首页 > 资源 > 文章详情
Google Cloud 展示了全球最大的跨 50000 多个 TPU v5e 芯片的大语言模型分布式训练作业
随着生成式 AI 的兴起,借助数千亿的参数和数万亿的训练标记,基础大语言模型(LLM)的规模呈指数级增长。
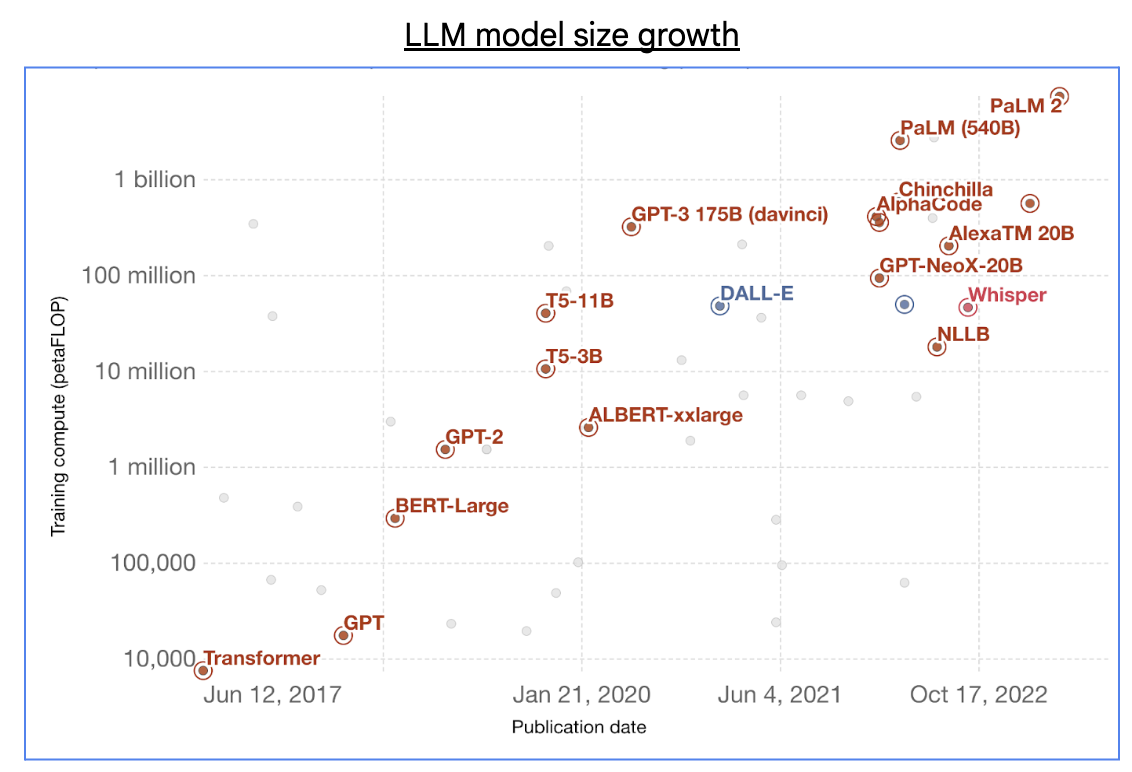
资料来源: “用于训练著名智能系统的计算”,One World Data
训练这类大型 LLM 需要成百上千 exa-FLOP(10^18 FLOP)的 AI 超级计算能力,通常分布在包含数万个 AI 加速器芯片的大型集群中。然而,利用大规模集群进行分布式 ML 训练会面临许多常见且关键的技术挑战。
1. 编排:用于分布式训练的软件堆栈需要管理所有这些芯片,并尽可能高地扩展以加快训练时间。这个堆栈还需要可靠、容错和有弹性,以确保训练进度。
2. 编译:随着训练的进行,芯片之间发生的计算和通信需要由高性能编译器有效管理。
3. 端到端优化:大规模的分布式训练需要对 ML 训练堆栈和端到端 ML 训练工作流程有深入的专业知识,从存储和计算,到内存和网络等方面。
Google Cloud TPU Multislice Training
为了应对上述在编排、编译和端到端优化方面的分布式训练挑战,我们宣布 Cloud TPU Multislice Training 正式上线。这种全栈训练产品支持 TPU v4 和 v5e,从头开始构建,旨在实现可扩展性、可靠性和易用性,以实现端到端的 ML 训练优化。使用 Multislice,您可以充分利用 Google 高性价比、多功能且可扩展的 Cloud TPU,高效且大规模地训练 ML 模型。

Cloud TPU Multislice Training 具有以下关键功能:
1. 强大的编排和可扩展性:以可靠且容错的方式,在训练工作流程中跨数万个 TPU 芯片扩展大规模模型训练。
2. 高效的编译:使用 XLA 编译器自动管理计算和通信,最大限度地提高性能和效率。
3. 灵活的端到端训练堆栈:为流行的 ML 框架(如 JAX 和 PyTorch)、易于使用的参考和库提供一流的支持,并支持各种模型架构,包括 LLM、扩散模型和 DLRM。
在这里,我们重点介绍整个 Multislice Training 堆栈中的一些关键组件,其中许多组件我们已经开源,以便继续为更广泛的 AI/ML 社区做出贡献:
