取池为工作范围的,也就是说,用户可以在单个读取池层级上通过开启 google_columnar_engine.enabled 使列式引擎工作。针对不同的读取池,可以灵活的选择是否开启,以及配置相关 Flag。除了实例内存外,AlloyDB 还自动配置免费的超高速缓存。通过使用自适应算法和 ML 来进行 PostgreSQL 的 vacuum 管理、存储和内存管理、数据分层和分析加速。根据工作负载的变化,自动智能的在内存,超快缓存,以及持久化存储之间组织数据,提供更好的性能,以及更优的性价比。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们