1. Accelerated Processing Kit (XPK) 是一个用于与 Google Kubernetes Engine(GKE)配合使用的 ML 集群和作业编排工具,旨在标准化编排 ML 作业的最佳实践。XPK 专注于 ML 语义,用于创建、管理和运行 ML 训练作业,以使 ML 工程师(MLE)更容易使用、管理和调试。XPK 通过单独的 API 将资源配置与作业运行解耦。
2. MaxText 是一个高性能、可扩展和适应性强的 JAX LLM 实现。这个实现基于 Flax、Orbax、和 Optax 等开源 JAX 库构建。MaxText 是一个纯 Python 编写的仅限解码器的 LLM 实现,这使 ML 工程师更容易理解、适应和修改。MaxText 还充分利用了 XLA 编译器,使得 ML 工程师可以在不需要构建自定义内核的情况下轻松实现高性能。通过使用 OpenXLA,XLA 提供了一个开源的 ML 编译器,可以用于 TPU、GPU、CPU 等各种硬件加速器。
3. Accurate Quantized Training (AQT) 是谷歌自建的训练库,它使用精度较低的 8 位整数 (INT8) 代替 16 位浮点数 (BF16) 进行训练。AQT 利用了这样一个事实:使用 INT8 运算时,ML 加速器的计算速度是使用 BF16 运算时的 2 倍。通过使用 AQT 简单灵活的 API,ML 工程师可以在训练过程中获得更高的性能,并在生产环境中获得更高的模型质量。
Google Cloud TPU 在 50,000 多个 TPU v5e 芯片上为大语言模型 (LLM) 运行了全球最大的分布式训练作业
我们使用 Multislice Training 运行了我们认为是全球最大规模的公开披露的 LLM 分布式训练作业(就用于训练的芯片数量而言),该作业在一个由 50,944 个 Cloud TPU v5e 芯片组成的计算集群上运行(跨越 199 个 Cloud TPU v5e pod),能够实现 10 exa-FLOP(16 位)或 20 exa-OP(8 位)的总峰值性能。为了让大家直观地了解规模,这个 Cloud TPU v5e 芯片集群比橡树岭国家实验室 TOP1 超级计算机 Frontier 所使用的 37,888 个 AMD M1250X GPU 还要多。
在 Cloud TPU v5e 上设置 LLM 分布式训练作业
我们在 Cloud TPU v5e 上使用 Cloud TPU Multislice Training 执行了大规模 LLM 分布式训练作业。一个 Cloud TPU v5e pod 由 256 个芯片组成,通过高速的芯片间互连(ICI)进行连接。这些 pod 使用 Google 的 Jupiter 数据中心网络(DCN)进行连接和通信。我们利用 XPK、GKE、MaxText、AQT 和 JAX 训练堆栈的其他组件,在 JAX 框架上设置了这个分布式训练作业。本文的其余部分将重点介绍 Cloud TPU Multislice Training 的 JAX 训练堆栈部分。
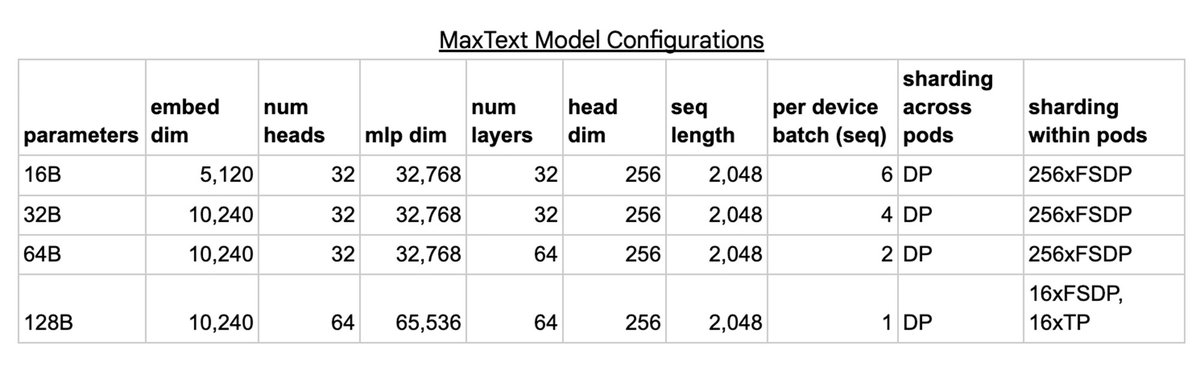
我们训练了多个不同规模的 MaxText 模型,包括 16B、32B、64B 和 128B 参数的模型。对于每个模型,我们使用数据并行(DP)在 DCN 上跨 pod 扩展训练,其中每个 pod 存储各自模型的副本。然后,模型的每个副本在 ICI 上跨 pod 内的芯片上进行分片,使用完全分片的数据并行(FSDP)来处理 16B、32B 和 64B 的配置,使用 FSDP 和张量并行(TP)相结合的方式来处理 128B 的配置。
我们使用 Google Kubernetes Engine(GKE) 来管理 TPU 的容量,并在 GKE 之上利用 XPK 来编排 ML 作业。XPK 负责创建集群,并根据需要调整其大小,将作业以 JobSets 的形式提交到 GKE 的 Kueue 队列系统中,管理这些 JobSet,并提供对集群状态的可视化信息。
为了加速模型训练,我们使用 Accurate Quantized Training (AQT) 库在量化的 INT8 中进行训练。截至 2023 年 10 月,这种方法实现了每秒处理步骤的速度提高了 1.2 倍至 1.4 倍,同时产生的收敛差距小于通常将使用 BF16 训练的模型量化为 INT8 时的收敛差距。
我们如何扩展最大的分布式 LLM 训练作业
随着我们扩展 TPU 计算集群的规模,我们开始挑战堆栈的极限。
编排
管理 50,000 多个加速器芯片参与单个训练作业需要一个精心设计的编排解决方案,它既可以让不同的用户提交较小的作业进行实验,又可以支持在整个集群上运行的大规模作业。这些功能通过 GKE 的 Jobset 和 Kueue 特性提供。随着我们挑战 GKE 能够处理的虚拟机数量极限,我们优化了内部 IP 地址的管理,预缓存了 docker 镜像,设计了可扩展的集群,并实现了高吞吐量的调度。我们还优化了 GKE,以突破虚拟机扩展的限制,例如 pod IP 用尽、域名服务(DNS)的可扩展性以及控制平面节点的限制。我们将这些解决方案与 XPK 进行打包并记录下来,使其成为客户大规模训练的可重复过程。
性能
JAX 由 XLA (加速线性代数)提供支持,XLA 是基于编译器的线性代数执行引擎,可优化 TPU 和 GPU 等 ML 加速器的工作负载,以实现类似超级计算机的性能。XLA 背后的关键并行技术是 SPMD(单程序,多数据),其中相同的计算在不同设备上并行运行。XLA 利用 GSPMD,通过允许用户编写单个巨大的超级计算机程序,然后根据少量的用户注释自动将计算并行化到多个设备上,简化了 SPMD 编程。在大规模运行中,暴露出了只有在有大量切片时才需要进行的优化需求。例如,每个工作节点虚拟机需要通过 DCN 与其他切片中相同等级的工作节点虚拟机进行通信。最初,这会导致由于设备到主机和主机到设备的传输过多造成的速度下降,这些传输的数量随着切片数量的增加呈线性扩展。通过优化 XLA 运行时,我们能够防止这些传输成为瓶颈。
存储
与持久化存储进行交互是训练的一个关键方面。我们的 199 个 Pod 集群具有 1 Tb/s 的与 Google Cloud Storage(GCS)的连接速度,1,270 Tb/s 的切片间数据中心网络(DCN)速度,以及 73,400 Tb/s 的切片内部互连(ICI)速度。在加载 Docker 镜像、加载数据以及读取/写入检查点时,我们优化了与持久化存储的交互。
我们发现,从 64 个 Pod 规模开始,在大规模情况下从 GCS 加载数据开始影响性能。此后,我们采用了一种分布式数据加载策略来缓解对 GCS 的压力,让一部分主机负责加载数据。
我们还发现了检查点机制导致的限制。默认情况下,检查点机制会从 GCS 加载完整的检查点到每个数据并行副本中。考虑一个使用跨 Pod 数据并行的方式对 128B 模型分片进行检查点加载。对于每个参数的传统优化器状态(4 字节/数值),这意味着需要将大约 1.536 TB 大小的检查点分别加载到每个 Pod 中(在此例中为 199 个 Pod)。这将需要 199 个 Pod * 1.536TB/ Pod,总计大约 300TB 的带宽。为了获得 1Tb/s 持久化存储合理的性能,这将需要大约 2,400 秒(40分钟)。然而,我们需要更低的启动或重新启动时间,因此必须采取不同的方法。
为了缓解这个问题,我们添加了一些功能,使单个 pod 能够加载检查点并将其传播到其他副本。因此,单个 pod 可以读取检查点,然后通过利用 JAX 的灵活性将优化器状态传播给其他 pod。原则上,加载检查点需要 1.536TB/1Tb/s=约 12 秒,然后(2*1.536TB/pod)/(64 VM/每个pod*100 Gb/s/VM)=约 4 秒来收集整个集群的优化器状态,总共需要 16 秒,速度提高了 150 倍。同样,在写入检查点数据和加载训练数据时也需要进行优化。在写入时,单个领导者副本可以写入整个检查点,以避免向 GCS 发送过多的 QPS。
我们如何衡量训练性能?
训练性能以模型 FLOPs 利用率(MFU)和有效模型 FLOPs 利用率(EMFU)来衡量。对于一个包含 N 个参数的仅解码器模型,每个观测到的标记需要 6N 个矩阵相乘 FLOPs 用于可学习权重,以及 12LHQT 个矩阵相乘 FLOPs 用于注意力计算,其中 L、H、Q和 T 分别表示层数、头数、头维度和序列长度(详见 PaLM 论文附录 B)。通过了解每个标记所需的 TFLOPs,我们可以将一步的吞吐量表示为观测到的每个芯片每秒 TFLOP 数,计算方法是将每个芯片在该步骤中观测到的所有标记所需的 TFLOPs 总数除以步骤时间。

我们可以通过将观测到的每个芯片每秒的 TFLOP 数除以硬件的每个芯片每秒峰值 TFLOP 数(TPU v5e 为每个芯片每秒 197 TFLOP)来计算 MFU。

EMFU 将观测到的每个芯片每秒的 TFLOP 数扩展为观测到的每个芯片每秒的 TOP 数(每个芯片每秒万亿次运算次数),它包括了量化运算和浮点运算。然而,由于量化运算观测到的每个芯片每秒的 TOP 数可能大于浮点运算的每个芯片每秒的峰值 TFLOP 数,因此可以实现大于 100% 的 EMFU。

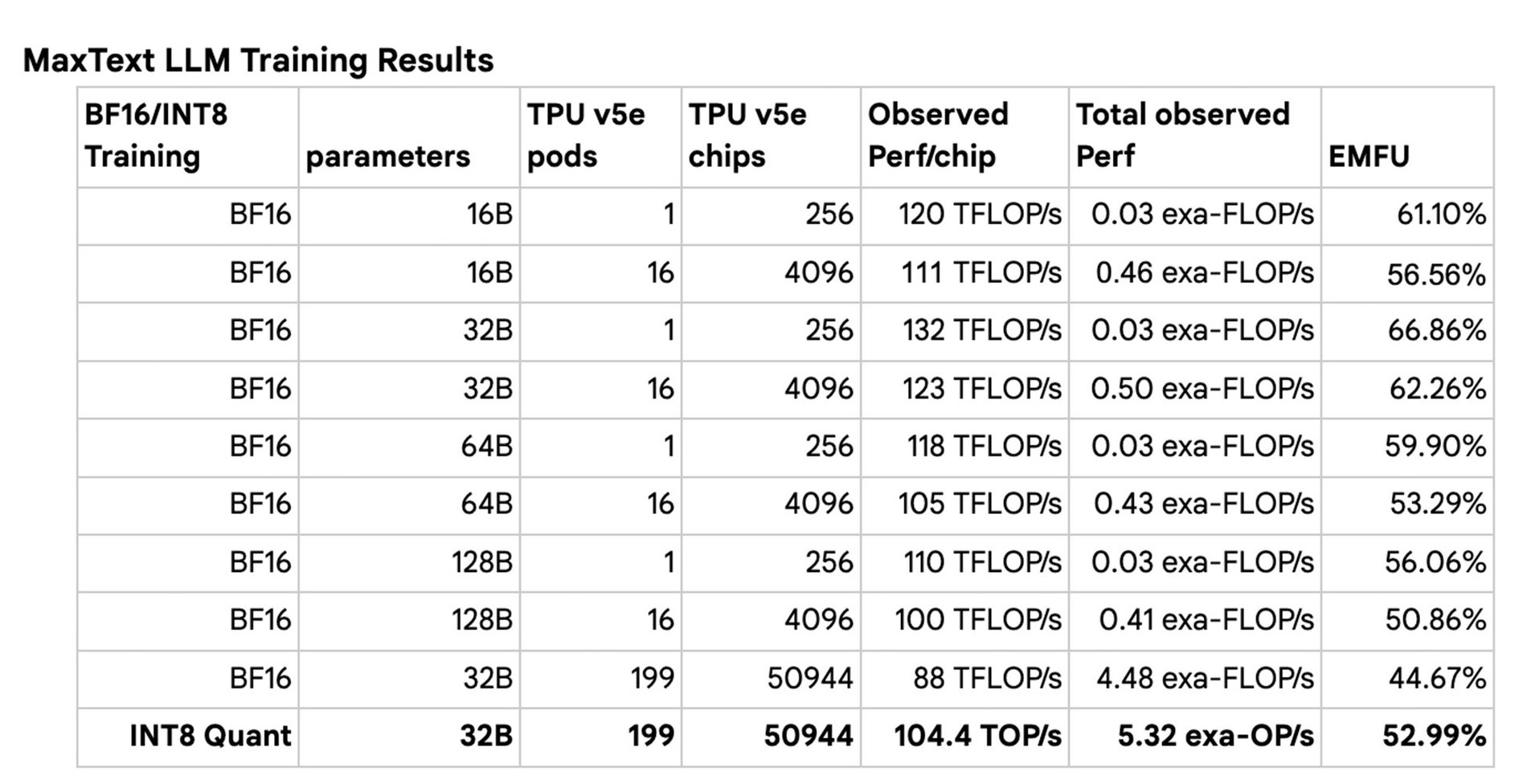
最大的 LLM 分布式训练作业可扩展性结果
对于每个模型尺寸(16B、32B、64B、128B),我们进行了一系列训练作业,将 TPU v5e pod 的数量从 1 个扩展到 160 个。我们发现,在单个 TPU v5e pod 上进行 BF16 训练时,MFU 高达 66.86%,并且在扩展到 160 个 pod 时取得了强大的扩展效果。我们还用 BF16 训练和 INT8 量化训练(使用 AQT)对整个 199 pod 集群进行了训练,用 INT8 量化训练实现了令人瞩目的性能 5.32 exa-OP/s。这项扩展研究是在 Multislice Training JAX 堆栈中使用有限的软件优化完成的,我们将继续改进我们的软件堆栈。
今后的工作
作业启动时间
除了衡量训练性能外,我们还衡量了集群上 ML 作业的启动时间,我们发现该时间与芯片数量几乎呈线性关系。

虽然我们观察到的启动时间令人印象深刻,但我们相信还可以进一步改进。我们正在致力于优化 GKE 中的调度以提高吞吐量,并在 MaxText 中启用提前编译以避免在整个集群上进行即时编译。
扩展效率
我们在 50944 个 TPU v5e 芯片上实现了出色的扩展,但我们相信还可以进一步改进。我们已经确定并正在对编译器和 MaxText 进行更改,以便大规模提高稳定性和性能。我们正在考虑分层式 DCN 集合等可扩展的解决方案,以及进一步优化 multipod 模式中的编译器调度。
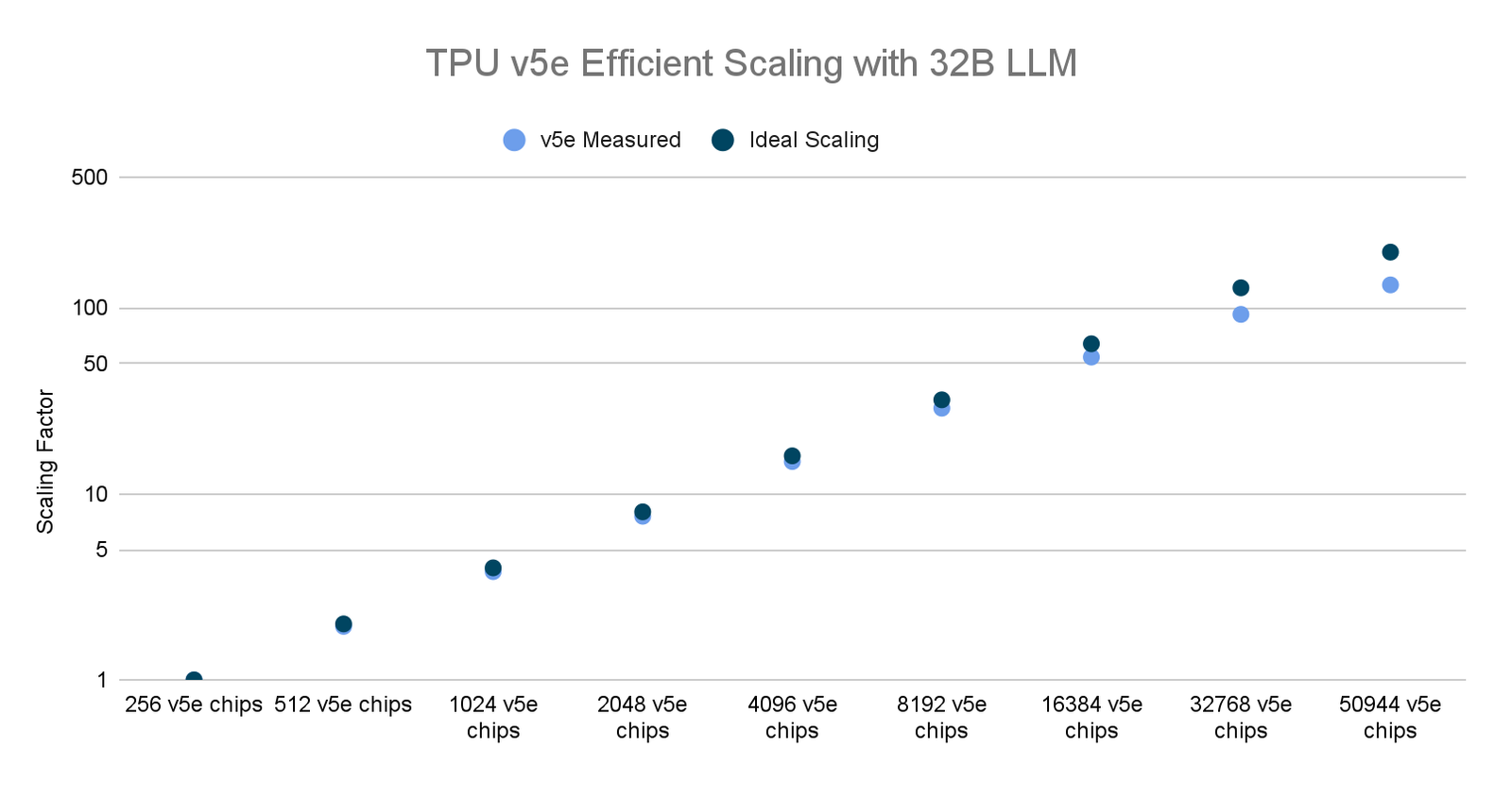
TPU v5e 数据来自截至 2023 年 11 月的 Google 内部数据,针对使用 MaxText 实现的 320 亿参数解码器语言模型的所有数据均按每芯片 seq-len=2048 为单位完成标准化。
结论
Google Cloud TPU Multislice Training 是从头开始构建的,旨在解决分布式 ML 训练在编排、编译和端到端优化方面的挑战。我们通过在一个由 50,944 个 Cloud TPU v5e 芯片组成的计算集群上,使用 JAX ML 框架进行 BF16 和 INT8 量化训练的方式,展示了 Cloud TPU 多片训练的优势。据我们所知,这是世界上公开披露的最大规模的 LLM 分布式训练作业(就用于训练的芯片数量而言)。
随着生成式 AI 继续朝着越来越大的 LLM 发展,我们将继续突破创新的边界,以进一步扩大和改进我们的软件堆栈。我们已经开源了这个项目中使用的所有代码。请查看我们的 MaxText,XPK,AQT 和 XLA 开源存储库。要了解有关 Google Cloud TPU Multislice Training 的更多信息,以及如何将其与 Cloud TPU 结合使用以加速您的生成式 AI 项目,请联系我们。
文章信息
相关推荐
精选内容

关注【谷歌云服务】
微信公众号
微信公众号
微信咨询:
周一至周五 早上 9 点到晚上 6 点
联系我们